使用Apache Kafka進行數據建模
1.概述
在本教程中,我們將探索使用Apache Kafka進行事件驅動架構的數據建模領域。
2.配置Kafka集群
一個Kafka集群由在Zookeeper集群中註冊的多個Kafka代理組成。為了簡單起見,我們將使用Confluent發布的現成的Docker映像和docker-compose配置。
首先,讓我們下載3節點Kafka集群docker-compose.yml :
$ BASE_URL="https://raw.githubusercontent.com/confluentinc/cp-docker-images/5.3.3-post/examples/kafka-cluster"
$ curl -Os "$BASE_URL"/docker-compose.yml接下來,讓我們啟動Zookeeper和Kafka代理節點:
$ docker-compose up -d最後,我們可以驗證所有Kafka經紀人都在工作:
$ docker-compose logs kafka-1 kafka-2 kafka-3 | grep started
kafka-1_1 | [2020-12-27 10:15:03,783] INFO [KafkaServer id=1] started (kafka.server.KafkaServer)
kafka-2_1 | [2020-12-27 10:15:04,134] INFO [KafkaServer id=2] started (kafka.server.KafkaServer)
kafka-3_1 | [2020-12-27 10:15:03,853] INFO [KafkaServer id=3] started (kafka.server.KafkaServer)3.活動基礎
在承擔事件驅動系統的數據建模任務之前,我們需要了解一些概念,例如事件,事件流,生產者-消費者和主題。
3.1。事件
卡夫卡世界中的事件是域世界中發生的事情的信息日誌。它通過將信息記錄為鍵值對消息以及其他一些屬性(例如時間戳,元信息和標頭)來完成此操作。
假設我們正在建模一個國際象棋遊戲;那麼一個事件可能就是一個舉動:
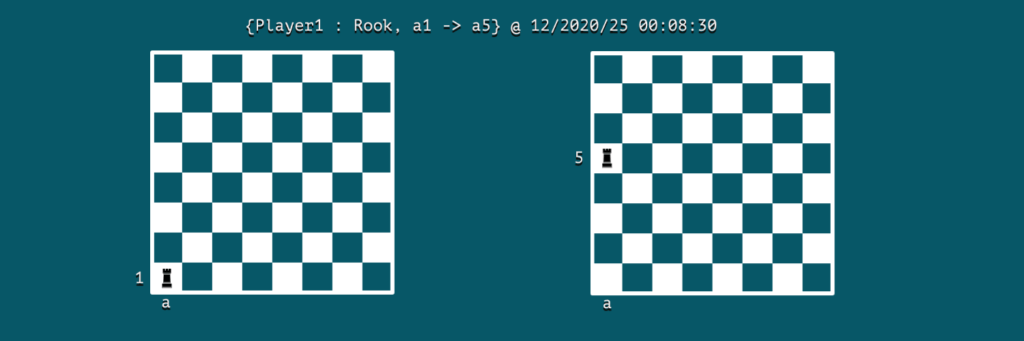
我們可以注意到事件包含了參與者的關鍵信息,動作和事件發生的時間。在這種情況下, Player1是演員,並且動作是在12/2020/25 00:08:30將菜鳥從單元格a1移動到a5 。
3.2 消息流
Apache Kafka是一種流處理系統,可將事件捕獲為消息流。在我們的國際象棋遊戲中,我們可以將事件流視為玩家下棋的記錄。
在每個事件發生時,板的快照將代表其狀態。通常,使用傳統的表模式存儲對象的最新靜態狀態。
另一方面,事件流可以幫助我們以事件的形式捕獲兩個連續狀態之間的動態變化。如果我們播放一系列這些不可變的事件,則可以從一個狀態轉換到另一個狀態。這就是事件流和傳統表之間的關係,通常稱為流表對偶。
讓我們在棋盤上通過兩個連續事件可視化事件流:
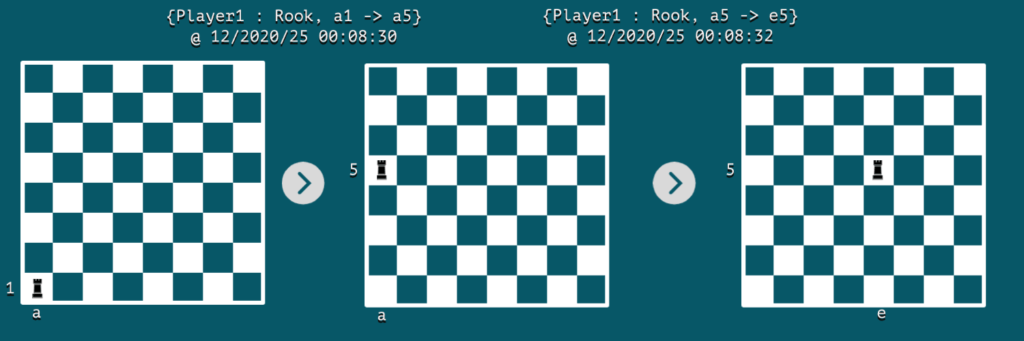
4.主題
在本節中,我們將學習如何對通過Apache Kafka路由的消息進行分類。
4.1。分類
在諸如Apache Kafka之類的消息傳遞系統中,任何產生事件的事件通常稱為生產者。那些閱讀和消費這些消息的人稱為消費者。
在現實情況中,每個生產者可以生成不同類型的事件,因此,如果我們希望他們過濾與他們相關的消息並忽略其餘消息,那麼這將浪費大量的精力。
為了解決這個基本問題, Apache Kafka使用的主題本質上是屬於在一起的消息組。結果,消費者可以在消費事件消息的同時提高生產力。
在我們的國際象棋棋盤示例中,可以使用一個主題將所有chess-moves分組到chess-moves主題下:
$ docker run \
--net=host --rm confluentinc/cp-kafka:5.0.0 \
kafka-topics --create --topic chess-moves \
--if-not-exists
--zookeeper localhost:32181
Created topic "chess-moves".4.2。生產者-消費者
現在,讓我們看看生產者和消費者如何使用Kafka的主題進行消息處理。我們將使用Kafka發行版隨附的kafka-console-producer和kafka-console-consumer實用程序進行演示。
讓我們啟動一個名為kafka-producer的容器,其中將調用producer實用程序:
$ docker run \
--net=host \
--name=kafka-producer \
-it --rm \
confluentinc/cp-kafka:5.0.0 /bin/bash
# kafka-console-producer --broker-list localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves \
--property parse.key=true --property key.separator=:
同時,我們可以啟動一個名為kafka-consumer的容器,在其中調用消費者工具:
$ docker run \
--net=host \
--name=kafka-consumer \
-it --rm \
confluentinc/cp-kafka:5.0.0 /bin/bash
# kafka-console-consumer --bootstrap-server localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves --from-beginning \
--property print.key=true --property print.value=true --property key.separator=:
現在,讓我們記錄一下製作人中的一些遊戲動作:
>{Player1 : Rook, a1->a5}當使用者處於活動狀態時,它將使用密鑰Player1接收以下消息:
{Player1 : Rook, a1->a5}5.分區
接下來,讓我們看看如何使用分區創建消息的進一步分類並提高整個系統的性能。
5.1。並發
我們可以將一個主題劃分為多個分區,並調用多個使用者以使用來自不同分區的消息。通過啟用這種並發行為,可以提高系統的整體性能。
默認情況下,除非在創建主題時明確指定,Kafka會創建主題的單個分區。但是,對於先前存在的主題,我們可以增加分區的數量。讓我們將chess-moves主題的分區號設置為3 :
$ docker run \
--net=host \
--rm confluentinc/cp-kafka:5.0.0 \
bash -c "kafka-topics --alter --zookeeper localhost:32181 --topic chess-moves --partitions 3"
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!5.2。分區鍵
在一個主題內,Kafka使用分區鍵跨多個分區處理消息。一方面,生產者隱式使用它來將消息路由到分區之一。另一方面,每個使用者都可以從特定分區讀取消息。
默認情況下,生產者將生成鍵的哈希值,後跟具有分區數的模數。然後,它將消息發送到由計算出的標識符標識的分區。
讓我們使用kafka-console-producer實用工具創建新的事件消息,但是這次我們將記錄兩個玩家的動作:
# kafka-console-producer --broker-list localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves \
--property parse.key=true --property key.separator=:
>{Player1: Rook, a1 -> a5}
>{Player2: Bishop, g3 -> h4}
>{Player1: Rook, a5 -> e5}
>{Player2: Bishop, h4 -> g3}現在,我們可以有兩個使用者,一個從分區1讀取,另一個從分區2讀取:
# kafka-console-consumer --bootstrap-server localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves --from-beginning \
--property print.key=true --property print.value=true \
--property key.separator=: \
--partition 1
{Player2: Bishop, g3 -> h4}
{Player2: Bishop, h4 -> g3}我們可以看到Player2的所有移動都被記錄在partition-1中。同樣,我們可以檢查Player1的移動是否已記錄到分區0中。
6.水平擴展
我們如何概念化主題和分區對於水平擴展至關重要。一方面,主題更多是數據的預定義分類。另一方面,分區是動態發生的數據動態分類。
此外,在一個主題中可以配置多少個分區方面存在實際限制。這是因為每個分區都映射到代理節點文件系統中的目錄。當我們增加分區數量時,我們也增加了操作系統上打開文件句柄的數量。
根據經驗, Confluent的**專家 **建議將每個代理的分區數限制為100 x b x r ,其中b是Kafka群集中的代理數, r是複制因子。
7.結論
在本文中,我們使用Docker環境介紹了使用Apache Kafka進行消息處理的系統的數據建模基礎。在對事件,主題和分區有基本的了解之後,我們現在就可以概念化事件流並進一步使用此體系結構範例。