Lucene第一個應用程序
讓我們使用Lucene框架做實際編程。在開始使用Lucene框架編寫第一個例子之前,必須確保已經安裝Lucene的環境正常。也假設有一點點的工作和Eclipse IDE的知識。
因此,開始寫一個簡單的搜索應用程序將打印找到搜索結果數量。我們也看到在這個過程中創建的索引列表。
第1步 - 創建Java項目:
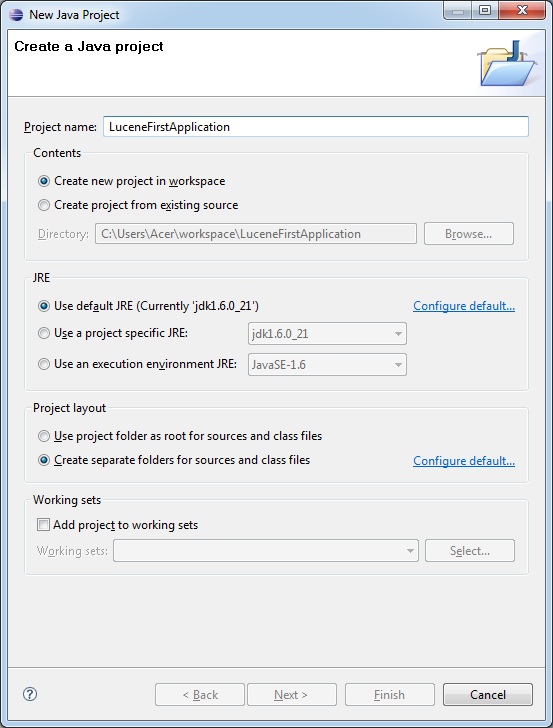
第一步是使用Eclipse IDE創建一個簡單的Java項目。按照選項 File -> New -> Project 最後選擇 Java Project 從嚮導列表嚮導。現在,項目命名爲 LuceneFirstApplication 使用嚮導窗口,如下所示:
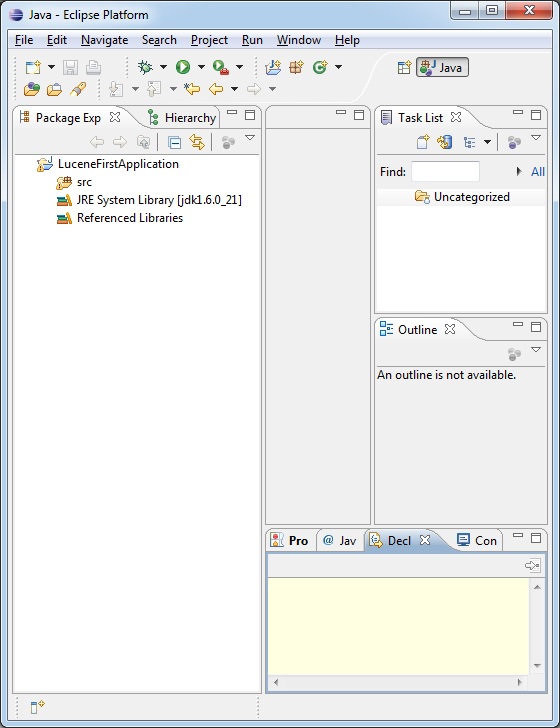
一旦項目成功創建,將有以下內容在 Project Explorer:
第2步 - 添加必需的庫:
作爲第二步,我們添加Lucene核心框架庫在項目中。要做到這一點,右鍵單擊項目名稱LuceneFirstApplication然後按照上下文菜單中提供以下選項:Build Path -> Configure Build Path,顯示了Java構建路徑如下窗口:
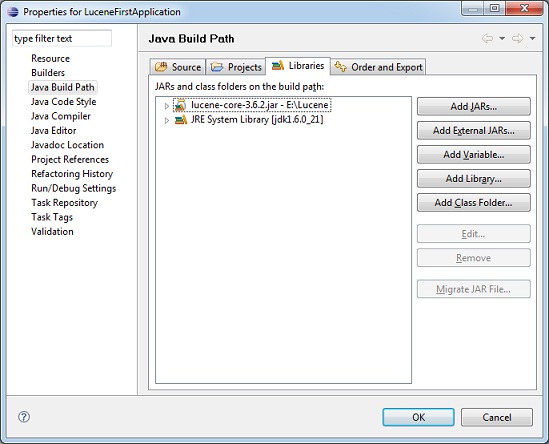
現在,使用添加在庫選項卡中提供外部JAR按鈕,添加Lucene安裝目錄下的核心JAR:
- lucene-core-3.6.2
第3步 - 創建源文件:
現在,讓我們 LuceneFirstApplication 項目下創建實際的源文件。首先,我們需要創建一個名爲 com.yiibai.lucene 包。要做到這一點,右鍵單擊 src 在包資源管理部分,並按照選項:New -> Package.
下一步,我們將創建 LuceneTester.java 和 其他Java類在 com.yiibai.lucene 包下。
LuceneConstants.java
這個類是用來提供跨示例應用程序中使用的各種常量。
package com.yiibai.lucene; public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10; }
TextFileFilter.java
此類用於爲 .txt 文件過濾器
package com.yiibai.lucene; import java.io.File; import java.io.FileFilter; public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); } }
Indexer.java
這個類是用於索引的原始數據,這樣我們就可以使用Lucene庫,使其可搜索。
package com.yiibai.lucene; import java.io.File; import java.io.FileFilter; import java.io.FileReader; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class Indexer { private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); } public void close() throws CorruptIndexException, IOException{ writer.close(); } private Document getDocument(File file) throws IOException{ Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(), Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(), Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; } private void indexFile(File file) throws IOException{ System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document); } public int createIndex(String dataDirPath, FileFilter filter) throws IOException{ //get all files in the data directory File[] files = new File(dataDirPath).listFiles(); for (File file : files) { if(!file.isDirectory() && !file.isHidden() && file.exists() && file.canRead() && filter.accept(file) ){ indexFile(file); } } return writer.numDocs(); } }
Searcher.java
這個類是用來搜索索引所創建的索引搜索請求的內容。
package com.yiibai.lucene; import java.io.File; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.queryParser.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); } }
LuceneTester.java
這個類是用來測試 Lucene 庫的索引和搜索功能。
package com.yiibai.lucene; import java.io.IOException; import org.apache.lucene.document.Document; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; public class LuceneTester { String indexDir = "E:\Lucene\Index"; String dataDir = "E:\Lucene\Data"; Indexer indexer; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.createIndex(); tester.search("Mohan"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void createIndex() throws IOException{ indexer = new Indexer(indexDir); int numIndexed; long startTime = System.currentTimeMillis(); numIndexed = indexer.createIndex(dataDir, new TextFileFilter()); long endTime = System.currentTimeMillis(); indexer.close(); System.out.println(numIndexed+" File indexed, time taken: " +(endTime-startTime)+" ms"); } private void search(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); TopDocs hits = searcher.search(searchQuery); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime)); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: " + doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); } }
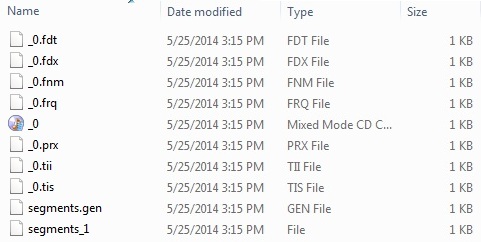
第4步- 創建數據和索引目錄
把 record1.txt 任命爲 record10.txt 包含簡單的名稱以及學生的其他數據信息,並把它們放在目錄:E:LuceneData 並測試數據。索引目錄路徑應創建在 E:LuceneIndex。運行此程序後,就可以看到該文件夾中創建的索引文件的列表。
第5步 - 運行程序:
一旦完成創建源和原始數據,數據目錄和索引目錄,下一步是編譯和運行程序。要做到這一點,請LuceneTester.Java文件的活動選項卡中使用EclipseIDE可無論是運行選項,或使用Ctrl+ F11來編譯和運行應用程序LuceneTester。如果一切正常您的應用程序,這將打印在 Eclipse IDE 控制檯以下消息:
Indexing E:LuceneData
ecord1.txt
Indexing E:LuceneData
ecord10.txt
Indexing E:LuceneData
ecord2.txt
Indexing E:LuceneData
ecord3.txt
Indexing E:LuceneData
ecord4.txt
Indexing E:LuceneData
ecord5.txt
Indexing E:LuceneData
ecord6.txt
Indexing E:LuceneData
ecord7.txt
Indexing E:LuceneData
ecord8.txt
Indexing E:LuceneData
ecord9.txt
10 File indexed, time taken: 109 ms
1 documents found. Time :0
File: E:LuceneData
ecord4.txt
一旦已經成功地運行程序,將有以下的索引目錄中的內容: