Zookeeper工作流
當ZooKeeper集合啓動時,它會等待客戶端連接。客戶端將連接到ZooKeeper的集合的其中一個節點。它可能是一個領導者或跟隨者節點。當客戶機連接時,該節點分配會話ID給特定的客戶端,併發送一個確認消息給客戶端。如果客戶端沒有得到確認,它會嘗試連接ZooKeeper集合的另一個節點。當連接到一個節點後,客戶端將以規則的間隔發送心跳到節點,以確保連接不會丟失。
如果客戶想要讀取特定的znode,它發送一個讀請求使用znode路徑的節點,所述節點從其自己的數據庫中獲取它返回所請求的znode。出於這個原因,讀取在動物園管理員集合中速度非常快。
如果客戶希望將數據存儲在ZooKeeper 集合,它發送znode路徑和數據到服務器。連接的服務器將請求轉發到領導者,那麼領導者將重新發出書面請求到所有的追隨者。如果只有一個數節點成功響應,接着寫請求將成功及一個成功的返回代碼將被髮送到客戶端。否則,寫請求將失敗。嚴格大部分節點被稱爲定額。
ZooKeeper集合的節點
讓我們來分析ZooKeeper集合不同數量的節點的作用。
如果我們有一個節點,那麼當該節點出現故障時ZooKeeper集合失敗。它有利於「單一失敗教程」,它不建議用在生產環境中。
如果我們有兩個節點,一個節點出現故障,我們也沒有「多數」,因爲二分之一併不是一個大多數。
如果我們有三個節點及其一個節點發生故障,我們有大多數,因此它是最低要求。它強制 ZooKeeper 集合在實際生產環境中至少有三個節點。
如果我們有四個節點及其有當兩個節點失敗,它類似於有三個節點。額外的節點沒有任何作用,因此,最好是單數增加節點,例如,3, 5, 7.
我們知道,寫處理它比在 ZooKeeper 集合讀過程是昂貴的,由於所有的節點需要寫相同的數據在其數據庫中。因此,最好是具有節點(3,5或7)比具有大量節點的一個平衡的環境的數量少。
下圖描述了ZooKeeper 的工作流程以及在隨後的表說明了其不同的組件。
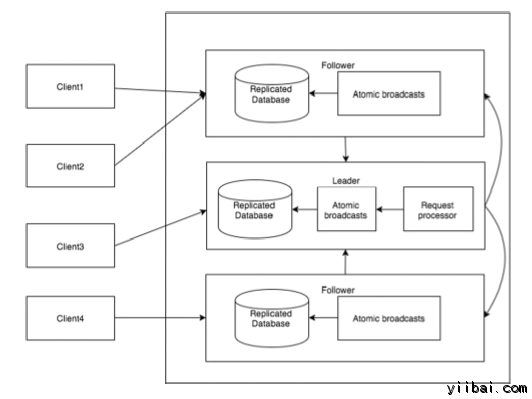
組件
描述
寫入
寫過程是由領導節點處理。領導者轉發寫請求到所有znodes及其等待來自znodes應答。如果一半的znodes的回覆,那麼寫入過程就完成了。
讀取
讀取在內部由特定連接znode進行的,所以沒有必要與集羣交互。
複製數據庫
它是用來將數據存儲在zookeeper。每個znode都有自己的數據庫及其每個znode 在一致性的作用下,每次有相同的數據。
領導者(節點)
領導者是由Znode負責處理寫請求。
追隨者(節點)
追隨者收到來自客戶端的寫請求,並將其轉發到領導znode。
請求處理器
目前僅在領導節點。它從跟隨節點的請求支配寫入。
原子廣播
負責從領導節點到從節點廣播更改。