Kafka基本原理
在深入學習Kafka之前,需要先了解topics, brokers, producers和consumers等幾個主要術語。 下面說明了主要術語的詳細描述和組件。
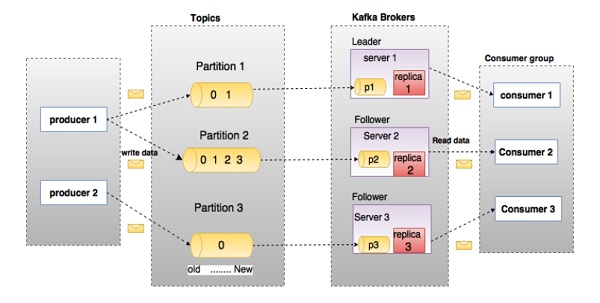
在上圖中,主題(topic)被配置爲三個分區。 分區1(Partition 1)具有兩個偏移因子0和1。分區2(Partition 2)具有四個偏移因子0,1,2和3,分區3(Partition 3)具有一個偏移因子0。replica 的id與託管它的服務器的id相同。
假設,如果該主題的複製因子設置爲3,則Kafka將爲每個分區創建3個相同的副本,並將它們放入羣集中以使其可用於其所有操作。 爲了平衡集羣中的負載,每個代理存儲一個或多個這些分區。 多個生產者和消費者可以同時發佈和檢索消息。
Topics - 屬於特定類別的消息流被稱爲主題(Topics),數據存儲在主題中。主題分爲多個分區。 對於每個主題,Kafka都保留一個分區的最小範圍。 每個這樣的分區都以不可變的有序順序包含消息。 分區被實現爲一組相同大小的段文件。
Partition - 主題可能有很多分區,所以它可以處理任意數量的數據。
Partition offset - 每個分區消息都有一個稱爲偏移量的唯一序列標識。
Replicas of partition - 副本只是分區的備份。 副本從不讀取或寫入數據。 它們用於防止數據丟失。
Brokers
- 經紀人(Brokers)是簡單的系統,負責維護公佈的數據。 每個代理可能每個主題有零個或多個分區。 假設,如果一個主題和
N個代理中有N個分區,則每個代理將有一個分區。 - 假設某個主題中有N個分區並且N個代理(n + m)多於N個,則第一個N代理將擁有一個分區,下一個M代理將不會擁有該特定主題的任何分區。
- 假設某個主題中有N個分區且N個代理(n-m)少於N個代理,則每個代理將擁有一個或多個分區共享。 由於經紀人之間的負載分配不均衡,不推薦這種情況。
- 經紀人(Brokers)是簡單的系統,負責維護公佈的數據。 每個代理可能每個主題有零個或多個分區。 假設,如果一個主題和
Kafka Cluster - Kafka擁有多個經紀人稱爲Kafka集羣。 Kafka集羣可以在無需停機的情況下進行擴展。 這些集羣用於管理消息數據的持久性和複製。
Producers - 生產者(Producer)是一個或多個Kafka主題的發佈者。 生產者向Kafka經紀人發送數據。 每當生產者向經紀人發佈消息時,經紀人只需將消息附加到最後一個段文件。 實際上,該消息將被附加到分區。 生產者也可以將消息發送到他們選擇的分區。
Consumers - 消費者從經紀人那裏讀取數據。 消費者通過從經紀人處獲取數據來訂閱一個或多個主題並消費發佈的消息。
Leader - Leader是負責所有分區讀寫的節點。 每個分區都有一臺服務器充當領導者。
Follower - 遵循領導者(Leader)指示的節點稱爲追隨者(Follower)。 如果領導失敗,其中一個追隨者將自動成爲新領導。 追隨者扮演正常的消費者角色,拉動消息並更新自己的數據存儲。