YugabyteDB 快速指南
1. 概述
在本文中,我們將研究 YugabyteDB。 YugabyteDB 是一個 SQL 數據庫,旨在解決當今分佈式雲原生應用程序面臨的困難。 Yugabyte DB為企業和開發者提供開源、高性能的數據庫。
2. YugabyteDB架構
YugabyteDB 是一個分佈式 SQL 數據庫。更準確地說,它是一個關係數據庫,提供跨網絡服務器集群部署的單一邏輯數據庫。
大多數關係數據庫的工作方式如下:
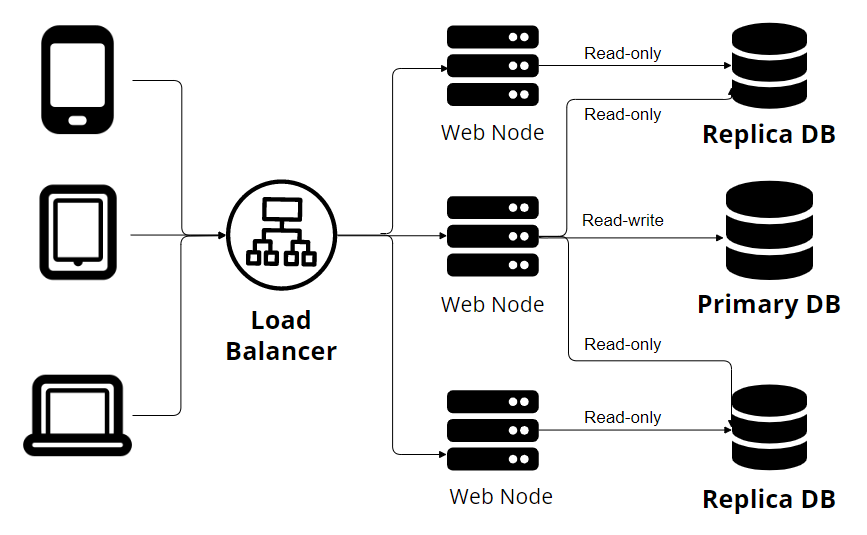
上圖代表單主複製。您可以在圖中看到多個設備通過負載均衡器發出請求。此外,我們有多個 Web 節點連接到多個數據庫節點。一個主節點寫入數據庫,而其他副本僅接受只讀事務。這個原則運作良好。一種事實來源(一個主節點)使我們能夠避免數據衝突。但是,YugabyteDB 的情況並非如此:
與傳統的數據庫複製系統不同,YugabyteDB利用分片**來確保高可用性和容錯能力。**分片涉及將數據分佈在集群中的多個節點上,其中每個節點負責存儲一部分數據。 YugabyteDB通過將數據分割成更小的塊並分佈在多個節點之間,實現了並行性和負載均衡。如果發生節點故障,YugabyteDB 的分片特性可確保其餘節點可以無縫地接管提供數據服務的責任,保持不間斷的可用性。
3. 數據庫示例
3.1. Maven 依賴項
我們首先將以下 依賴項添加到 Maven 項目中:
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>YugabyteDB 與 PostgreSQL 兼容,因此我們可以輕鬆地在示例中使用PostgreSQL 連接器。
3.2.數據庫配置
根據我們的應用程序需求,有多種方法來安裝 Yugabyte 。但是,為了簡單起見,我們將為 YugabyteDB 實例使用 Docker 映像。
我們首先將 Docker 鏡像拉到本地:
$ docker pull yugabytedb/yugabyte:latest之後,我們可以啟動 YugabyteDB 實例:
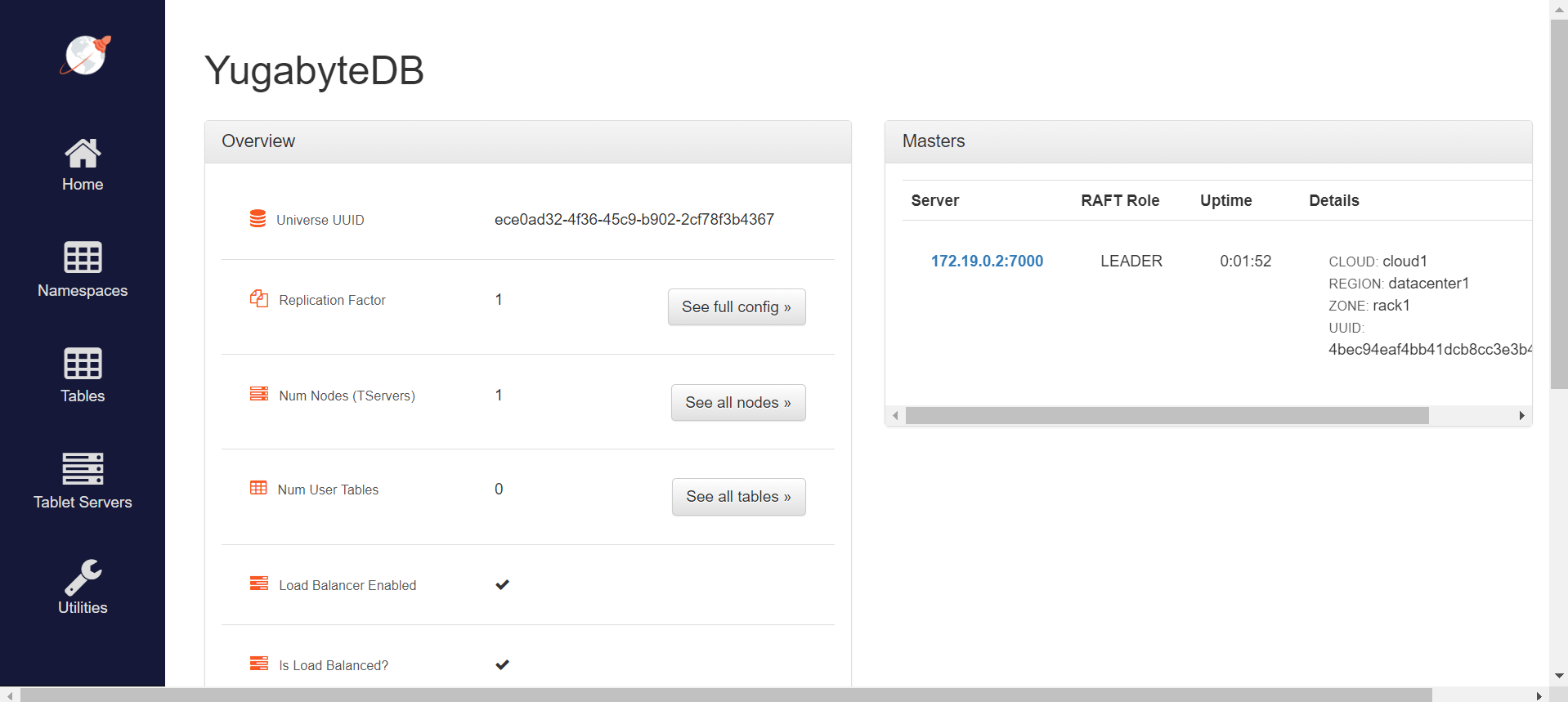
$ docker run -d --name yugabyte -p7000:7000 -p9000:9000 -p5433:5433 yugabytedb/yugabyte:latest bin/yugabyted start --daemon=false現在我們有了一個全功能的 YugabyteDB 實例。我們可以訪問http://localhost:7000/來查看管理 Web 服務器 UI:
現在我們可以開始在application.properties文件中配置數據庫連接。
spring.datasource.url=jdbc:postgresql://localhost:5433/yugabyte
spring.datasource.username=yugabyte
spring.datasource.password=yugabyte
spring.jpa.hibernate.ddl-auto=create我們可以看到配置是最少的,類似於 PostgreSQL 數據庫的連接。我們還使用值create設置spring.jpa.hibernate.ddl-auto屬性。這意味著 Hibernate 將負責創建與我們的實體匹配的表。我們堅持使用最少的必要配置。
3.3.創建表
現在,配置數據庫後,我們可以開始創建實體。
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String name;
// getters, setters, toString()
}現在,我們可以運行我們的應用程序,並且用戶表將自動創建。我們可以通過進入管理 UI 並選擇“表”部分來檢查它:
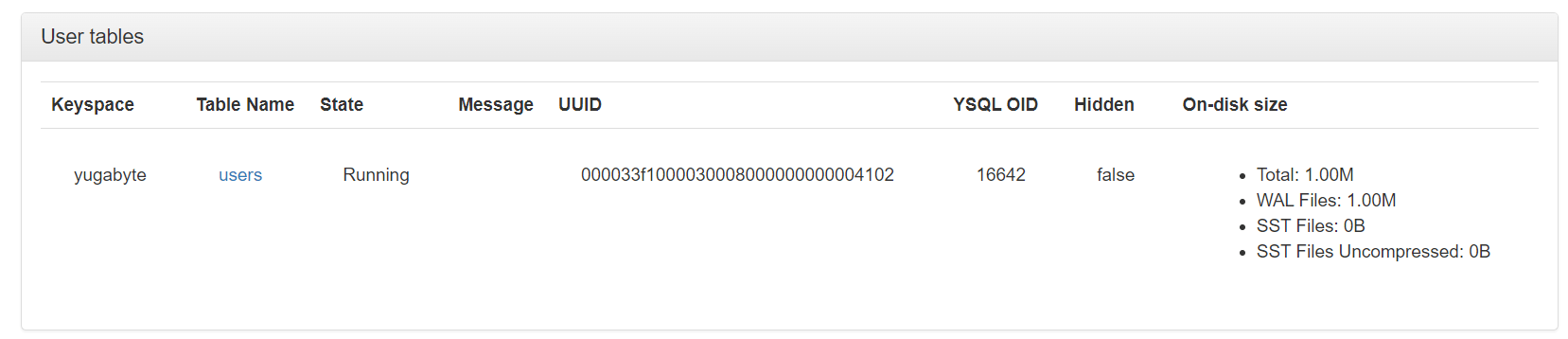
在這裡我們可以看到我們創建了一張表。此外,我們可以通過單擊表的名稱來獲取有關該表的更多信息。
我們還可以使用任何與 PostgreSQL 兼容的管理工具(例如pgAdmin )連接到我們的數據庫。
3.4.讀取和寫入數據
配置和表創建之後,我們需要創建一個存儲庫 - 擴展現有的JPARepository接口:
public interface UserRepository extends JpaRepository<User, Long> {
}JPARepository是 Spring Data JPA 框架的一部分,它為我們提供了一組用於簡化數據庫訪問的抽象和實用程序。此外,它還提供了save() 、 findById()和delete()等方法,允許與數據庫進行快速而簡單的交互。
@Test
void givenTwoUsers_whenPersistUsingJPARepository_thenUserAreSaved() {
User user1 = new User();
user1.setName("Alex");
User user2 = new User();
user2.setName("John");
userRepository.save(user1);
userRepository.save(user2);
List<User> allUsers = userRepository.findAll();
assertEquals(2, allUsers.size());
}上面的示例說明了數據庫中的兩個簡單插入以及從表中檢索所有數據的查詢。為了簡單起見,我們編寫了一個測試來檢查用戶是否保留在數據庫中。
運行測試後,我們將得到測試已通過的確認,這意味著我們已成功插入和查詢用戶。
3.5.使用多個集群寫入數據
該數據庫的優勢之一是其高容錯性和恢復能力。我們在上一個示例中看到了一個簡單的場景,但我們都知道我們通常需要運行多個數據庫實例。我們將在下面的示例中看到 YugabyteDB 如何管理它。
我們首先為集群創建一個 Docker 網絡:
$ docker network create yugabyte-network之後,我們將創建主 YugabyteDB 節點:
$ docker run -d --name yugabyte1 --net=yugabyte-network -p7000:7000 -p9000:9000 -p5433:5433 yugabytedb/yugabyte:latest bin/yugabyted start --daemon=false除此之外,我們還可以添加兩個節點,這樣我們就有一個三節點集群:
$ docker run -d --name yugabyte2 --net=yugabyte-network yugabytedb/yugabyte:latest bin/yugabyted start --join=yugabyte1 --daemon=false
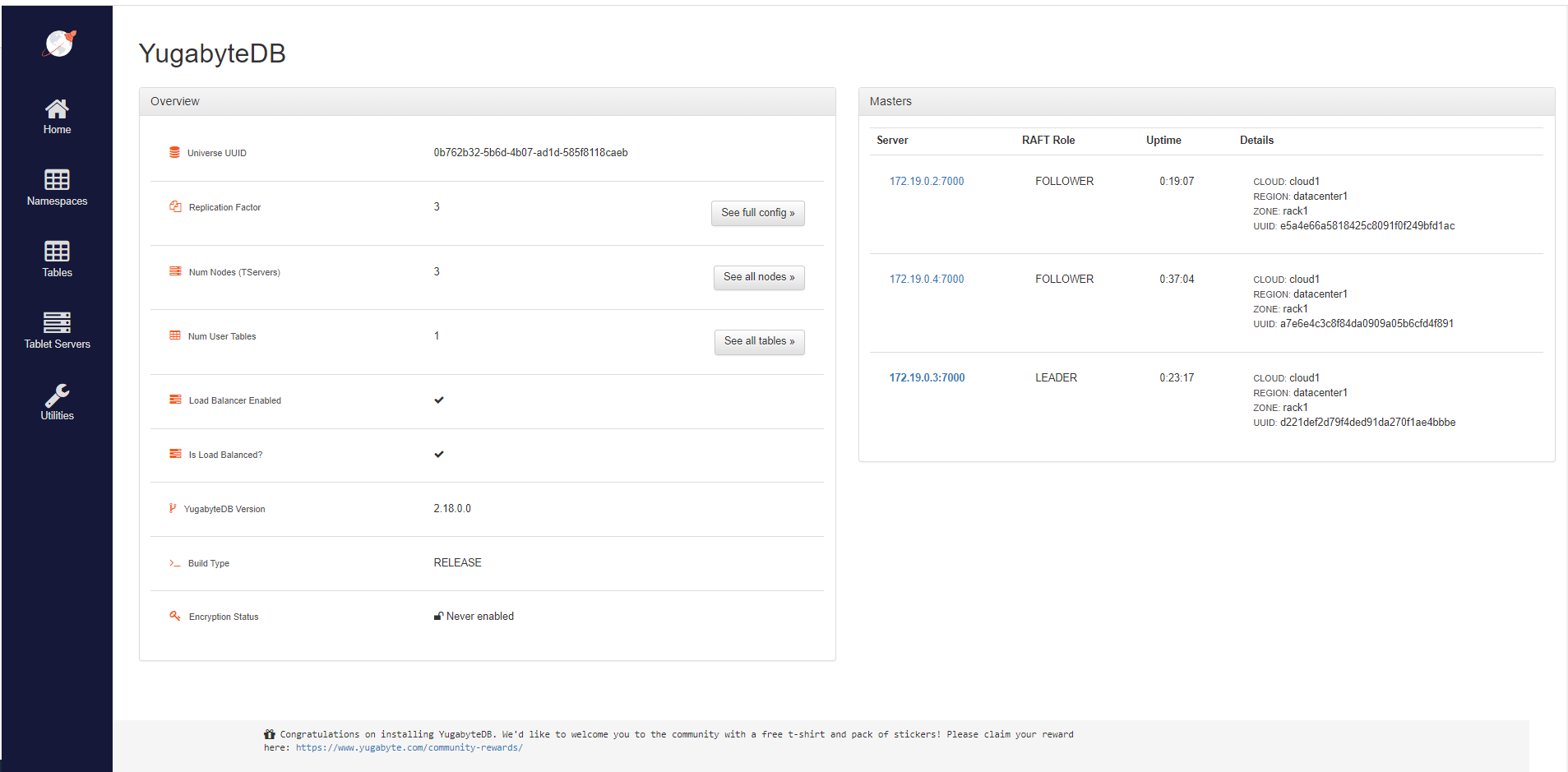
$ docker run -d --name yugabyte3 --net=yugabyte-network yugabytedb/yugabyte:latest bin/yugabyted start --join=yugabyte1 --daemon=false現在,如果我們打開在端口 7000 運行的管理 UI,我們可以看到復制因子為 3。這意味著數據在所有三個數據庫集群節點上共享。更準確地說,如果一個節點包含對象的主副本,則其他兩個節點將保留該對象的副本。
對於本示例,我們將實現CommandLineRunner接口。在它的幫助下,通過重寫run(String…args)方法,我們可以編寫在實例化 Spring 應用程序上下文後在應用程序啟動時調用的代碼。
@Override
public void run(String... args) throws InterruptedException {
int iterationCount = 1_000;
int elementsPerIteration = 100;
for (int i = 0; i < iterationCount; i++) {
for (long j = 0; j < elementsPerIteration; j++) {
User user = new User();
userRepository.save(user);
}
Thread.sleep(1000);
}
}使用此腳本,我們將在一行中插入連續批次的元素,它們之間有一秒鐘的暫停。我們想要觀察數據庫如何在節點之間分配負載。
首先,我們將運行腳本,進入管理控制台並導航到Tablet Servers選項卡。
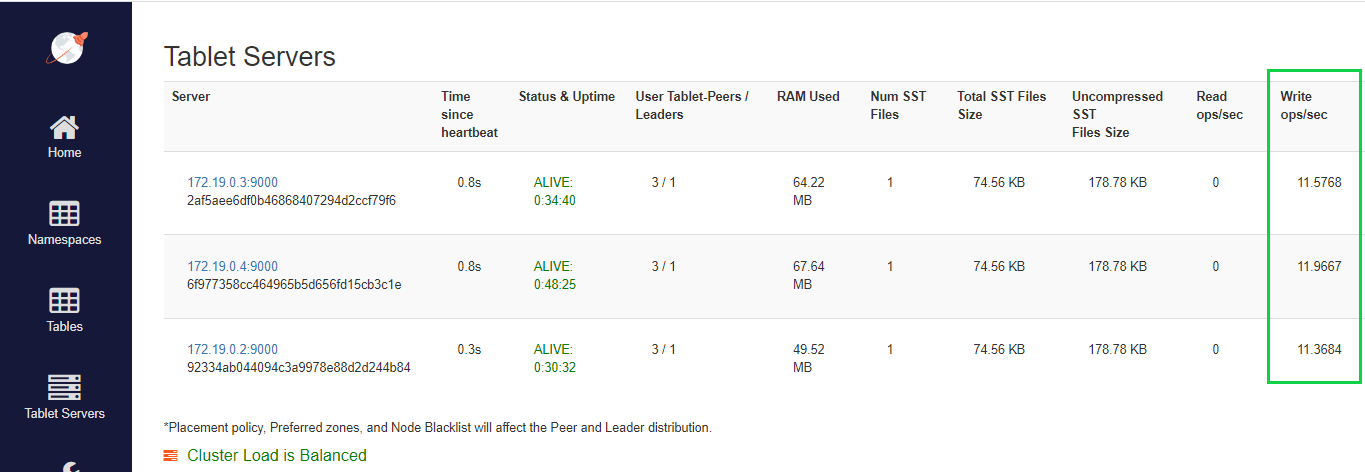
在這裡我們可以看到,即使使用最小的負載平衡配置,YugabyteDB 也可以在集群之間分配所有負載。
3.6.容錯能力
我們知道事情不可能一直十全十美。因此,我們將模擬數據庫集群發生故障。現在,我們可以再次運行該應用程序,但這一次我們將在執行過程中停止一個集群:
$ docker stop yugabyte2現在,如果我們稍等一下並再次訪問 Tablet Servers 頁面,我們可以看到停止的容器被標記為死亡。之後,所有負載在剩餘集群之間進行平衡。
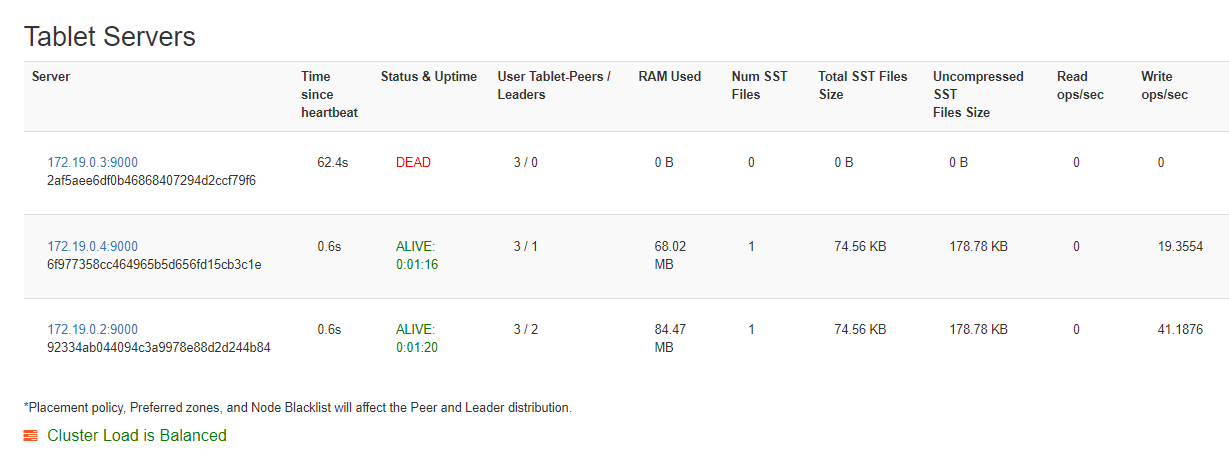
YugabyteDB 基於心跳的機制使這成為可能。這種心跳機制涉及不同節點之間的定期通信,其中每個節點向其對等節點發送心跳以指示其活躍度。如果節點在一定的超時時間內未能響應心跳,則認為該節點死亡。
4。結論
在本文中,我們了解了使用 Spring Data 的 YugabyteDB 的基礎知識。我們看到 YugabyteDB 不僅使擴展應用程序變得更容易,而且還具有自動容錯功能。
上述示例的源代碼可以在 GitHub 上找到。