並行 Flux 與 Project Reactor 中的 Flux
1. 簡介
Reactor 專案是一個功能強大的程式庫,可用於建立完全非阻塞的 Java 響應式應用程式。 Reactor 引入了兩種可組合的響應式類型: Flux和Mono 。
如今,多核心架構已是大勢所趨,能夠輕鬆並行化工作至關重要。對於Flux來說,Project Reactor 透過提供一種特殊類型ParallelFlux來幫助我們實現這一點,該類型暴露了針對平行化工作進行最佳化的操作符。
在本教程中,我們將比較Flux和ParallelFlux ,使用計算密集型任務來突出它們的差異以及對反應式應用程式效能的影響。
2. Flux簡介
[Flux](https://projectreactor.io/docs/core/release/api/reactor/core/publisher/Flux.html)是 Project Reactor 中的一個基本類型,表示由 0 到 N 個元素組成的回應式流。 Flux Flux我們能夠以非同步和非阻塞的方式處理數據,這對於處理資料庫結果或事件流等序列非常理想。 如下圖所示:
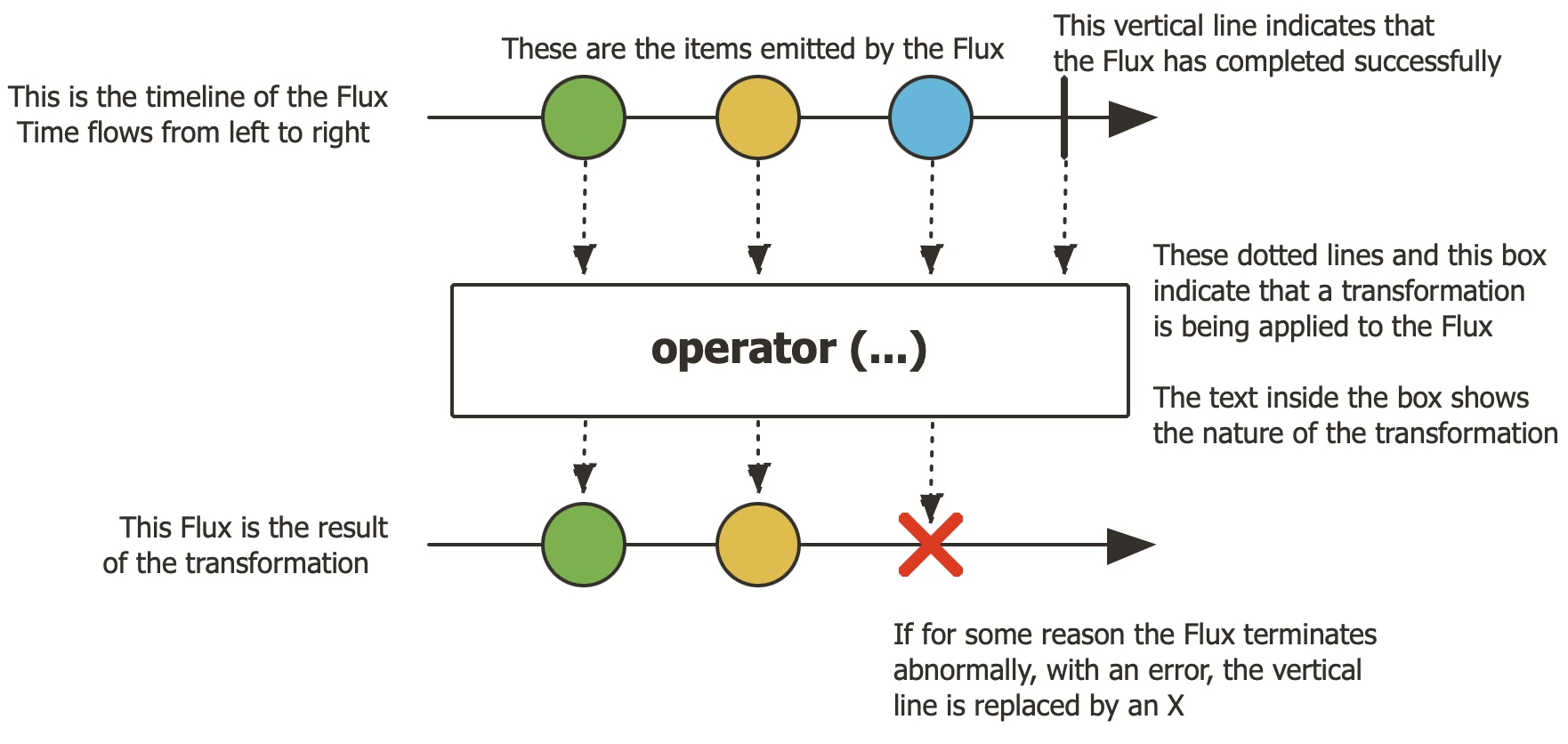
建立簡單Flux方法如下:
Flux<Integer> flux = Flux.range(1, 10);預設情況下, Flux在單執行緒上順序運行,但它可以利用調度程序實現並發。對於大多數響應式工作流程,尤其是涉及 I/O 或小型資料集的工作流程, Flux簡單且有效率。
3. ParallelFlux簡介
[ParallelFlux](https://projectreactor.io/docs/core/release/api/reactor/core/publisher/ParallelFlux.html)擴充了Flux的平行處理功能。 ParallelFlux 讓我們能夠將一個流拆分為多個軌道或子流,每個ParallelFlux或子流在單獨的執行緒上進行處理,使其適用於 CPU 密集型任務, 如下圖所示:
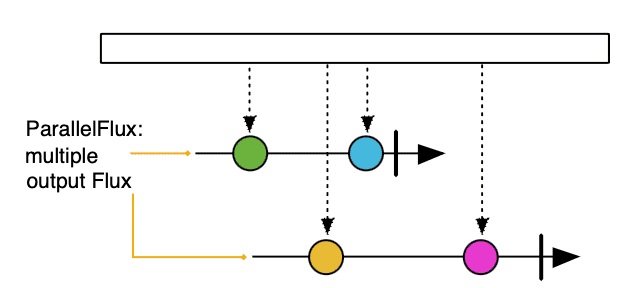
我們可以透過傳遞Scheduler作為參數,使用parallel()運算子和[runOn(Scheduler scheduler)](https://projectreactor.io/docs/core/release/api/reactor/core/publisher/ParallelFlux.html#runOn-reactor.core.scheduler.Scheduler-)將Flux轉換為ParallelFlux :
Flux<Integer> flux = Flux.range(1, 10);
ParallelFlux<Integer> parallelFlux = flux.parallel(2).runOn(Schedulers.parallel());ParallelFlux利用多執行緒實現更快的運算,使其成為運算密集型工作負載的理想選擇。
4. Flux和ParallelFlux之間的主要區別
我們來計算斐波那契數,這是一項運算密集的 CPU 綁定任務,以展示Flux和ParallelFlux之間的效能差異,突顯ParallelFlux's優勢。
4.1. 斐波那契計算
我們將處理一個整數列表,並計算每個整數的斐波那契數。斐波那契函數是遞歸函數,運算量龐大,它模擬了現實世界中 CPU 密集的任務:
private long fibonacci(int n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}4.2. 斐波那契數列的Flux實現
讓我們實作Flux版本以在單一執行緒上順序處理元素:
Flux<Integer> flux = Flux.just(43, 44, 45, 47, 48)
.map(n -> fibonacci(n));這種方法很簡單,但對於 CPU 密集型工作負載來說速度較慢,因為它一次處理一個數字。
4.3. 斐波那契數列的ParallelFlux實現
在ParallelFlux版本中,我們將流拆分為兩個軌道,每個軌道在單獨的執行緒上運行。透過將工作負載分配到兩個執行緒上, ParallelFlux將減少總執行時間:
ParallelFlux<Integer> parallelFlux = Flux.just(43, 44, 45, 47, 48)
.parallel(2)
.runOn(Schedulers.parallel())
.map(n -> fibonacci(n));這演示了 ParallelFlux 如何利用多執行緒實現更快的運算。
4.4. Flux和ParallelFlux的執行時間比較
在這裡,為了計算差異,我們將測量使用 JMH 處理計算量大的任務時Flux和ParallelFlux實現的執行時間。
以下是使用Flux執行計算的測試,它按順序處理資料:
@Test
public void givenFibonacciIndices_whenComputingWithFlux_thenCorrectResults() {
Flux<Long> fluxFibonacci = Flux.just(43, 44, 45, 47, 48)
.map(Fibonacci::fibonacci);
StepVerifier.create(fluxFibonacci)
.expectNext(433494437L, 701408733L, 1134903170L, 2971215073L, 4807526976L)
.verifyComplete();我們透過使用JMH運行微基準測試來測量使用 Flux 處理斐波那契數列的執行時間,這提供了可靠且可重複的效能測量:
@Test
public void givenFibonacciIndices_whenComputingWithFlux_thenRunBenchMarks() throws IOException {
Main.main(new String[] {
"com.baeldung.reactor.flux.parallelflux.FibonacciFluxParallelFluxBenchmark.benchMarkFluxSequential",
"-i", "3",
"-wi", "2",
"-f", "1"
});
}@Benchmark
public List<Long> benchMarkFluxSequential() {
Flux<Long> fluxFibonacci = Flux.just(43, 44, 45, 47, 48)
.map(Fibonacci::fibonacci);
return fluxFibonacci.collectList().block();
}下面顯示的基準測試結果是在多核心機器上收集的,並且可能根據系統負載和硬體配置而略有不同:
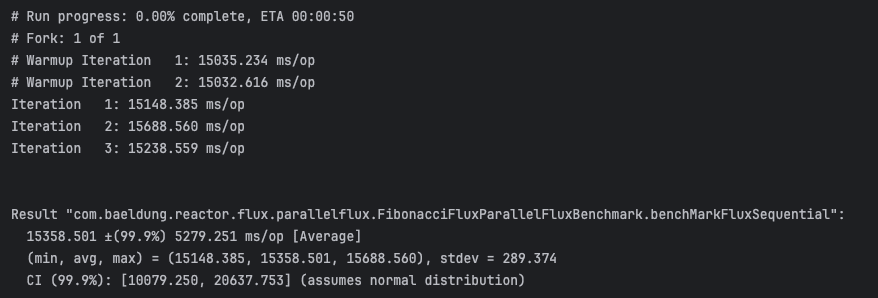

接下來,我們將此執行時間與ParallelFlux實作進行比較,其中每個計算分佈在多個執行緒上,根據 CPU 可用性和工作負載,可能會加快總處理時間:
@Test
public void givenFibonacciIndices_whenComputingWithParallelFlux_thenCorrectResults() {
ParallelFlux<Long> parallelFluxFibonacci = Flux.just(43, 44, 45, 47, 48)
.parallel(3)
.runOn(Schedulers.parallel())
.map(Fibonacci::fibonacci);
Flux<Long> sequencialParallelFlux = parallelFluxFibonacci.sequential();
Set<Long> expectedSet = new HashSet<>(Set.of(433494437L, 701408733L, 1134903170L, 2971215073L, 4807526976L));
StepVerifier.create(sequencialParallelFlux)
.expectNextMatches(expectedSet::remove)
.expectNextMatches(expectedSet::remove)
.expectNextMatches(expectedSet::remove)
.expectNextMatches(expectedSet::remove)
.expectNextMatches(expectedSet::remove)
.verifyComplete();與我們對Flux所做的類似,我們測量使用ParallelFlux和 JMH 處理斐波那契數列所需的時間,以便與順序Flux版本進行比較:
@Benchmark
public List<Long> benchMarkParallelFluxSequential() {
ParallelFlux<Long> parallelFluxFibonacci = Flux.just(43, 44, 45, 47, 48)
.parallel(3)
.runOn(Schedulers.parallel())
.map(Fibonacci::fibonacci);
return parallelFluxFibonacci.sequential().collectList().block();
}@Test
public void givenFibonacciIndices_whenComputingWithParallelFlux_thenRunBenchMarks() throws IOException {
Main.main(new String[] {
"com.baeldung.reactor.flux.parallelflux.FibonacciFluxParallelFluxBenchmark.benchMarkParallelFluxSequential",
"-i", "3",
"-wi", "2",
"-f", "1"
});
}下面的 JMH 基準測試結果以毫秒為單位捕捉了總執行時間,展示了並行執行的優勢。儘管是並發處理,每個斐波那契指數只計算一次並發出一次:
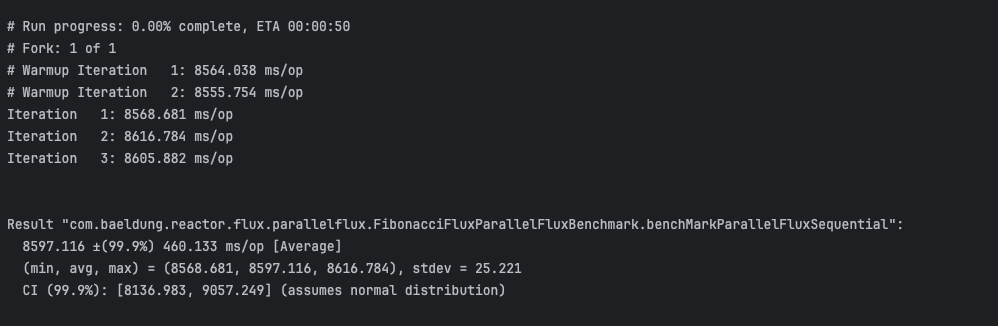

我們的測試表明,在典型的多核心 CPU 上,對於 CPU 密集型任務, ParallelFlux速度明顯快於 Flux。
5. Project Reactor 中的調度器
我們依靠調度器來控制哪些線程處理我們的響應式流。**調度器對於Flux和ParallelFlux中的並發控制至關重要。**
Schedulers.parallel()針對 CPU 密集型任務進行了最佳化,使用與可用 CPU 核心數相等的固定執行緒池大小。 Schedulers.boundedElastic Schedulers.boundedElastic()針對 I/O 密集型任務進行了最佳化,可以根據需要動態擴展執行緒池。
ParallelFlux始終需要一個調度器來定義每個軌道的運行位置,通常使用Schedulers.parallel()來處理計算量大的工作負載。 Flux 也可以使用諸如publishOn(Schedulers.boundedElastic())之類的調度Flux來引入並發性,並增強 I/O 操作的響應速度,即使沒有並行處理也是如此。
請務必選擇與您的工作負載相符的調度器:對於 CPU 密集型任務,請Schedulers.parallel() ;對於 I/O 密集型任務,請Schedulers.boundedElastic() 。無論使用 Flux 還是 ParallelFlux,這都能確保高效且反應迅速的執行。
6. 在Flux和ParallelFlux之間進行選擇
我們根據反應式管道中的工作負載類型在Flux和ParallelFlux之間進行選擇。
Flux應該用於 I/O 密集型任務,例如 REST 呼叫或資料庫訪問,在這些任務中,並行性帶來的益處不大。對於小型資料集或輕量級操作,如果順序處理速度夠快,Flux 也是理想之選。
ParallelFlux適用於 CPU 密集任務,因為並行性可以縮短執行時間。它也是大型資料集的理想選擇,因為跨核心分配工作可以提高效能。
我們的測試重點介紹了ParallelFlux如何提高運算密集型任務的效能,而Flux對於輕量級或 I/O 驅動的工作流程仍然更簡單、更有效率。
7. 實踐陷阱與最佳實踐
在本節中,我們將解決使用ParallelFlux時的常見陷阱和最佳實踐,並使用簡單的程式碼範例和測試來驗證這些說法。
7.1. ParallelFlux的陷阱
使用ParallelFlux時,會引入執行緒管理開銷。對於小型或輕量級的任務,與使用Flux相比,這種開銷實際上會降低我們的速度。
使用多於可用 CPU 核心的軌道,可能會導致執行緒爭用,例如在 4 核心機器上使用 8 個軌道,從而導致效能下降而不是提高。
預設情況下, ParallelFlux不保留順序,這在順序敏感的工作流程中可能會出現問題,除非應用了ordered()或後處理。
讓我們建立一個簡單的函數,使用ParallelFlux將一小串字串 ID 清單轉換為大寫。這說明了ParallelFlux如何在不保證輸出順序的情況下並行處理元素。
為了更好地觀察這種行為,我們使用 JUnit 的RepeatedTest註解重複執行相同的測試 5 次:
@RepeatedTest(5)
public void givenListOfIds_whenComputingWithParallelFlux_OrderChanges() {
ParallelFlux<String> parallelFlux = Flux.just("id1", "id2", "id3")
.parallel(2)
.runOn(Schedulers.parallel())
.map(String::toUpperCase);
List<String> emitted = new CopyOnWriteArrayList<>();
StepVerifier.create(parallelFlux.sequential().doOnNext(emitted::add))
.expectNextCount(3)
.verifyComplete();
log.info("ParallelFlux emitted order: {}", emitted);
}

雖然每次執行處理的輸入相同,但所有 5 次運行的日誌輸出都表明,每次執行發出的元素順序可能會有所不同。這是因為ParallelFlux跨執行緒並發執行工作,並且沒有任何順序約束,因此最終序列不確定。
7.2. ParallelFlux的最佳實踐
對於 CPU 密集型任務,我們建議使用Schedulers.parallel() ,它由與可用 CPU 核心數相等的固定大小執行緒池支援。
這確保了高效率的並行執行,而不會給系統帶來負擔。
為了充分利用可用的處理能力,請將軌道數量設定為與 CPU 核心數量相符。您可以使用Runtime.getRuntime().availableProcessors()檢索此信息,以動態調整機器的容量。
以下範例顯示設定軌道數量以符合 CPU 核心,並使用Schedulers.parallel()透過ParallelFlux高效並行執行斐波那契計算:
ParallelFlux<Long> parallelFlux = Flux.just(40, 41, 42, 43, 44, 45, 46, 47, 48, 49)
.parallel(Runtime.getRuntime().availableProcessors())
.runOn(Schedulers.parallel())
.map(n -> fibonacci(n));8. 結論
在本文中,我們使用斐波那契演算法(一項計算密集型任務)比較了Flux和ParallelFlux 。我們還探討了何時使用Flux和ParallelFlux ,重點介紹了它們之間的差異,並討論了ParallelFlux最佳實踐和陷阱。
與往常一樣,本文中使用的所有程式碼範例均可在 GitHub 上找到。