@OneToMany JPA 中的列表與設置
1. 概述
Spring JPA 和 Hibernate 為無縫資料庫通訊提供了強大的工具。但是,隨著客戶端將更多控制權委託給框架(包括查詢產生),結果可能與我們的預期相去甚遠。
人們通常會混淆該使用什麼,是具有to-many關係的Lists還是Sets 。通常,這種混亂會因為 Hibernate 使用相似的名稱來表示其套件、清單和集合而加劇,但背後的含義略有不同。
在大多數情況下, Sets更適合one-to-many或many-to-many關係。然而,它們具有我們應該意識到的特定性能影響。
在本教程中,我們將在實體關係的上下文中了解清單和集合之間的區別,並回顧幾個不同複雜性的範例。此外,我們將確定每種方法的優缺點。
2. 測試
我們將使用專用函式庫來測試請求數量。檢查日誌並不是一個好的解決方案,因為它不是自動化的,並且可能僅適用於簡單的範例。當請求產生數十甚至數百個查詢時,使用日誌的效率不夠高。
首先,我們需要[io.hypersistence](https://mvnrepository.com/artifact/io.hypersistence) .請注意,工件 ID 中的數字是 Hibernate 版本:
<dependency>
<groupId>io.hypersistence</groupId>
<artifactId>hypersistence-utils-hibernate-63</artifactId>
<version>3.7.0</version>
</dependency>此外,我們將使用 util 庫進行日誌分析:
<dependency>
<groupId>com.vladmihalcea</groupId>
<artifactId>db-util</artifactId>
<version>1.0.7</version>
</dependency>我們可以使用這些庫進行探索性測試並涵蓋應用程式的關鍵部分。這樣,我們確保實體類別中的變更不會在查詢產生中產生一些看不見的副作用。
我們應該使用提供的實用程式包裝我們的資料來源以使其正常運作。我們可以使用 BeanPostProcessor 來做到這一點:
@Component
public class DataSourceWrapper implements BeanPostProcessor {
public Object postProcessBeforeInitialization(Object bean, String beanName) {
return bean;
}
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof DataSource originalDataSource) {
ChainListener listener = new ChainListener();
SLF4JQueryLoggingListener loggingListener = new SLF4JQueryLoggingListener();
loggingListener.setQueryLogEntryCreator(new InlineQueryLogEntryCreator());
listener.addListener(loggingListener);
listener.addListener(new DataSourceQueryCountListener());
return ProxyDataSourceBuilder
.create(originalDataSource)
.name("datasource-proxy")
.listener(listener)
.build();
}
return bean;
}
}其餘的很簡單。在我們的測試中,我們將使用SQLStatementCountValidator來驗證查詢的數量和類型。
3. 域名
為了使範例更具相關性且更易於理解,我們將使用社交網路網站的模型。我們將在群組、用戶、貼文和評論之間建立不同的關係。
但是,我們將逐步增加複雜性,並添加實體以突出差異和效能效果。這很重要,因為只有少數關係的簡單模型無法提供完整的圖片。同時,過於複雜的訊息可能會淹沒訊息,使其難以理解。
對於這些範例,我們將僅使用急切獲取類型來實現to-many關係。一般來說,當我們使用延遲獲取時, Lists和Sets行為類似。
在視覺效果中,我們將使用Iterable作為to-many字段類型。這樣做只是為了簡潔,因此我們不需要為Lists和Sets重複相同的視覺效果。我們將在每個部分中明確定義專用類型並在程式碼中顯示它。
4. 用戶和貼文
首先,我們只考慮域的一部分。在這裡,我們將僅考慮用戶和帖子:
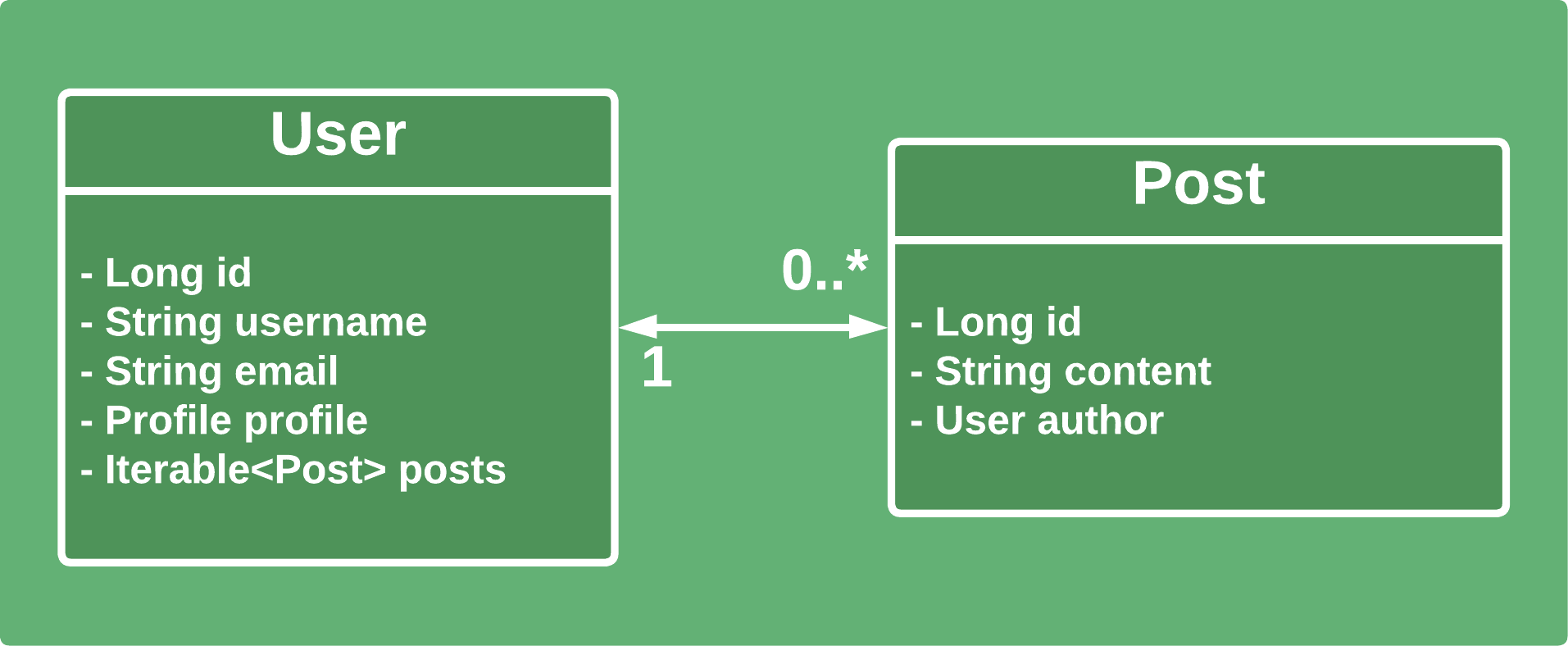
對於第一個範例,我們將在使用者和貼文之間建立簡單的雙向關係。用戶可以有很多帖子。同時,一篇貼文只能有一個使用者作為作者。
4.1. Lists和Sets連接
讓我們檢查一下當我們只請求一個使用者時查詢的行為。我們將考慮Set和List的以下兩個場景:
@Data
@Entity
public class User {
// Other fields
@OneToMany(cascade = CascadeType.ALL, mappedBy = "author", fetch = FetchType.EAGER)
protected List<Post> posts;
}基於Set的User看起來非常相似:
@Data
@Entity
public class User {
// Other fields
@OneToMany(cascade = CascadeType.ALL, mappedBy = "author", fetch = FetchType.EAGER)
protected Set<Post> posts;
}在取得User時,Hibernate 會使用 LEFT JOIN 產生單一查詢,以一次性取得所有資訊。對於這兩種情況都是如此:
SELECT u.id, u.email, u.username, p.id, p.author_id, p.content
FROM simple_user u
LEFT JOIN post p ON u.id = p.author_id
WHERE u.id = ?雖然我們只有一個查詢,但每一行都會重複使用者的資料。這意味著我們會看到特定用戶的 ID、電子郵件和用戶名,次數與特定用戶發布的貼文次數一樣多:
| 使用者 ID | u.email | u.使用者名稱 | p.id | p.author_id | p.內容 |
|---|---|---|---|---|---|
| 101 | [電子郵件受保護] | 用戶101 | 1 | 101 | “用戶101發文1” |
| 101 | [電子郵件受保護] | 用戶101 | 2 | 101 | “用戶101發文2” |
| 102 | [電子郵件受保護] | 用戶102 | 3 | 102 | “用戶102發文1” |
| 102 | [電子郵件受保護] | 用戶102 | 4 | 102 | “用戶102發文2” |
| 103 | [電子郵件受保護] | 用戶103 | 5 | 103 | “用戶103發文1” |
| 103 | [電子郵件受保護] | 用戶103 | 6 | 103 | “用戶103發文2” |
如果用戶表有很多列或帖子,這可能會產生效能問題。我們可以透過明確指定獲取模式來解決這個問題。
4.2. Lists和Sets N +1
同時,在獲取多個用戶時,我們遇到了臭名昭著的N +1 問題。這對於基於List的Users來說是正確的:
@Test
void givenEagerListBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequests() {
List<User> users = getService().findAll();
assertSelectCount(users.size() + 1);
}此外,對於基於Set的Users也是如此:
@Test void givenEagerSetBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequests() { List<User> users = getService().findAll(); assertSelectCount(users.size() + 1); }
只有兩種查詢。第一個獲取所有用戶:
SELECT u.id, u.email, u.username
FROM simple_user u以及獲取每個User的貼文的N個後續請求:
SELECT p.id, p.author_id, p.content
FROM post p
WHERE p.author_id = ?因此,對於這些類型的關係, Lists和Sets之間沒有任何區別。
5. 群組、使用者和貼文
讓我們考慮更複雜的關係並將群組添加到我們的模型中。他們與用戶創建單向的many-to-many關係:
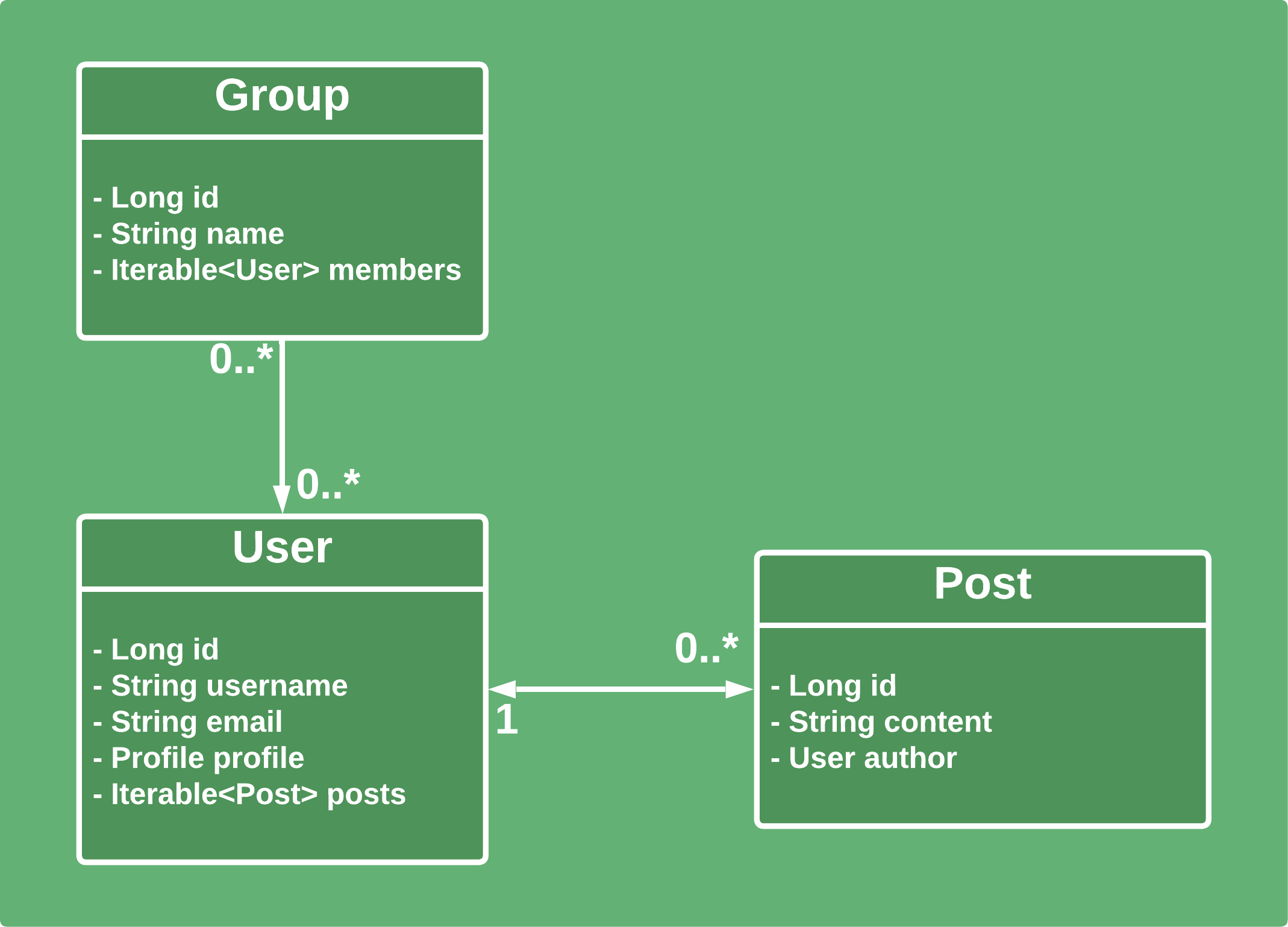
由於Users和Posts之間的關係保持不變,舊的測試將有效並產生相同的結果。讓我們為組創建類似的測試。
5.1. Lists和N +1
我們將擁有以下具有ManyToMany關係的Group類別:
@Data
@Entity
public class Group {
@Id
private Long id;
private String name;
@ManyToMany(fetch = FetchType.EAGER)
private List<User> members;
}讓我們嘗試取得所有群組:
@Test
void givenEagerListBasedGroup_whenFetchingAllGroups_thenIssueNPlusMPlusOneRequests() {
List<Group> groups = groupService.findAll();
Set<User> users = groups.stream().map(Group::getMembers).flatMap(List::stream).collect(Collectors.toSet());
assertSelectCount(groups.size() + users.size() + 1);
}Hibernate 將為每個群組發出額外的查詢以獲取成員,並為每個成員發出額外的查詢以獲取他們的帖子。因此,我們將有三種類型的查詢:
SELECT g.id, g.name
FROM interest_group g
SELECT gm.interest_group_id, u.id, u.email, u.username
FROM interest_group_members gm
JOIN simple_user u ON u.id = gm.members_id
WHERE gm.interest_group_id = ?
SELECT p.author_id, p.id, p.content
FROM post p
WHERE p.author_id = ?總的來說,我們將收到 1 + N + M數量的請求。 N是組的數量, M是這些組中唯一使用者的數量。讓我們嘗試取得單一群組:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerListBasedGroup_whenFetchingAllGroups_thenIssueNPlusOneRequests(Long groupId) {
Optional<Group> group = groupService.findById(groupId);
assertThat(group).isPresent();
assertSelectCount(1 + group.get().getMembers().size());
}我們也會遇到類似的情況,但我們將使用LEFT JOIN在單一查詢中取得所有User資料。因此,只有兩種類型的查詢:
SELECT g.id, gm.interest_group_id, u.id, u.email, u.username, g.name
FROM interest_group g
LEFT JOIN (interest_group_members gm JOIN simple_user u ON u.id = gm.members_id)
ON g.id = gm.interest_group_id
WHERE g.id = ?
SELECT p.author_id, p.id, p.content
FROM post p
WHERE p.author_id = ?總的來說,我們將有N + 1 個請求,其中N是群組成員的數量。
5.2 Sets和笛卡爾積
在使用Sets時,我們會看到不同的情況。讓我們檢查一下基於Set的Group類別:
@Data
@Entity
public class Group {
@Id
private Long id;
private String name;
@ManyToMany(fetch = FetchType.EAGER)
private Set<User> members;
}取得所有群組將產生與基於List的群組略有不同的結果:
@Test
void givenEagerSetBasedGroup_whenFetchingAllGroups_thenIssueNPlusOneRequests() {
List<Group> groups = groupService.findAll();
assertSelectCount(groups.size() + 1);
}而不是前面範例中的N + M + 1。我們將只有N + 1,但會得到更複雜的查詢。我們仍然有一個單獨的查詢來獲取所有群組,但 Hibernate 使用兩個 JOIN 在單一查詢中獲取用戶及其帖子:
SELECT g.id, g.name
FROM interest_group g
SELECT u.id,
u.username,
u.email,
p.id,
p.author_id,
p.content,
gm.interest_group_id,
FROM interest_group_members gm
JOIN simple_user u ON u.id = gm.members_id
LEFT JOIN post p ON u.id = p.author_id
WHERE gm.interest_group_id = ?儘管我們減少了查詢數量,但由於 JOIN 以及隨後的笛卡爾積,結果集可能包含重複資料。我們將獲得群組中所有用戶的重複群組信息,並且所有這些資訊都將為每個用戶帖子重複:
| 使用者 ID | u.使用者名稱 | u.email | p.id | p.author_id | p.內容 | gm.interest_group_id |
|---|---|---|---|---|---|---|
| 301 | 用戶301 | [電子郵件受保護] | 201 | 301 | “用戶301的貼文1” | 101 |
| 第302章 | 用戶302 | [電子郵件受保護] | 第202章 | 第302章 | “用戶302的貼文1” | 101 |
| 303 | 用戶303 | [電子郵件受保護] | 無效的 | 無效的 | 無效的 | 101 |
| 304 | 用戶304 | [電子郵件受保護] | 203 | 304 | “用戶304的貼文1” | 102 |
| 305 | 用戶305 | [電子郵件受保護] | 204 | 305 | “用戶305的貼文1” | 102 |
| 306 | 用戶306 | [電子郵件受保護] | 無效的 | 無效的 | 無效的 | 102 |
| 307 | 用戶307 | [電子郵件受保護] | 205 | 307 | “用戶307的貼文1” | 103 |
| 308 | 用戶308 | [電子郵件受保護] | 206 | 308 | “用戶308的貼文1” | 103 |
| 309 | 用戶309 | [電子郵件受保護] | 無效的 | 無效的 | 無效的 | 103 |
在查看先前的查詢後,很明顯為什麼獲取單一群組會發出單一請求:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerSetBasedGroup_whenFetchingAllGroups_thenCreateCartesianProductInOneQuery(Long groupId) {
groupService.findById(groupId);
assertSelectCount(1);
}我們將只使用第二個帶有 JOIN 的查詢,從而減少請求數量:
SELECT u.id,
u.username,
u.email,
p.id,
p.author_id,
p.content,
gm.interest_group_id,
FROM interest_group_members gm
JOIN simple_user u ON u.id = gm.members_id
LEFT JOIN post p ON u.id = p.author_id
WHERE gm.interest_group_id = ?5.3.使用Lists和Sets進行刪除
Sets和Lists之間的另一個有趣的區別是它們如何刪除物件。這僅適用於@ManyToMany關係。讓我們先考慮一個更簡單的Sets案例:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerListBasedGroup_whenRemoveUser_thenIssueOnlyOneDelete(Long groupId) {
groupService.findById(groupId).ifPresent(group -> {
Set<User> members = group.getMembers();
if (!members.isEmpty()) {
reset();
Set<User> newMembers = members.stream().skip(1).collect(Collectors.toSet());
group.setMembers(newMembers);
groupService.save(group);
assertSelectCount(1);
assertDeleteCount(1);
}
});
}這種行為是相當合理的,我們只是從連接表中刪除該記錄。我們將在日誌中看到只有兩個查詢:
SELECT g.id, g.name,
u.id, u.username, u.email,
p.id, p.author_id, p.content,
m.interest_group_id,
FROM interest_group g
LEFT JOIN (interest_group_members m JOIN simple_user u ON u.id = m.members_id)
ON g.id = m.interest_group_id
LEFT JOIN post p ON u.id = p.author_id
DELETE
FROM interest_group_members
WHERE interest_group_id = ? AND members_id = ?我們有一個額外的選擇只是因為測試方法不是事務性的,並且原始組沒有儲存在我們的持久性上下文中。
整體而言, Sets行為方式與我們假設的一致。現在,讓我們檢查Lists行為:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerListBasedGroup_whenRemoveUser_thenIssueRecreateGroup(Long groupId) {
groupService.findById(groupId).ifPresent(group -> {
List<User> members = group.getMembers();
int originalNumberOfMembers = members.size();
assertSelectCount(ONE + originalNumberOfMembers);
if (!members.isEmpty()) {
reset();
members.remove(0);
groupService.save(group);
assertSelectCount(ONE + originalNumberOfMembers);
assertDeleteCount(ONE);
assertInsertCount(originalNumberOfMembers - ONE);
}
});
}這裡,我們有幾個查詢:SELECT、DELETE 和 INSERT。問題是 Hibernate 從連接表中刪除整個群組並重新建立它。同樣,由於測試方法中缺乏持久性上下文,我們有初始選擇語句:
SELECT u.id, u.email, u.username, g.name,
g.id, gm.interest_group_id,
FROM interest_group g
LEFT JOIN (interest_group_members gm JOIN simple_user u ON u.id = gm.members_id)
ON g.id = gm.interest_group_id
WHERE g.id = ?
SELECT p.author_id, p.id, p.content
FROM post p
WHERE p.author_id = ?
DELETE
FROM interest_group_members
WHERE interest_group_id = ?
INSERT
INTO interest_group_members (interest_group_id, members_id)
VALUES (?, ?)程式碼將產生一個查詢來取得所有群組成員。 N請求獲取帖子,其中N是成員數。 1 個請求刪除整個群組,N-1 個請求再次新增成員。一般來說,我們可以將其視為1 + 2N。
Lists不會產生笛卡爾積,這並不是出於性能考慮。由於Lists允許重複元素,Hibernate 在區分笛卡爾重複項和集合中的重複項時存在問題。
這就是為什麼建議僅使用帶有ManyToMany註釋的Sets的原因。否則,我們應該為巨大的效能影響做好準備。
6. 完整的域名
現在,讓我們考慮一個具有許多不同關係的更現實的領域:

現在,我們有了一個相當互連的領域模型。有幾種一對多關係、雙向多對多關係和傳遞循環關係。
6.1. Lists
首先,讓我們考慮一下使用List來表示所有to-many關係的關係。讓我們嘗試從資料庫中獲取所有用戶:
@ParameterizedTest
@MethodSource
void givenEagerListBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequests(ToIntFunction<List<User>> function) {
int numberOfRequests = getService().countNumberOfRequestsWithFunction(function);
assertSelectCount(numberOfRequests);
}
static Stream<Arguments> givenEagerListBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequests() {
return Stream.of(
Arguments.of((ToIntFunction<List<User>>) s -> {
int result = 2 * s.size() + 1;
List<Post> posts = s.stream().map(User::getPosts)
.flatMap(List::stream)
.toList();
result += posts.size();
return result;
})
);
}此請求將導致許多不同的查詢。首先,我們將取得所有使用者的 ID。然後,將所有群組的請求和每個用戶的貼文分開。最後,我們將獲取有關每個帖子的資訊。
總的來說,我們將發出大量查詢,但同時,多個to-many關係之間不會有任何聯接。這樣,我們避免了笛卡爾積,並且返回的資料量較少,因為我們沒有重複項,但我們使用了更多請求。
在獲取單一使用者時,我們會遇到一個有趣的情況:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerListBasedUser_WhenFetchingOneUser_ThenUseDFS(Long id) {
int numberOfRequests = getService()
.getUserByIdWithFunction(id, this::countNumberOfRequests);
assertSelectCount(numberOfRequests);
}countNumberOfRequests方法是一個util方法,使用DFS來統計實體數量並計算請求數量:
Get all the posts for user #2
The user wrote the following posts: 1,2,3
Check all the commenters for post #1: 3,8,9,10
Get all the posts for user #10: 22
Check all the commenters for post #22: 3,6,7,10
Get all the posts for user #3: 4,5,6
Check all the commenters for post #4: 2,4,9
Get all the posts for user #9: 19,20,21
Check all the commenters for post #19: 3,4,8,9,10
Get all the posts for user #8: 16,17,18
Check all the commenters for post #16:
Check all the commenters for post #17: 2,4,9
Get all the posts for user #4: 7,8,9,10
Check all the commenters for post #7:
Check all the commenters for post #8:
Check all the commenters for post #9: 1,5,6
Get all the posts for user #1:
Get all the posts for user #5: 11,12,13,14
Check all the commenters for post #11: 2,3,8
Check all the commenters for post #12: 10
Check all the commenters for post #13: 4,9,10
Check all the commenters for post #14:
Get all the posts for user #6:
Check all the commenters for post #10: 2,5,6,8
Check all the commenters for post #18: 1,2,3,4,5
Check all the commenters for post #20:
Check all the commenters for post #21: 7
Get all the posts for user #7: 15
Check all the commenters for post #15: 1
Check all the commenters for post #5: 1,2,5,8
Check all the commenters for post #6:
Check all the commenters for post #2:
Check all the commenters for post #3: 1,3,6結果是傳遞閉包。對於 ID #2 的單一用戶,我們必須向資料庫發出 42(!) 個請求。儘管主要問題是急切的獲取類型,但如果我們使用Lists它會顯示請求數量的爆炸性增長。
當我們觸發大多數內部字段的載入時,延遲獲取可能會產生類似的問題。根據領域邏輯,這可能是有意的。此外,它也可能是偶然的,例如,錯誤地覆寫了toString(), equals(T),和hashCode()方法。
6.2. Sets
讓我們將域模型中的所有Lists更改為Sets並進行類似的測試:
@Test
void givenEagerSetBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequestsWithCartesianProduct() {
List<User> users = getService().findAll();
assertSelectCount(users.size() + 1);
}首先,我們將減少獲取所有用戶的請求,這總體上應該會更好。但是,如果我們查看請求,我們可以看到以下內容:
SELECT profile.id, profile.biography, profile.website, profile.profile_picture_url,
user.id, user.email, user.username,
user_group.members_id,
interest_group.id, interest_group.name,
post.id, post.author_id, post.content,
comment.id, comment.text, comment.post_id,
comment_author.id, comment_author.profile_id, comment_author.username, comment_author.email,
comment_author_group_member.members_id,
comment_author_group.id, comment_author_group.name
FROM profile profile
LEFT JOIN simple_user user
ON profile.id = user.profile_id
LEFT JOIN (interest_group_members user_group
JOIN interest_group interest_group
ON interest_group.id = user_group.groups_id)
ON user.id = user_group.members_id
LEFT JOIN post post ON user.id = post.author_id
LEFT JOIN comment comment ON post.id = comment.post_id
LEFT JOIN simple_user comment_author ON comment_author.id = comment.author_id
LEFT JOIN (interest_group_members comment_author_group_member
JOIN interest_group comment_author_group
ON comment_author_group.id = comment_author_group_member.groups_id)
ON comment_author.id = comment_author_group_member.members_id
WHERE profile.id = ?該查詢從資料庫中提取大量數據,並且我們為每個用戶都有一個這樣的查詢。另一件事是,由於笛卡爾積,結果集將包含重複項。獲得單一使用者會給我們類似的結果,請求更少,但結果集很大。
7. 優點和缺點
我們在本教程中使用 eager fetch 來突出顯示Lists和Sets預設行為的差異。雖然急切地加載資料可能會提高效能並簡化與資料庫的交互,但應謹慎使用。
雖然急切獲取通常被認為可以解決 N+1 問題,但情況並非總是如此。該行為取決於多種因素以及領域實體之間關係的整體結構。
由於多種原因, Sets更適合用於過多的關係。首先,在大多數情況下,不允許重複的集合完美地反映了領域模型。一個群組中不能有兩個相同的用戶,一個用戶不能有兩個相同的貼文。
另一件事是Sets比較靈活。雖然Sets的預設取得模式是建立聯接,但我們可以使用取得模式明確定義它。
使用Lists多對多關係的刪除行為會產生開銷。在小數據集上很難注意到差異,但在處理大量數據時我們可能會遇到高延遲。
為了避免這些問題,最好透過測試來覆蓋我們與資料庫互動的關鍵部分。它將確保我們的領域模型的一部分中看似微不足道的更改不會在生成的查詢中引入巨大的開銷。
八、結論
在大多數情況下,我們應該使用Sets來實現多對多關係。這為我們提供了模式可控的關係,並避免了刪除的開銷。
但是,所有有關改進領域模型的變更和想法都應該進行分析和測試。這些問題可能不會暴露在小型資料集和簡單的實體關係中。
與往常一樣,本教程中的所有程式碼都可以在 GitHub 上取得。