使用 WebMagic 的網路爬蟲
1. 簡介
網路爬蟲或蜘蛛程式是一種搜尋並自動索引網路內容和其他資料的程式。網路爬蟲會掃描網頁,了解每個網站頁面,以便在使用者執行搜尋查詢時檢索、更新和索引資訊。
WebMagic 是一個簡單、強大且可擴展的網路爬蟲框架。它從 Python 的熱門框架 Scrapy 中汲取靈感,以極少的樣板程式碼處理 HTTP 請求、HTML 解析、任務調度和資料管道處理。
在本教程中,我們將探索 WebMagic、它的架構、設定和一個基本的 Hello World 範例。
2. 架構
WebMagic 採用模組化和可擴展的架構建構。讓我們來看看它的核心組件:
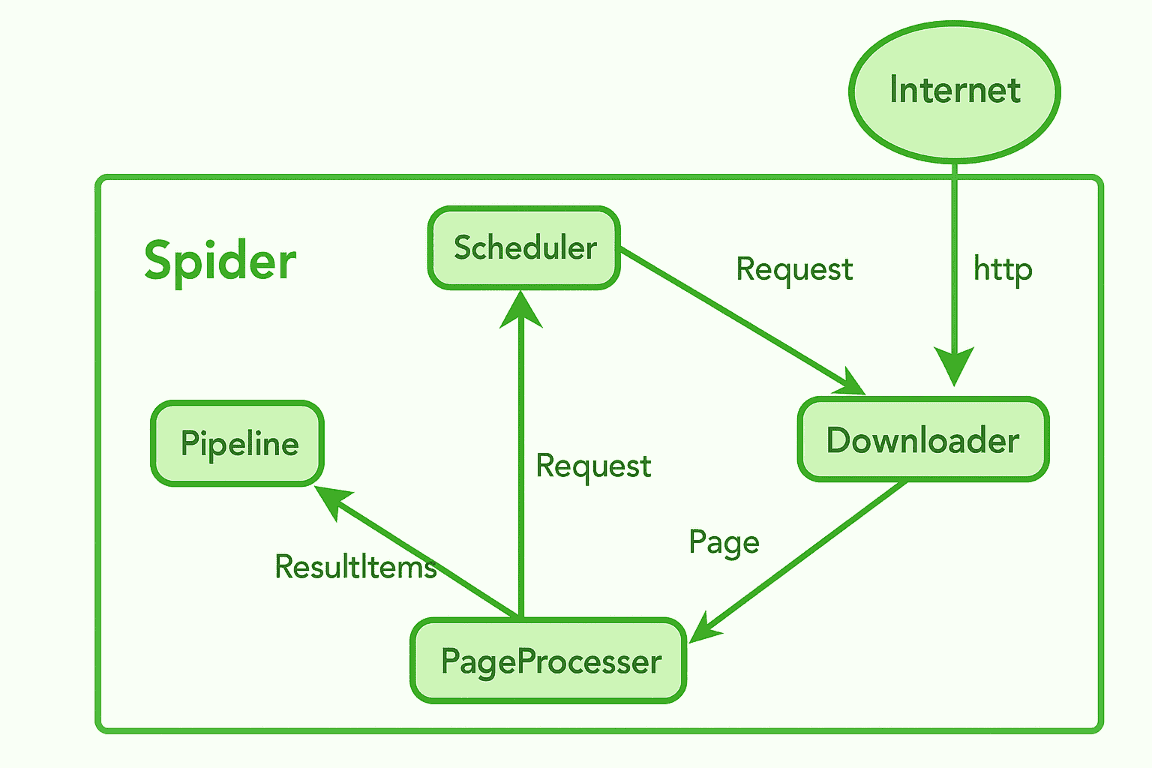
2.1. 蜘蛛
Spider 是協調整個爬取過程的主引擎。它接收初始URL ,然後呼叫下載器、處理器和管道。
2.2. 調度器
調度器的主要工作是管理需要抓取的 URL 佇列。它還會追蹤已訪問的 URL,以防止重複抓取。它每次向下載器發送一個請求進行進一步處理。我們也可以使用記憶體調度器、基於檔案、Redis 或自訂調度器。
2.3. 下載器
下載器負責處理實際的 HTTP 請求。它負責從網路下載 HTML 內容。下載器的預設實作使用 Apache HttpClient,但我們可以自訂它以使用 OkHttp 或任何其他庫。頁面下載完成後,它會將下載的頁面傳遞給 PageProcessor。
2.4. 頁面處理器
PageProcessor 也被稱為爬蟲邏輯的核心。顧名思義,它定義瞭如何從頁面中提取目標資料(例如產品、價格等)以及要爬取的新連結。我們必須實作process方法來解析回應並提取所需的資訊。
一旦提取完畢,資料就會被傳送到管道,而要抓取的新連結則會被傳送回調度程式。
2.5. 管道
管道負責對提取的資料進行後處理。最常見的操作是將提取的資料儲存到資料庫,或將其寫入檔案或控制台。
3. 使用 Maven 進行設定
WebMagic 使用 Maven 作為其建置工具,因此最好使用 Maven 來管理我們的專案。讓我們看看pom.xml檔案中的以下相依性:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>1.0.3</version>
</dependency>另外,WebMagic 使用slf4j和slf4j-log4j12實作。我們需要從我們的實作中排除slf4j-log4j12以避免衝突:
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>4.Hello World 範例
讓我們來看一個例子,我們將抓取books.toscrape.com網站並在控制台上列印前 10 本書的標題和價格。
public class BookScraper implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
@Override
public void process(Page page) {
var books = page.getHtml().css("article.product_pod");
for (int i = 0; i < Math.min(10, books.nodes().size()); i++) {
var book = books.nodes().get(i);
String title = book.css("h3 a", "title").get();
String price = book.css(".price_color", "text").get();
System.out.println("Title: " + title + " | Price: " + price);
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new BookScraper())
.addUrl("https://books.toscrape.com/")
.thread(1)
.run();
}
}在上面的例子中,我們定義了一個BookScraper類,它實作了PageProcessor. process() and getSite()函數可讓我們定義如何抓取頁面以及爬蟲設定。下面這行程式碼將爬蟲配置為最多重試三次失敗的請求,並在每次請求之間等待一秒鐘,以避免被阻塞:
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);process()函數包含實際的抓取邏輯。它從books.toscrape.com網站中選擇所有 CSS 類別名為.product_pod的 HTML article元素。我們遍歷每本書,並使用 CSS 選擇器提取並列印書名和價格。
在main函數中,我們使用我們的類別創建了一個新的WebMagic蜘蛛。我們從書籍的首頁開始,用單線程運行它,然後開始抓取。
讓我們來看看程式下面的輸出,我們可以看到這 10 本書的書名和價格:
17:02:26.460 [main] INFO us.codecraft.webmagic.Spider -- Spider books.toscrape.com started!
Title: A Light in the Attic | Price: £51.77
Title: Tipping the Velvet | Price: £53.74
Title: Soumission | Price: £50.10
Title: Sharp Objects | Price: £47.82
Title: Sapiens: A Brief History of Humankind | Price: £54.23
Title: The Requiem Red | Price: £22.65
Title: The Dirty Little Secrets of Getting Your Dream Job | Price: £33.34
Title: The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull | Price: £17.93
Title: The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics | Price: £22.60
Title: The Black Maria | Price: £52.15
get page: https://books.toscrape.com/
5. 結論
在本教程中,我們探討了 WebMagic 的架構和設定細節。 WebMagic提供了一種簡單且強大的 Java 網路爬蟲建置方法。它的設計使開發人員能夠專注於資料提取,而無需編寫 HTTP、解析和線程處理的樣板程式碼。
如範例所示,只需幾行程式碼,我們就創建了一個可以運行的爬蟲,並能夠提取書名和價格。
與往常一樣,本文的源代碼可在 GitHub 上找到。