數據挖掘 - 挖掘互聯網
萬維網包含了龐大的信息,如超鏈接信息,網頁訪問信息,教育等,提供用於數據挖掘豐富來源。
Web挖掘的挑戰
在網絡構成的基礎上,以下意見供資源和知識發現的巨大挑戰:
該網站是過於龐大 - 對纖維網的大小是非常巨大和迅速增加。這似乎是網絡過於龐大的數據倉庫和數據挖掘。
Web頁面的複雜性 - 該網頁並沒有統一的結構。相對於傳統的文本文檔,他們是非常複雜的。有在網絡的數字圖書館大量的文件。根據在任何特定的排序順序這些庫沒有安排。
網絡是動態的信息源 - 在網絡上的信息被迅速更新。數據如新聞,股市,天氣,體育,購物等會定期更新。
用戶羣體的多樣性 - 在網絡上的用戶羣體正在迅速擴大。這些用戶有不同的背景,興趣,以及使用目的。但是也有一些連接到互聯網,仍然迅速增加超過1億的工作站。
信息的相關性 - 可以認爲,一個特定的人通常是感興趣的網頁只有一小部分,而腹板的部分的其餘部分包含的是不相關的用戶和可能淹沒想要的結果的信息。
挖掘Web頁面佈局結構
網頁的基本結構是基於文檔對象模型(DOM)。 DOM結構指狀結構樹。在這種結構中的頁的HTML標籤對應於DOM樹中的節點。我們可以分段使用預先定義的標籤的HTML網頁。在HTML的語法很靈活,因此,網頁不遵循W3C規範。不遵循W3C的規範可能在DOM樹結構導致錯誤。
DOM結構最初被引入供呈現在瀏覽器中不爲所述網頁的語義結構的描述。 DOM結構不能正確識別網頁的不同部分之間的語義關係。
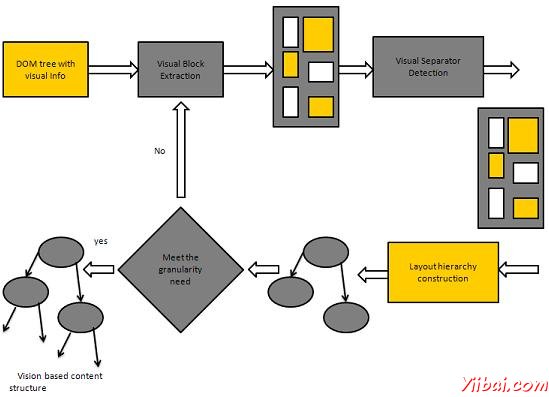
基於視覺的網頁分塊(VIPS)
VIPS的目的是提取網頁的基礎上它的視覺呈現的語義結構。
這樣的一個語義結構對應於樹結構。在這個樹中的每個節點對應一個塊。
值被分配給每個節點。這個值被稱爲相干度。這個值被分配以指示如何相干是基於視覺感知的塊中的內容。
在VIPS算法首先提取從HTML DOM樹中的所有合適的塊。之後,它發現這些塊之間的分隔符。
分離器是指在網頁中的水平線或垂直線在視覺上沒有塊交叉。
該網頁的語義構造這些塊的基礎上。
下圖顯示的VIPS算法的程序: