Apache Spark RDD
彈性分佈式數據集
彈性分佈式數據集(RDD)是Spark的基本數據結構。它是對象的不可變的分佈式集合。在RDD中每個數據集被劃分成邏輯分區,這可能是在羣集中的不同節點上計算的。RDDS可以包含任何類型,如:Python,Java,或者Scala的對象,包括用戶定義的類。
形式上,一個RDD是隻讀的,分割的記錄集。RDDs 可以數據創建通過確定運算在穩定的存儲或其他RDDs 。RDD是可以並行進行操作元素的容錯集合。
有兩種方法來創建RDDs − 並行現有集合中的驅動器程序,或在外部存儲系統引用的數據集,如共享文件系統,HDFS,HBase,或任何數據源提供Hadoop的輸入格式。
Spark利用RDD概念,以實現更快,更高效的MapReduce作業。讓我們先討論MapReduce如何操作,爲什麼不那麼有效。
數據共享是緩慢的MapReduce
MapReduce被廣泛用於處理和生成大型數據集並行,分佈在集羣上的算法。它允許用戶編寫並行計算,使用一組高層次的操作符,而不必擔心工作分配和容錯能力。
遺憾的是,目前大多數的框架,只有這樣,才能重新使用計算(前 - 兩個MapReduce工作之間)之間的數據是將其寫入到一個穩定的外部存儲系統(前- HDFS)。雖然這個框架提供了大量的抽象訪問羣集的計算資源,但用戶還是想要更多。
這兩個迭代和互動應用需要跨並行作業更快速的數據共享。數據共享MapReduce是緩慢的,因爲複製,序列化和磁盤IO。在存儲系統中,大多數的 Hadoop 應用,它們花費的時間的90%以上是用於做HDFS讀 - 寫操作。
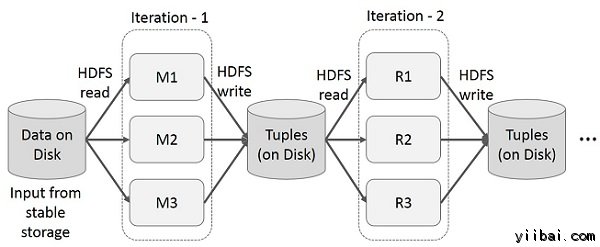
MapReduce的迭代操作
重複使用多個計算中間結果在多級的應用程序。下圖說明了如何在當前的框架工作,同時做迭代操作上的MapReduce。這會帶來大量的開銷,由於數據複製,磁盤I / O,和系列化,使系統變慢。
MapReduce的交互式操作
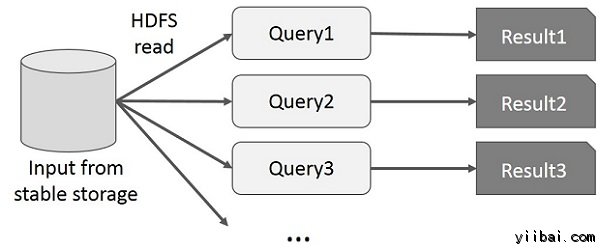
用戶運行即席查詢,數據的相同子集。每個查詢會做穩定存儲,它可以主宰應用程序執行的磁盤I/O時間。
下圖說明了如何在當前的框架工作同時做交互查詢在MapReduce上。
使用Spark RDD數據共享
數據共享MapReduce是緩慢的,因爲複製,序列化和磁盤IO。大多數的Hadoop應用,他們花費的時間的90%以上是做HDFS讀 - 寫操作。
認識到這個問題,研究人員專門開發了一種稱爲Apache Spark框架。spark的核心思想是彈性分佈式數據集(RDD); 它支持在內存中處理運算。這意味着,它存儲存儲器的狀態作爲兩端作業的對象以及對象在那些作業之間是可共享的。在存儲器數據共享比網絡和磁盤快10到100倍。
現在讓我們理解迭代和交互式操作是如何發生在Spark RDD中。
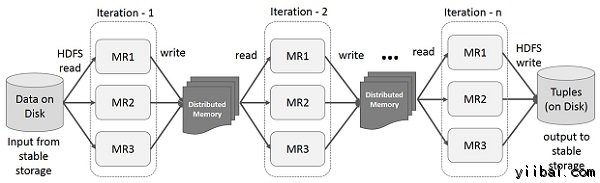
Spark RDD迭代操作
下面給出的圖顯示Spark RDD迭代操作。它將存儲中間結果放在分佈式存儲器,而不是穩定的存儲(磁盤)和使系統更快。
注 − 如果分佈式存儲器(RAM)足以存儲中間結果(該作業狀態),那麼它將存儲這些結果的磁盤上。
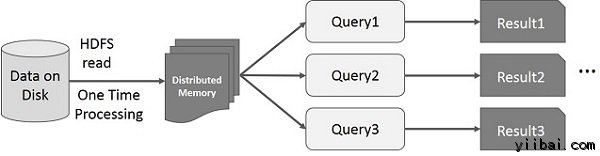
Spark RDD交互式操作
該圖顯示Spark RDD的交互式操作。如果不同查詢在同一組數據的反覆運行,該特定數據可被保存在內存中以獲得更好的執行時間。
默認情況下,每個變換RDD可以在每次運行在其上的動作時間重新計算。但是,也可能會持續一個RDD在內存中,在這種情況下,Spark將保持周圍羣集上以獲得非常快速訪問,在你查詢它的下一次用上。另外也用於在磁盤上持續RDDS支持,或在多個節點間複製。