併發vs並行
併發性和並行性都用於多線程程序,但它們之間的相似性和差異存在很多混淆。 在這方面的一個大問題是:併發是不是就是並行? 雖然這兩個術語看起來很相似,但對上述問題的答案是否定的,併發性和並行性並不相同。 現在,如果它們不一樣,它們之間的基本區別是什麼?
簡而言之,併發處理的是處理來自不同線程的共享狀態訪問,而並行處理利用多個CPU或其內核來提高硬件性能。
併發簡介
併發是兩個任務在執行過程中重疊的時候。 這可能是一個應用程序正在同時處理多個任務的情況。 我們可以用圖解理解它; 多項任務正在同時取得進展,如下所示 -
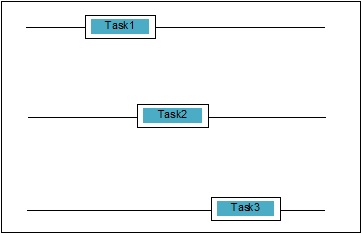
併發級別
在本節中,我們將討論編程方面的三個重要級別的併發性 -
1. 低級併發
在這種併發級別中,顯式使用了原子操作。 我們不能在構建應用程序時使用這種併發性,因爲它非常容易出錯並且很難調試。 即使Python不支持這種併發性。
2. 中級併發
在這種併發中,沒有使用顯式的原子操作。 它使用顯式鎖。 Python和其他編程語言支持這種併發性。 大多數應用程序員使用這種併發性。
3. 高級併發
在這種併發中,不使用顯式原子操作也不使用顯式鎖。 Python有concurrent.futures模塊來支持這種併發。
併發系統的性質
要使程序或併發系統正確,一些屬性必須由它來滿足。 與終止系統相關的屬性如下 -
正確性屬性
正確性屬性意味着程序或系統必須提供所需的正確答案。 爲了簡單起見,可以說系統必須正確地將啓動程序狀態映射到最終狀態。
安全屬性
安全屬性意味着程序或系統必須保持「良好」或「安全」狀態,並且從不做任何「壞」的事情。
活躍度屬性
這個屬性意味着一個程序或系統必須「取得進展」,並且會達到一個理想的狀態。
併發系統的行爲者
這是併發系統的一個常見屬性,其中可以有多個進程和線程,它們同時運行以在他們自己的任務上取得進展。 這些進程和線程稱爲併發系統的角色。
併發系統的資源
行爲者必須利用內存,磁盤,打印機等資源來執行任務。
某些規則集
每個併發系統必須擁有一套規則來定義執行者要執行的任務類型和每個任務的執行時間。 任務可能是獲取鎖,共享內存,修改狀態等。
併發系統的障礙
在實現併發系統時,程序員必須考慮以下兩個重要問題,這可能是併發系統的障礙 -
共享數據
實現併發系統時的一個重要問題是在多個線程或進程間共享數據。 實際上,程序員必須確保鎖保護共享數據,以便所有對它的訪問都被序列化,並且一次只有一個線程或進程可以訪問共享數據。 如果多個線程或進程都試圖訪問相同的共享數據,那麼除了其中至少一個以外,其他所有進程都將被阻塞並保持空閒狀態。 換句話說,在鎖定生效時,我們只能使用一個進程或線程。 可以有一些簡單的解決方案來消除上述障礙 -
數據共享限制
最簡單的解決方案是不共享任何可變數據。 在這種情況下,我們不需要使用顯式鎖定,並且可以解決由於相互數據而導致的併發障礙。
數據結構協助
很多時候併發進程需要同時訪問相同的數據。 與使用顯式鎖相比,另一種解決方案是使用支持併發訪問的數據結構。 例如,可以使用提供線程安全隊列的隊列模塊。 也可以使用multiprocessing.JoinableQueue類來實現基於多處理的併發。
不可變的數據傳輸
有時,我們使用的數據結構(比如說併發隊列)不適合,那麼可以傳遞不可變數據而不鎖定它。
可變數據傳輸
繼續上面的解決方案,假設如果它只需要傳遞可變數據而不是不可變數據,那麼可以傳遞只讀的可變數據。
共享I/O資源
實現併發系統的另一個重要問題是線程或進程使用I/O資源。 當一個線程或進程使用I/O很長時間而另一線程或進程閒置時會出現問題。 在處理I/O大量應用程序時,我們可以看到這種障礙。 可以通過一個例子來理解,從Web瀏覽器請求頁面。 這是一個沉重的應用程序。 在這裏,如果數據請求的速率比它消耗的速率慢,那麼在併發系統中就會有I/O障礙。
以下Python腳本用於請求網頁並獲取網絡用於獲取請求頁面的時間 -
import urllib.request
import time
ts = time.time()
req = urllib.request.urlopen('http://www.yiibai.com')
pageHtml = req.read()
te = time.time()
print("Page Fetching Time : {} Seconds".format (te-ts))執行上述腳本後,可以獲取頁面獲取時間,如下所示。
Page Fetching Time: 0.999139881798332 Seconds可以看到,獲取該頁面的時間差不多是一秒鐘。 現在,如果我們想要訪問數千個不同的網頁,您可以大概知道訪問網絡需要多少時間。
什麼是並行性?
並行可定義爲將任務分解爲可同時處理的子任務的技術。 如上所述,它與併發性相反,其中兩個或更多事件同時發生。 我們可以用圖解理解它; 一個任務被分解成可以並行處理的多個子任務,如下所示 -
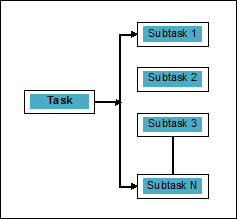
並行但不平行
應用程序可以是並行的,但不是並行的,意味着它可以同時處理多個任務,但任務不會分解爲子任務。
並行但不併發
一個應用程序可以是並行的,但不是並行的,意味着它一次只能在一個任務上工作,並且分解爲子任務的任務可以並行處理。
既不平行也不併發
應用程序既不能並行也不能併發。 這意味着它一次只能處理一項任務,並且任務不會被分解爲子任務。
並行和併發
應用程序既可以是並行的,也可以是並行的,這意味着它既可以同時在多個任務上工作,也可以將任務分解爲子任務並行執行。
並行的必要性
我們可以通過在單CPU的不同內核之間或網絡內連接的多臺計算機之間分配子任務來實現並行。
考慮以下要點來理解爲什麼有必要實現並行性 -
有效的代碼執行
藉助並行性,我們可以高效地運行代碼。 它將節省時間,因爲部分中的相同代碼並行運行。
比順序計算更快速
順序計算受到物理和實際因素的限制,因此無法獲得更快的計算結果。 另一方面,這個問題可以通過並行計算來解決,並且比順序計算提供更快的計算結果。
執行時間更短
並行處理減少了程序代碼的執行時間。
如果要談論真實生活中並行性的例子,我們計算機的圖形卡就是一個例子,它強調了並行處理的真正能力,因爲它擁有數百個獨立工作的獨立處理內核,並且可以同時執行。 由於這個原因,我們也能夠運行高端應用程序和遊戲。
理解處理器的實現
我們知道併發性,並行性以及它們之間的差異,但是它將如何實現。 理解將要實施的系統是非常必要的,因爲它使我們在設計軟件時能夠做出明智的決定。有以下兩種處理器 -
單核處理器
單核處理器能夠在任何給定時間執行一個線程。 這些處理器使用上下文切換來在特定時間存儲線程的所有必要信息,然後再恢復信息。 上下文切換機制有助於我們在給定秒內的多個線程上取得進展,並且看起來好像系統正在處理多種事情。
單核處理器具有許多優點。 這些處理器需要更少的功率,並且多個內核之間沒有複雜的通信協議。 另一方面,單核處理器的速度有限,不適合更大的應用。
多核處理器
多核處理器具有多個獨立處理單元,也稱爲核心。
這種處理器不需要上下文切換機制,因爲每個核心都包含執行一系列存儲指令所需的所有內容。
讀取 - 解碼 - 執行的週期
多核處理器的內核遵循一個執行週期。 這個週期被稱爲讀取 - 解碼 - 執行週期。 它涉及以下步驟 -
讀取
這是循環的第一步,它涉及從程序存儲器讀取指令。
解碼
最近讀取的指令將被轉換爲一系列觸發CPU其他部分的信號。
執行
這是獲取和解碼指令將被執行的最後一步。 執行結果將存儲在CPU寄存器中。
這裏的一個優勢是多核處理器的執行速度比單核處理器的執行速度快。 它適用於更大的應用程序。 另一方面,多核之間的複雜通信協議是一個問題。 多核需要比單核處理器需要更多的功率。