Tika教學
Apache Tika 是什麼?
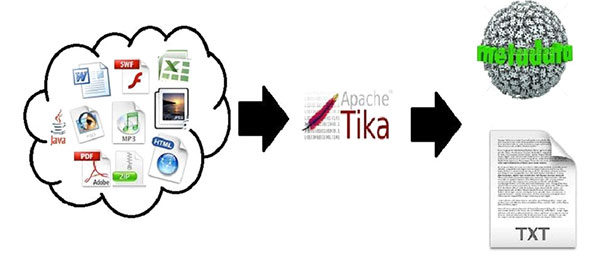
Apache Tika用於文件類型檢測和從各種格式的文件內容提取的庫。
在內部,Tika使用現有的各種文件解析器和文檔類型的檢測技術來檢測和提取數據。
使用Tika,人們可以開發出通用型檢測器和內容提取到的不同類型的文件,如電子表格,文本文件,圖像,PDF文件甚至多媒體輸入格式,在一定程度上提取結構化文本以及元數據。
Tika提供用於解析不同文件格式的一個通用API。它採用83個現有的專業解析器庫,爲每個文檔類型。
所有這些解析器庫是根據一個叫做Parser接口單一接口封裝。
爲什麼用Tika?
據filext.com網站統計,大約有1.5萬至51K的內容類型,並且這個數字還在與日俱增。數據被存儲在不同的格式,如文本文檔,excel表格,PDF,圖像和多媒體文件,僅舉幾例。因此,應用程序如搜索引擎和內容管理系統需要從這些文檔類型容易提取數據的額外的支持。Apache Tika 通過提供一個通用的API來檢測並提取多種文件格式的數據服務達到這一目的。
Apache Tika 應用
有各種各樣的應用程序使用Apache Tika。在這裏,我們將討論嚴重依賴Apache Tika幾個突出的應用。
搜索引擎
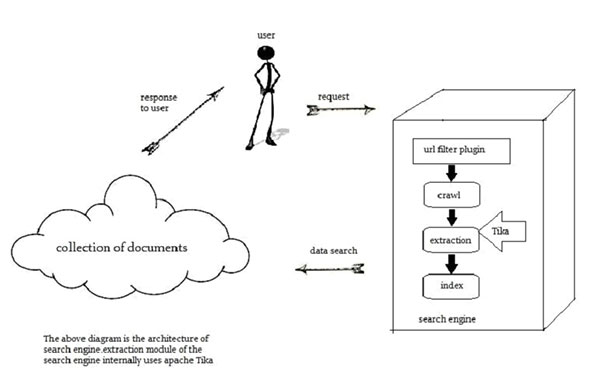
開發搜索引擎索引的數字文檔的文本內容使Tika被廣泛使用。
搜索引擎是用於搜索的網頁信息和索引文件的信息處理系統。
抓取工具是通過Web抓取獲取使用一些索引技術被索引的文件搜索引擎的重要組成部分。此後,抓取工具傳送這些索引文件提取成分。
提取成分的職責是提取文檔中的文本和元數據。這樣提取的內容和元數據是對搜索引擎非常有用。該提取組件包含在Tika中。
然後將提取的內容被傳遞到使用它來建立一個搜索索引搜索引擎的索引器。此外,該搜索引擎使用許多其它方式提取的內容也是如此。
文檔分析
在人工智能領域,有一定的工具來自動分析文件在語義層面,並提取各種數據來自他們。
在這種應用中,這些文件是基於在文檔的所提取的內容的突出方面進行分類。
這些工具使用提Tika內容提取分析從純文本到不同的數字文檔文件。
數字資產管理
有些組織管理他們的數字資產,如使用一種稱爲數字資產管理(DAM)的特殊應用程序的照片,電子書,繪圖,音樂和視頻。
這樣的應用程序採取的文件類型檢測器和元數據提取器的幫助下到的各種文件進行分類。
內容分析
像亞馬遜網站建議根據自己的興趣剛剛發佈了他們的網站內容向個人用戶。要做到這一點,這些網站遵循機器學習技術,或採取了類似Facebook的社交媒體網站的幫助下,以提取所需的信息,如喜歡和用戶的利益。此收集到的信息將在HTML標籤或其他格式需要另外的內容類型檢測和提取的形式。
爲一個文件,內容分析,我們有實現,如UIMA和Mahout的機器學習技術的技術。這些技術是在聚類和分析中的文件中的數據是有用的。
Apache Mahout是一個框架,它提供基於Apache Hadoop的ML算法- 一個雲計算平臺。 Mahout 提供了下面的某個集羣和過濾技術的架構。按照這個架構,程序員可以編寫自己的ML算法,通過採取各種文本和元數據的組合來產生建議。提供輸入這些算法,最近Mahout的版本使用Tika提取二進制內容的文本和元數據。
Apache UIMA 分析和處理各種編程語言,併產生UIMA註解。在內部,它使用提卡註解者抽取文檔中的文本和元數據。
歷史
年份
開發
2006
Tika的想法是在Lucene項目管理委員會之前設計的。
2006
Tika及其在Jackrabbit項目有用的概念進行了討論。
2007
Tika進入Apache孵化器。
2008
版本0.1和0.2發佈,Tika從孵化器到Lucene子項目獨立。
2009
版本0.3,0.4,和0.5發佈。
2010
版本0.6和0.7發佈,Tika進入Apache的頂級項目。
2011
Tika1.0發佈,並Tika的書籍「Tika in Action」也在同一年被髮布。