使用 Spring AI 建置高效能代理
1.概述
Anthropic 最近發布了一份關於如何建立有效 AI 代理的出版物。在這份文件中,他們提出了一些代理模式,供軟體開發人員遵循,並作為良好實踐。他們還聲稱,我們可以用它們來取代複雜的框架。然而,現實情況是,在 Java 生態系統中,我們確實到處使用大型框架,例如 Spring。
儘管 Spring 是一個龐大而複雜的框架,但它提供了簡化使用 Spring AI 創建有效代理的工具。
在本文中,我們將回顧出版物中提出的模式以及一些關鍵定義,以確保清晰易懂。然後,我們將使用 Spring AI 實作這些模式。由於重點在於模式的實現,因此我們不會討論如何與實際的模型宿主整合。
2. 使用 Spring AI 建置高效能代理
在與數十個跨行業團隊合作建立 LLM 代理程式之後,Anthropic 提出了一些簡單且可組合的模式。但首先,讓我們先澄清一下他們在出版物中使用的兩個概念:
- 代理是一種系統,其中 LLM 動態地指導自己的流程和工具使用,從而控制它們如何完成任務
- 工作流程是透過預先定義程式碼路徑協調 LLM 和工具的系統
考慮到這一點,提出的模式是:
- 提示鏈工作流程將複雜的任務分解為一系列步驟,每個 LLM 提示的輸出作為後續 LLM 提示的輸入
- 並行化工作流程支援同時處理多個 LLM 操作,並以程式設計方式聚合其輸出
- 路由工作流程根據內容分類驅動輸入到專門處理程序的智慧路由
- Orchestrator-Workers 工作流程,其中中央 LLM 分解任務,將其委派給工作 LLM,並將其結果合併為最終回應
- 評估器-優化器工作流程,其中一個 LLM 產生結果,而另一個 LLM 循環提供評估和回饋
3.依賴項
我們將使用所需的最少依賴項來簡化流程。這意味著我們不會包含任何類似spring-ai-ollama-spring-boot-starter的實作。我們的解決方案將基於接口,而不是使用任何Model實作:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-model</artifactId>
<version>1.0.2</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-client-chat</artifactId>
<version>1.0.2</version>
</dependency>這兩個足以用 Spring AI 建構代理,因為我們可以利用Model介面及其擴充ChatModel 。此外, ChatClient現在被廣泛使用,正如我們將在本教程後面的範例中看到的那樣。
4. 使用 Spring AI 連結工作流程代理
鍊式工作流程非常適合將任務分解為連續的子任務的情況。每個子任務的結果將傳遞給下一個子任務。我們也有機會在子任務之間添加一些程式碼,用於決策或更改。
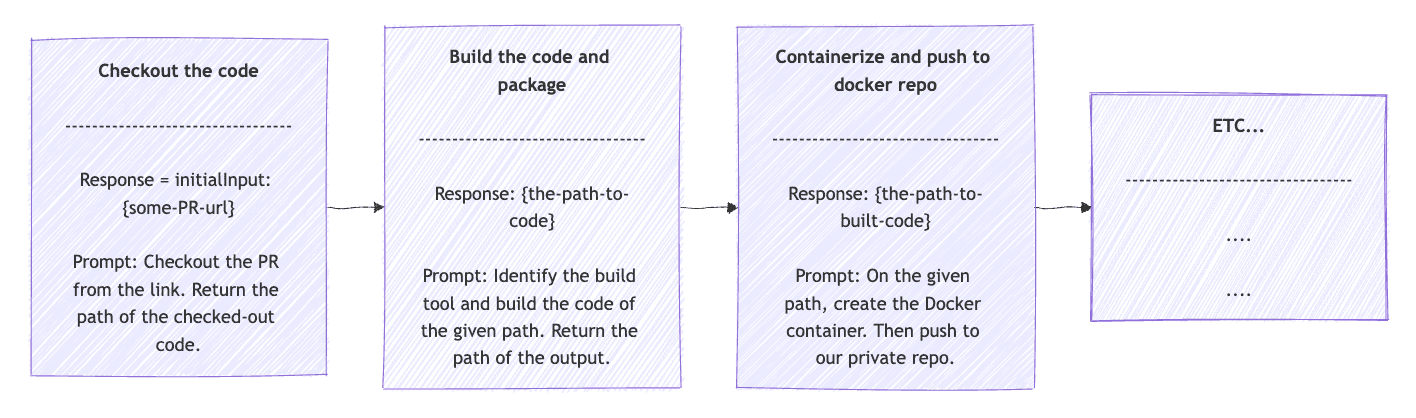
在我們的 CI/CD 中,一個很好的例子是建立管線。我們可以將建構管線分解為具體的、連續的步驟:
- 從 VCS 簽出
- 建構程式碼和套件
- 容器化並推送到 Docker 倉庫
- 將 Docker 映像部署到測試環境
- 運行整合測試
首先假設我們有一個extends ChatClient OpsClient接口,以及一個與 DevOps 模型互動的實作。使用 Spring AI 的有效代理如下所示:
public String opsPipeline(String userInput) {
String response = userInput;
for (String prompt : OpsClientPrompts.DEV_PIPELINE_STEPS) {
String request = String.format("{%s}\n {%s}", prompt, response);
ChatClient.ChatClientRequestSpec requestSpec = opsClient.prompt(request);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
response = responseSpec.content();
if (response.startsWith("ERROR:")) {
break;
}
}
return response;
}首先,我們在 for 迴圈中使用OpsClientPrompts.DEV_PIPELINE_STEPS 。這些步驟比前面提到的步驟更具描述性。例如,對於從 VCS 檢出,它會類似於「從給定的 URL 檢出程式碼。傳回檢出程式碼的路徑,否則發生錯誤」。
在鍊式模式中,每個回應都會作為後續步驟的輸入。因此, request字段的作用正是如此。給定下一步的提示和上一個步驟的回應,建立request作為prompt()方法的參數,該方法將使用call()方法執行。結果儲存在response中,以供下一步使用。初始response值將是使用者輸入。最後,在步驟之間,我們新增一個 if 子句,用於在發生錯誤時中斷循環。鍊式工作流程應如下所示:
5. 使用 Spring AI 並行化工作流程代理
並行化工作流程非常適合將任務分解為可並行執行的獨立子任務的情況。這些子任務的結果將以程式方式聚合為單一結果。
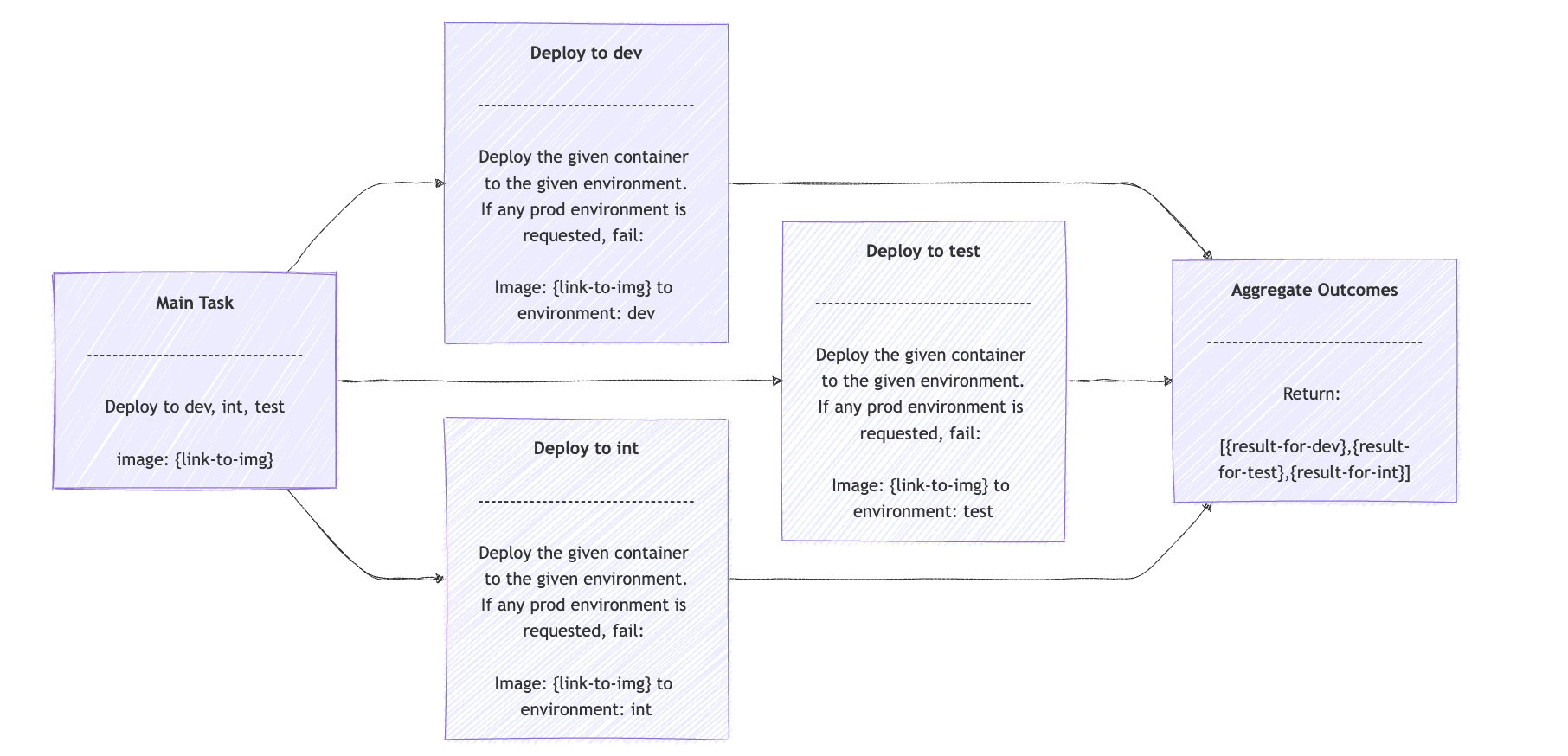
一個實際的例子,遵循相同的 DevOps 模型概念,是將新版本的程式碼部署到多個環境(如測試、開發、整合等)。由於這涉及到一個 AI 代理,我們預計幕後會發生更多的事情,例如檢查部門指南以驗證此鏡像是否可以部署到每個環境等。 Spring AI 的有效代理將利用ExecutorService和CompletableFuture :
public List<String> opsDeployments(String containerLink, List<String> environments, int maxConcurentWorkers) {
try (ExecutorService executor = Executors.newFixedThreadPool(maxConcurentWorkers)) {
List<CompletableFuture<String>> futures = environments.stream()
.map(env -> CompletableFuture.supplyAsync(() -> {
try {
String request = OpsClientPrompts.NON_PROD_DEPLOYMENT_PROMPT + "\n Image:" + containerLink + " to environment: " + env;
ChatClient.ChatClientRequestSpec requestSpec = opsClient.prompt(request);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
return responseSpec.content();
} catch (Exception e) { ... }
}, executor))
.toList();
CompletableFuture<Void> allFutures = CompletableFuture.allOf(futures.toArray(CompletableFuture[]::new));
allFutures.join();
return futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList());
}
}opsDeployments()方法接受包含待部署鏡像的容器的連結、目標環境以及最大並發工作執行緒數。然後,我們使用流將任務分解為每個給定環境的一個部署任務。
每個request欄位都是部署的提示符(在我們的例子中是OpsClientPrompts.NON_PROD_DEPLOYMENT_PROMPT 、 containerLink,以及具體的environment變數。結果只是一個包含每個結果的陣列。並行化工作流程應該如下所示:
6. 使用 Spring AI 路由工作流程代理
當我們想要將任務分配給更專業的 AI 模型時,路由工作流程 (Routing Workflow) 非常適用。一個很好的例子是,LLM 充當客戶服務支持,接收客戶輸入,然後將任務重新導向到技術支援模型、客戶服務模型等。客戶無需知道存在多個模型。相反,使用通用的模型作為路由工作流程即可。
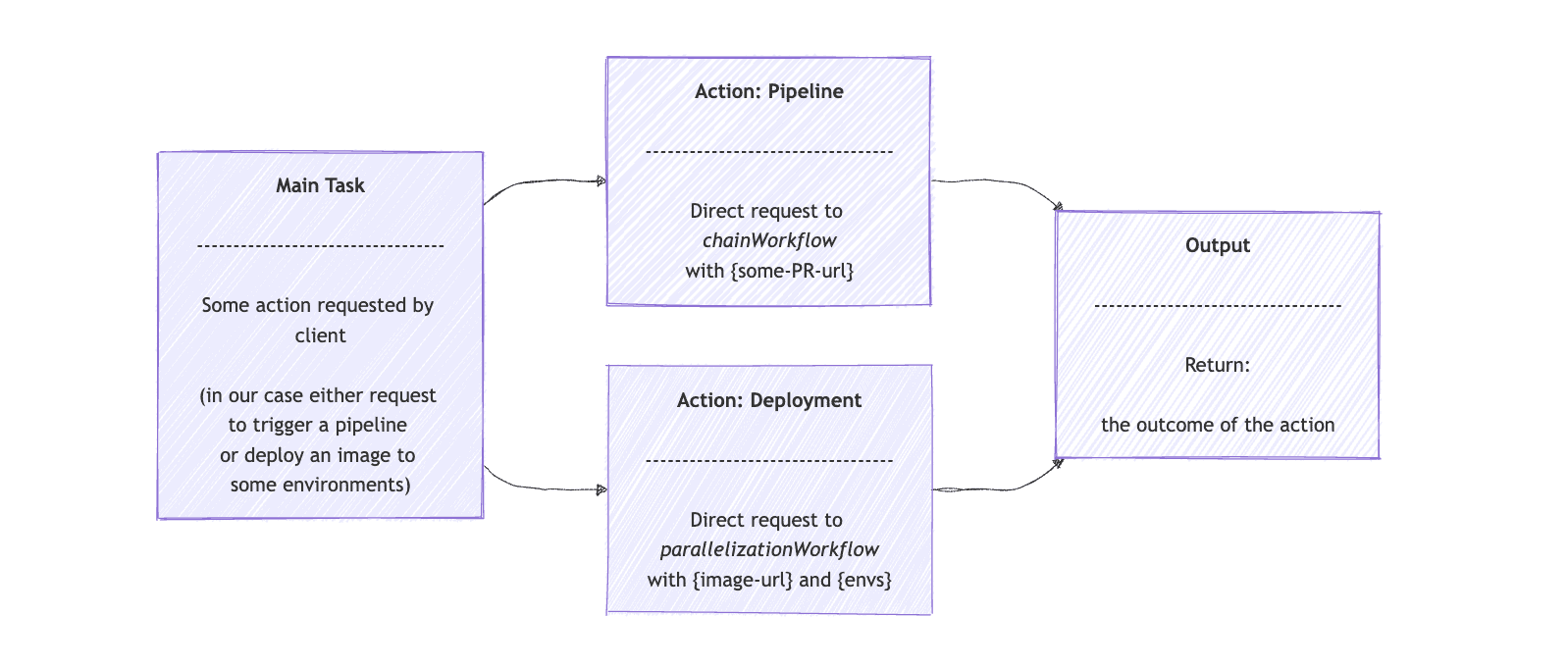
延續我們的 DevOps 模型範例,我們可以建立一個通用的 DevOps 代理,它接受任何建置拉取請求 (PR) 管線或將 PR 部署到某個環境的請求。然後,路由工作流程將使用 Spring AI 將請求轉送到前面範例中的有效代理程式。
首先,我們使用extends ChatClient opsRoutingClient介面。我們向客戶端提供路由選項和使用者輸入。然後,我們要求它將請求路由到ChainWorkflow或ParallelizationWorkflow ,就像本文前面實現的那樣:
public class RoutingWorkflow {
private final OpsRouterClient opsRouterClient;
private final ChainWorkflow chainWorkflow;
private final ParallelizationWorkflow parallelizationWorkflow;
// constructor omitted
public String route(String input) {
String[] route = determineRoute(input, OPS_ROUTING_OPTIONS);
String opsOperation = route[0];
List<String> requestValues = route[1].lines()
.toList();
return switch (opsOperation) {
case "pipeline" -> chainWorkflow.opsPipeline(requestValues.getFirst());
case "deployment" -> executeDeployment(requestValues);
default -> throw new IllegalStateException("Unexpected value: " + opsOperation);
};
}
private String[] determineRoute(String input, Map<String, String> availableRoutes) {
String request = String.format("""
Given this map that provides the ops operation as key and the description for you to build the operation value, as value: %s.
Analyze the input and select the most appropriate operation.
Return an array of two strings. First string is the operations decided and second is the value you built based on the operation.
Input: %s""", availableRoutes, input);
ChatClient.ChatClientRequestSpec requestSpec = opsRouterClient.prompt(request);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
String[] routingResponse = responseSpec.entity(String[].class);
System.out.printf("Routing Decision: Operation is: %s\n, Operation value: %s%n", routingResponse[0], routingResponse[1]);
return routingResponse;
}
private String executeDeployment(List<String> requestValues) {
String containerLink = requestValues.getFirst();
List<String> environments = Arrays.asList(requestValues.get(1)
.split(","));
int maxWorkers = Integer.parseInt(requestValues.getLast());
List<String> results = parallelizationWorkflow.opsDeployments(containerLink, environments, maxWorkers);
return String.join(", ", results);
}
}route()方法先決定要使用的專用任務,要嘛是pipeline ,要嘛是deployment 。 route數組將包含操作以及opsRouterClient回傳的提示。然後,如果操作是“ pipeline ”,它將直接將請求傳送到chainWorkflow 。如果操作是“ deployment ”,則executeDeployment()方法會準備請求並將其傳送至parallelizationWorkflow代理程式。
對於路由工作流程模式,使用 Spring AI 的有效代理的圖形表示如下:
7. 使用 Spring AI 的 Orchestrator Workers Agents
當我們有一個複雜的任務,可以分解成更簡單的子任務,但又無法預先預測它們會是哪些時,Orchestrator Workers 工作流程是最佳選擇。 Orchestrator Agent 會將子任務委託給 Worker Agent。最後,它會收集結果,並最終產生初始任務的最終結果。
在我們的 DevOps 模型範例中,我們可以有一個 Orchestrator,它接受 PR URL,分析變更並確定哪些環境需要測試。例如,一個較小的輸入驗證更新只需在我們的測試環境中進行測試即可。相反,影響外部系統整合的變更也需要在整合環境中進行測試。
假設我們有一個OpsOrchestratorClient類,它擴展了ChatClient 。我們可以提供一個描述此案例和 PR 連結的提示,並要求它返回我們需要運行測試的環境。然後將其提供給我們的OpsClient來執行部署並執行測試:
public String remoteTestingExecution(String userInput) {
String orchestratorRequest = REMOTE_TESTING_ORCHESTRATION_PROMPT + userInput;
ChatClient.ChatClientRequestSpec orchestratorRequestSpec = opsOrchestratorClient.prompt(orchestratorRequest);
ChatClient.CallResponseSpec orchestratorResponseSpec = orchestratorRequestSpec.call();
String[] orchestratorResponse = orchestratorResponseSpec.entity(String[].class);
String prLink = orchestratorResponse[0];
StringBuilder response = new StringBuilder();
for (int i = 1; i < orchestratorResponse.length; i++) {
String testExecutionChainInput = prLink + " on " + orchestratorResponse[i];
for (String prompt : OpsClientPrompts.EXECUTE_TEST_ON_DEPLOYED_ENV_STEPS) {
String testExecutionChainRequest =
String.format("%s\n PR: [%s] environment", prompt, testExecutionChainInput);
ChatClient.ChatClientRequestSpec requestSpec = opsClient.prompt(testExecutionChainRequest);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
testExecutionChainInput = responseSpec.content();
System.out.printf("OUTCOME: %s\n", testExecutionChainInput);
}
response.append(testExecutionChainInput).append("\n");
}
return response.toString();
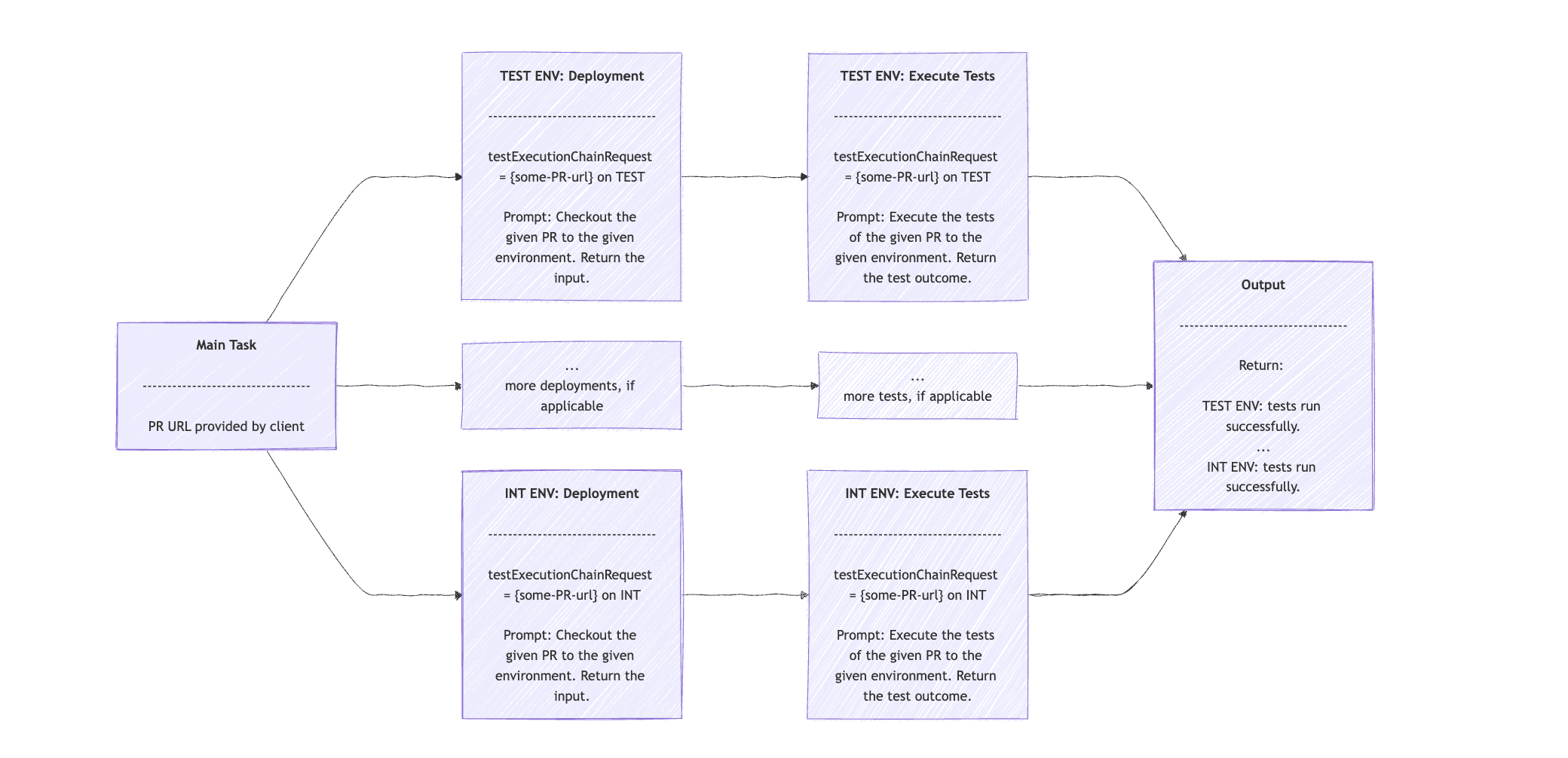
}orchestratorRequest字串將包含用於分析 PR 變更的提示,並傳回環境清單。我們在orchestratorResponse數組中取得環境列表。對於每個環境,我們分兩步驟執行子任務:第一步是部署,第二步是測試執行。
希望您注意到我們在第二個for迴圈中使用了 Chain Workflow。我們從部署提示開始,並以 PR URL 和目前環境的語句作為輸入。回應包含一個輸入語句。然後,該語句被輸入到第二個提示中,該提示根據 PR 連結中的信息執行與當前環境相關的測試。
輸出包含一個句子,其中包含每個環境的測試執行結果。
請注意,我們透過避免並行或非同步執行子任務來簡化範例。然而,使用這些技術才是實現 Orchestrator-Workers 工作流程模式最有效的方法。此模式的可視化順序應類似於:
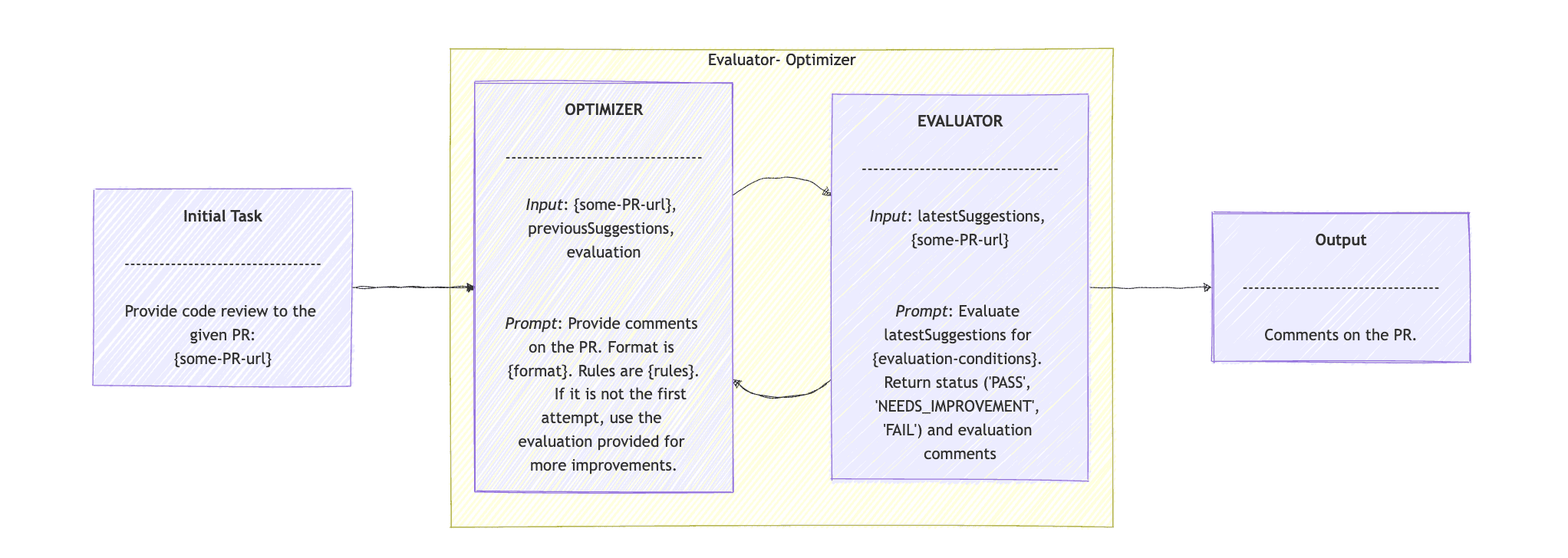
8. 使用 Spring AI 的評估優化代理
Anthropic 出版物提出的最後一個模式是評估器-優化器。顧名思義,評估器-優化器工作流程模式非常適合涉及產生建議的任務。優化器會提出初步解決方案或改進方案。評估器隨後會針對該建議提供回饋,並可能再次呼叫優化器來最佳化結果或產生更準確的結果。
我們擴展了 DevOps 範例,並圍繞 PR 提供了一項新功能:我們將使用 Evaluator-Optimizer 工作流程提供 PR 審核意見。假設CodeReviewClient介面extends ChatClient ,我們使用 Spring AI 建立 Agent,並附帶一個簡單的evaluate()方法:
public class EvaluatorOptimizerWorkflow {
private final CodeReviewClient codeReviewClient;
static final ParameterizedTypeReference<Map<String, String>> mapClass = new ParameterizedTypeReference<>() {};
// constructor omitted
public Map<String, String> evaluate(String task) {
return loop(task, new HashMap<>(), "");
}
private Map<String, String> loop(String task, Map<String, String> latestSuggestions, String evaluation) {
latestSuggestions = generate(task, latestSuggestions, evaluation);
Map<String, String> evaluationResponse = evaluate(latestSuggestions, task);
String outcome = evaluationResponse.keySet().iterator().next();
evaluation = evaluationResponse.values().iterator().next();
if ("PASS".equals(outcome)) {
return latestSuggestions;
}
return loop(task, latestSuggestions, evaluation);
}
// we'll see the generate() and evaluate() methods later
}評估器優化器模式始於接受任務的evaluate()方法。在我們的範例中,輸入只是 PR 連結。我們將此任務傳送到loop()方法。此方法接受三個參數:任務、先前的建議和評估結果。在第一個循環中,我們只提供任務。
loop()方法呼叫generate() ,我們稍後會看到。結果是最新的建議,我們會將其與任務一起傳遞給evaluate()方法。接下來,我們從evaluationResponse中讀取結果,如果結果為“PASS”,則傳回最新的建議。如果不是,則使用新的latestSuggestions和evaluation再次呼叫loop()方法。
我們使用CodeReviewClient代理來執行generate()和evaluate()方法:
private Map<String, String> generate(String task, Map<String, String> previousSuggestions, String evaluation) {
String request = CODE_REVIEW_PROMPT +
"\n PR: " + task +
"\n previous suggestions: " + previousSuggestions +
"\n evaluation on previous suggestions: " + evaluation;
ChatClient.ChatClientRequestSpec requestSpec = codeReviewClient.prompt(request);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
Map<String, String> response = responseSpec.entity(mapClass);
return response;
}
private Map<String, String> evaluate(Map<String, String> latestSuggestions, String task) {
String request = EVALUATE_PROPOSED_IMPROVEMENTS_PROMPT +
"\n PR: " + task +
"\n proposed suggestions: " + latestSuggestions;
ChatClient.ChatClientRequestSpec requestSpec = codeReviewClient.prompt(request);
ChatClient.CallResponseSpec responseSpec = requestSpec.call();
Map<String, String> response = responseSpec.entity(mapClass);
return response;
}在generate()中,我們向codeReviewClient代理提供提示、 task 、 previousSuggestions和evaluation 。提示是根據最新的建議和最新的評估結果,對 PR 進行程式碼審查。建議應遵循既定規則並遵循特定格式。
在evaluation()中,提示是「根據給定的任務和最新的建議, Evaluate the suggested code improvements for correctness, time complexity, and best practices 」。然後返回評估結果“PASS”, “NEEDS_IMPROVEMENT”, “FAIL” ,以及相應的回饋。
優化器-評估器工作流程模式的序列圖是:
9. 結論
在本教學中,我們學習了 Antropic 的《Effective AI Agents》一書。我們介紹了所有模式,提供了簡要定義,並提供了實際用例的範例。然後,我們示範了使用 Spring AI 代理實現每個模式的方法。最後,我們為每個模式都繪製了序列圖,以便直觀地了解該模式的實際工作方式。
與往常一樣,演示中使用的所有原始程式碼都可以在 GitHub 上找到。