RDD共享變量
在Spark中,當任何函數傳遞給轉換操作時,它將在遠程集羣節點上執行。它適用於函數中使用的所有變量的不同副本。這些變量將複製到每臺計算機,並且遠程計算機上的變量更新不會恢復到驅動程序。
廣播變量
廣播變量支持在每臺機器上緩存的只讀變量,而不是提供任務的副本。Spark使用廣播算法來分發廣播變量以降低通信成本。
spark動作的執行經過幾個階段,由分佈式「shuffle」操作分開。Spark自動廣播每個階段中任務所需的公共數據。以這種方式廣播的數據以序列化形式緩存並在運行每個任務之前反序列化。
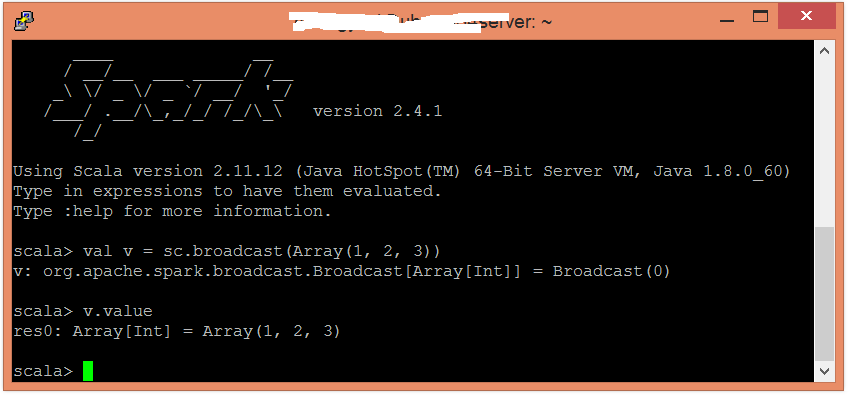
要創建廣播變量(比方說,v),請調用SparkContext.broadcast(v)。讓我們通過一個例子來理解。
scala> val a=sc.longAccumulator("Accumulator")
scala> sc.parallelize(Array(2,5)).foreach(x=>a.add(x))
scala> a.value
累加器
累加器是用於執行關聯和交換操作(例如計數器或總和)的變量。Spark爲數字類型的累加器提供支持。但是,可以添加對新類型的支持。
要創建數字累加器,請調用SparkContext.longAccumulator()或SparkContext.doubleAccumulator()以累積Long或Double類型的值。
示例
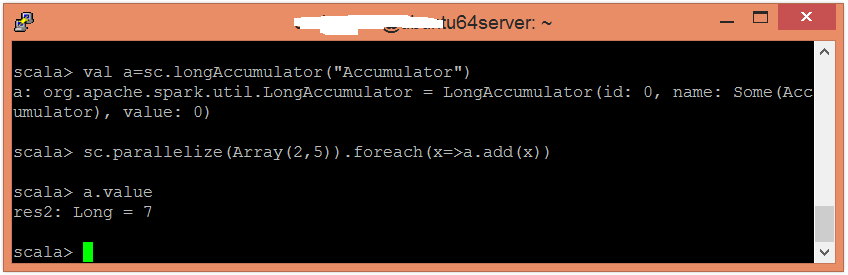
scala> val a=sc.longAccumulator("Accumulator")
scala> sc.parallelize(Array(2,5)).foreach(x=>a.add(x))
scala> a.value