Kafka簡介
在大數據中,使用了大量的數據。 關於大數據,主要有兩個主要挑戰。第一個挑戰是如何收集大量數據,第二個挑戰是分析收集的數據。 爲了克服這些挑戰,需要使用消息傳遞系統。
Kafka專爲分佈式高吞吐量系統而設計。 Kafka傾向於非常好地取代傳統的信息中間服務者。 與其他消息傳遞系統相比,Kafka具有更好的吞吐量,內置分區,複製和固有容錯功能,因此非常適合大型消息處理應用程序。
什麼是消息系統?
消息系統負責將數據從一個應用程序傳輸到另一個應用程序,因此應用程序可以專注於數據,但不必擔心如何共享數據。 分佈式消息傳遞基於可靠消息隊列的概念。 消息在客戶端應用程序和消息傳遞系統之間異步排隊。 有兩種類型的消息傳遞模式可用 - 一種是點對點的,另一種是發佈 - 訂閱(pub-sub)消息傳遞系統。 大多數消息傳遞模式遵循pub-sub。
點對點消息系統
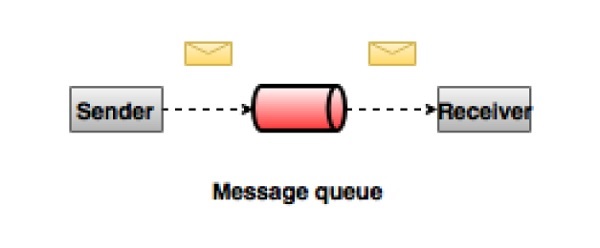
在點對點系統中,消息被保存在一個隊列中。 一個或多個消費者可以消費隊列中的消息,但是特定的消息只能由最多一個消費者消費。 一旦消費者在隊列中讀取消息,消息就從該隊列中消失。 這個系統的典型例子是一個訂單處理系統,其中每個訂單將由一個訂單處理器處理,但是多訂單處理器也可以同時工作。 下圖描述了結構。
發佈-訂閱消息系統
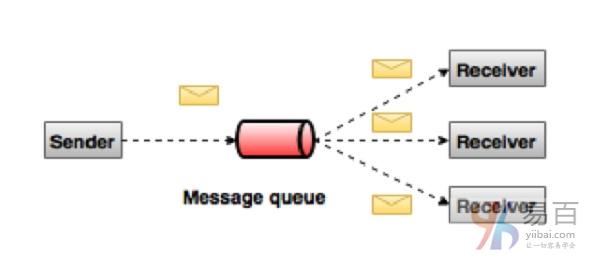
在發佈-訂閱系統中,消息被保存在一個主題中。 與點對點系統不同,消費者可以訂閱一個或多個主題並使用該主題中的所有消息。 在發佈-訂閱系統中,消息生產者稱爲發佈者,消息消費者稱爲訂閱者。 一個真實的例子是Dish TV,它發佈體育,電影,音樂等不同的頻道,任何人都可以訂閱他們自己的一套頻道,並在他們的訂閱頻道可用時獲得內容。
什麼是Kafka?
Apache Kafka是一個分佈式的發佈 - 訂閱消息傳遞系統和一個強大的隊列,可以處理大量的數據,並使您能夠將消息從一個端點傳遞到另一個端點。 Kafka適合離線和在線消息消費。 Kafka消息被保存在磁盤上並在集羣內複製以防止數據丟失。 Kafka建立在ZooKeeper同步服務之上。 它與Apache Storm和Spark完美集成,用於實時流數據分析。
優點
以下是使用Kafka的一些好處(優點) -
- 可靠性 - 卡夫卡是分佈式,分區,複製和容錯。
- 可擴展性 - Kafka消息系統無需停機即可輕鬆擴展。
- 耐用性 - Kafka使用分佈式提交日誌,這意味着消息儘可能快地保留在磁盤上,因此它是持久的。
- 性能 - Kafka對於發佈和訂閱消息都有很高的吞吐量。 它保持穩定的性能,即使存儲了許多TB數據量(級)的消息。
Kafka速度非常快,可確保零停機時間和零數據丟失。
用例
Kafka可用於許多用例。 其中一些列在下面 -
- 指標 - Kafka通常用於運營監控數據。 這涉及從分佈式應用程序彙總統計數據以生成操作數據的集中式提要。
- 日誌聚合解決方案 - Kafka可以在整個組織中使用,從多個服務中收集日誌,並以標準格式向多個消費者提供。
- 流處理 - 流行的框架(如Storm和Spark Streaming)可以從主題讀取數據,對其進行處理,並將處理後的數據寫入新主題,以供用戶和應用程序使用。 Kafka的強耐久性在流加工方面也非常有用。
Kafka是處理所有實時數據饋送的統一平臺。 Kafka支持低延遲消息傳送並在出現機器故障時保證容錯。 它有能力處理大量不同的消費者。 Kafka速度非常快,每秒執行200萬次寫入。 Kafka將所有數據保留在磁盤上,這意味着所有寫入都會進入操作系統(RAM)的頁面緩存。 這使得從頁面緩存向網絡套接字傳輸數據非常高效。