Delta Lake 簡介
1.概述
資料湖是一個集中式儲存庫,用於儲存大量結構化和非結構化資料。它具有可擴展性和成本效益,但傳統資料湖通常在資料品質、一致性和可管理性方面存在問題。
Delta Lake是一個開源儲存層,它透過提供符合 ACID 的事務(原子性、一致性、隔離性和持久性)、模式實施、資料版本控制以及統一的批次和串流支援來解決這些挑戰。
在本教程中,我們將探討 Delta Lake 是什麼、為什麼需要它、它的架構、核心功能以及它的工作原理。
2. 傳統資料湖的問題
雖然資料湖靈活且價格低廉,但它們也存在一些影響分析和機器學習工作負載的限制。
2.1. 數據可靠性
傳統資料湖缺乏 ACID 事務。當多個使用者或作業寫入相同資料集時,可能會導致髒讀、部分寫入或檔案損壞。如果沒有內建的資料版本控制,回滾到先前狀態或重現歷史分析並非易事。
2.2. 模式和一致性
當資料集的結構隨時間變化時,就會發生模式漂移。這會導致資料不一致和下游流程不穩定,使分析和機器學習流程容易出錯。
2.3. 性能和管道複雜性
大型資料集可能會導致查詢速度變慢,尤其是在未實施索引或快取的情況下。此外,組織通常會為批次和流式處理維護單獨的管道,這增加了複雜性和維護開銷。
3. Delta Lake 的主要特性
Delta Lake 是一個開源儲存層,為資料湖帶來可靠性。此外,它還能與 Apache Spark 等大數據處理引擎無縫協作,並提供多種功能來解決傳統資料湖的問題。
3.1. ACID事務
Delta Lake 使用 ACID 事務確保資料完整性。這意味著寫入操作要么全部執行,要么全部不執行,從而防止資料損壞,並允許多個用戶同時對同一張表進行讀寫而不會發生衝突。
3.2. 模式執行與演變
Delta Lake 根據表架構驗證傳入資料。無效記錄將被拒絕。同時,它支援受控的更改,例如新增列。這種平衡可以保持數據的一致性,而不會阻礙成長。
3.3. 時間旅行和版本控制
Delta Lake 維護著對錶所做的每項變更的歷史記錄。日誌中的每次提交都會建立表格的新版本。我們可以查詢過去的版本來重現舊報告、偵錯問題或執行審計。這使得數據既可重現又值得信賴。
3.4. 效能優化
Delta Lake 提供內建最佳化功能,可協同加速查詢。 Delta Lake 透過使用資料跳過來避免利用元資料掃描不相關的文件,從而減少不必要的 I/O。
使用z 排序,相關記錄可以彼此靠近存儲,從而加快基於多列過濾的查詢速度。
最後,檔案壓縮透過將過多的小檔案合併為更大、更有效率的檔案來減少處理這些小檔案的開銷,從而確保更快、更可靠的查詢執行。
3.5. 統一批次和流處理
Delta Lake 透過將表同時視為批次來源和串流傳輸來源(接收器)來簡化資料架構。這種統一的方法消除了為歷史資料和即時資料分別建立獨立系統的需要。
我們可以透過串流作業將資料提取到 Delta 表中,然後使用單獨的查詢對同一張表執行批次分析,同時確保資料一致性。
4. 架構
Delta Lake 的核心是一個位於現有雲端或本地物件儲存之上的儲存層。它透過交易日誌和豐富的元資料管理增強了這些儲存系統。
該架構旨在具有可擴展性、容錯性和與引擎無關性,同時提供強大的一致性保證。
4.1. 資料層
Delta Lake 的基本構建塊是Parquet檔案格式。 Parquet是一種列式儲存格式,對於分析查詢非常有效率。
資料被寫入底層儲存系統中的 parquet 文件,該系統可以是任何基於雲端的物件存儲,包括 Amazon S3、 Azure Data Lake Storage (ADLS) 、 Google Cloud Storage (GCS)或Hadoop 分散式檔案系統 (HDFS) 。
因為它與我們目前的儲存層協同工作而不是取代它,所以我們可以逐步引入 Delta Lake,而無需遷移到專有平台。
Parquet 儲存實際的資料記錄,這些記錄被組織成分區,並通常針對常見的查詢模式進行最佳化。此外,即使不使用 Delta Lake 的高級功能,這些檔案也能與任何能夠讀取 Parquet 的引擎相容。
4.2. 元資料層
對於每個 Delta 表,Delta Lake 都會在名為_delta_log的專用目錄中維護一個交易日誌,該日誌與資料檔案一起保存。此日誌是一系列 JSON 檔案(以及用於效能的 Parquet 檢查點),用於記錄對錶所做的每個變更:
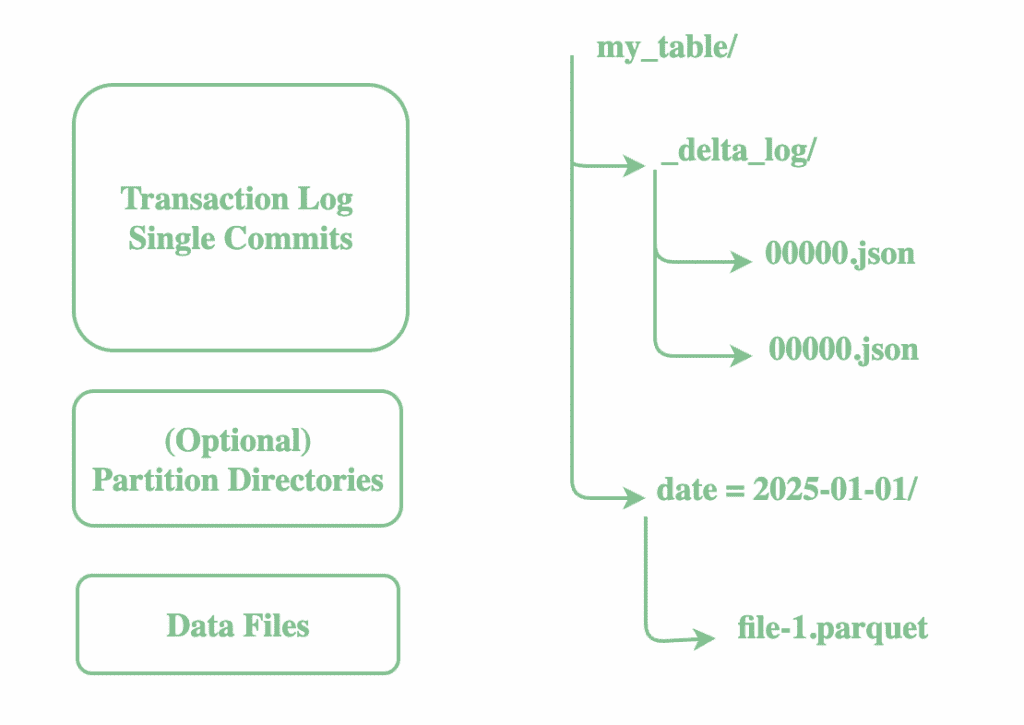
此日誌支援 ACID 事務,支援時間旅行,並允許安全的並發讀寫。每次寫入 Delta 表都會附加一個新的 JSON 提交文件,其中包含:
- 新增或刪除資料文件
- 架構定義
- 分區資訊
- 文件統計資訊(最小/最大、空計數等)
此交易日誌是增量表的真相來源。因此,為了讀取增量表的目前狀態,引擎會讀取交易日誌來決定哪些資料檔案處於「活動」狀態以及目前的模式是什麼。
4.3. 計算層
Delta Lake 中的計算層與引擎無關,這意味著它可以與各種處理引擎協同工作。雖然 Apache Spark 是最常用的引擎,但也可以使用 Trino、Presto、Flink 和 Hive 來查詢 Delta Lake。
引擎在執行查詢時首先讀取_delta_log以確定表的最新快照。使用日誌中的元數據,引擎識別要掃描的特定 Parquet 檔案。
類似地,當我們寫入新資料時,Delta Lake 會將其作為 Parquet 檔案附加並更新_delta_log 。這可以防止部分寫入損壞資料集,一旦成功,就會記錄一個新的 JSON 條目,捕獲更新的狀態、模式和檔案統計資料。
為了進一步提高效能,系統在查詢執行過程中應用了快取、資料跳過和叢集讀取等最佳化。
5.訪問 Delta Lake
在開始建立和查詢 Delta 表之前,我們必須配置環境以識別 Delta 格式。開源 Apache Spark 預設不會捆綁 Delta Lake,因此根據 Spark 的運行環境,我們可能需要採取一些額外的步驟。
5.1. 阿帕契火花
對於原生 Spark 部署,我們需要明確地添加 Delta Lake 庫,並配置 Spark 使其能夠理解 Delta 的擴展 SQL 功能。為此,我們首先需要在pom.xml中加入Maven 依賴項:
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-core_2.12</artifactId>
<version>2.4.0</version>
</dependency>然後,我們指示 Spark 使用 Delta 的自訂擴充功能和目錄。 Spark 在建立會話時套用此配置:
SparkSession spark = SparkSession.builder()
.appName("DeltaExample")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate();
我們現在使用 Spark DataFrame 或 SQL 來建立增量表。現在讓我們在臨時位置建立一個範例表,並將其在 Spark SQL 中註冊為增量表:
public static String preparePeopleTable(SparkSession spark) {
try {
String tablePath = Files.createTempDirectory("delta-table-").toAbsolutePath().toString();
Dataset<Row> data = spark.createDataFrame(
java.util.Arrays.asList(
new Person(1, "Alice"),
new Person(2, "Bob")
),
Person.class
);
data.write().format("delta").mode("overwrite").save(tablePath);
spark.sql("DROP TABLE IF EXISTS people");
spark.sql("CREATE TABLE IF NOT EXISTS people USING DELTA LOCATION '" + tablePath + "'");
return tablePath;
} catch (Exception e) {
throw new RuntimeException(e);
}
}現在讓我們驗證一下我們創建的表確實是Delta表:
@Test
void givenDeltaLake_whenUsingDeltaFormat_thenPrintAndValidate() {
Dataset<Row> df = spark.sql("DESCRIBE DETAIL people");
df.show(false);
Row row = df.first();
assertEquals("file:"+tablePath, row.getAs("location"));
assertEquals("delta", row.getAs("format"));
assertTrue(row.<Long>getAs("numFiles") >= 1);
}透過這些配置,Spark 知道如何解釋 Delta 的交易日誌和元資料。這意味著我們可以執行 Delta Lake 獨有的 SQL 指令,例如MERGE INTO 、 VACUUM或時間旅行查詢。
5.2. 資料塊
Delta Lake 已完全集成,並在Databricks中預設啟用。因此,我們可以立即使用 SQL 或 DataFrame API 建立 Delta 表,並探索模式演進、更新插入和時間旅行等高級功能,而無需任何手動設定。
此外,Databricks 還提供基於筆記本或控制台的介面,使用者可以在其中查詢 Delta Lake,而無需自己編寫連接邏輯。
這種無縫整合使我們能夠專注於建立管道和分析數據,而不是管理依賴關係或配置。
5.3. 其他引擎
Delta Lake 不僅限於 Spark,它還可以與 Trino、Presto、Flink 和 Hive 等其他引擎一起使用。
Trino 和 Presto 等工具透過 Delta 連接器插件進行連接,而 Flink 擁有自己專用的 Delta 連接器庫。 Hive 也透過單獨的連接器與 Delta 整合。
要記住的關鍵是,這些連接器預設不包含在內,必須先安裝在叢集上,然後才能查詢 Delta 表。
6. 結論
在本文中,我們探討了 Delta Lake 的基礎知識,包括其主要特性和功能。
Delta Lake 將原始資料湖轉換為可靠的高效能平台,具有 ACID 事務、模式實施、時間旅行和統一批次/串流功能,確保任何工作負載的資料準確、一致且可存取。
與往常一樣,本文中的範例可在 GitHub 上找到。