Spring AI 中的聊天記憶
1.概述
與 AI 應用對話時,我們通常需要類似人類的互動。因此,需要使用 LLM 模型來維護對話,而 Spring AI 則透過其聊天記憶功能來解決這個問題。
在本教程中,我們將探討 Spring AI 中提供的不同聊天記憶體選項,並提供如何將聊天記憶體與聊天用戶端整合的範例。
2. 聊天記憶
大型語言模型 (LLM) 是無狀態的,不會記憶任何內容。每個對 LLM 的提示都被視為一個獨立查詢,這意味著模型不會記住任何先前的訊息。
在人工智慧應用中,保留先前的對話對於 LLM 產生有意義的回應至關重要。這時,聊天記憶就派上用場了,它可以提供:
- 情境理解-這使得 LLM 能夠根據整個對話做出回應。
- 個人化-這有助於根據聊天記憶提供個人化的回應。
- 持久性-根據實現情況,聊天記憶可以跨多個會話持久保存。
3. 聊天記憶庫
Spring AI 提供了ChatMemory介面和一些現成的實現,幫助我們輕鬆地將聊天記憶整合到我們的應用程式中。
首先,讓我們新增 Maven spring-ai-starter-model-openai依賴項,以啟用 OpenAI 整合。此相依性也會傳遞匯入 Spring AI 核心庫:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
<version>1.0.0</version>
</dependency>當我們建立聊天記憶體時,我們必須提供ChatMemoryRepository的實現,它負責將聊天訊息持久化到儲存中:
ChatMemoryRepository chatMemoryRepository;
ChatMemory chatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(10)
.build();Spring AI 提供了不同類型的聊天記憶體儲存庫,我們可以根據專案的技術堆疊進行選擇。我們將在這裡討論其中兩種。
3.1. 記憶體儲存庫
如果我們沒有明確定義聊天內存,Spring AI 預設使用記憶體儲存。它將聊天訊息內部儲存在ConcurrentHashMap中,其中對話 ID 是鍵,值是該對話中的訊息清單:
public final class InMemoryChatMemoryRepository implements ChatMemoryRepository {
Map<String, List<Message>> chatMemoryStore = new ConcurrentHashMap();
// other methods
}記憶體儲存庫非常簡單,當我們不需要長期持久化時,它就很好用。如果需要長期持久化,我們需要選擇其他方案。
3.2. JDBC 儲存庫
JDBC 儲存庫用於將聊天訊息持久化到關聯式資料庫中。 Spring AI 內建了對多種關係型資料庫的支持,包括 MySQL、PostgreSQL、SQL Server 和 HSQLDB。
如果我們想將聊天記憶儲存在關聯式資料庫中,我們需要包含 Maven 依賴項來支援它:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-model-chat-memory-repository-jdbc</artifactId>
<version>1.0.0</version>
</dependency>每個內建支援的資料庫都有各自的方言實現,用於提供對聊天記憶體表進行 CRUD 操作的 SQL 語句。我們需要在初始化JdbcChatMemoryRepository時提供對應的方言:
JdbcChatMemoryRepositoryDialect dialect = ...; // The choose repository dialect
ChatMemoryRepository repository = JdbcChatMemoryRepository.builder()
.jdbcTemplate(jdbcTemplate)
.dialect(dialect)
.build();對於沒有內建支援的資料庫,我們必須實作JdbcChatMemoryRepositoryDialect介面並為每個 CRUD 操作提供 SQL 語句:
public interface JdbcChatMemoryRepositoryDialect {
String getSelectMessagesSql();
String getInsertMessageSql();
String getSelectConversationIdsSql();
String getDeleteMessagesSql();
}對於 Spring AI 中已實現的方言,CRUD 操作遵循標準 SQL,並且不依賴特定供應商。因此,我們可以直接使用提供的實作(例如MysqlChatMemoryRepositoryDialect ,而無需實作自訂方言。
在使用模式之前,我們需要初始化它。對於支援的方言,Spring AI 還提供了模式創建腳本。我們可以在classpath:org/springframework/ai/chat/memory/repository/jdbc中找到這些腳本。
4. 將聊天記憶應用到聊天用戶端
Spring AI 在ChatMemoryAutoConfiguration中提供了聊天記憶體的自動設定。如果我們選擇記憶體儲存庫,則無需明確定義任何內容,因為這是預設值。
但是,如果我們想使用 JDBC 儲存庫,我們需要提供ChatMemoryRepository的 bean 方法來覆寫預設的記憶體方法:
@Configuration
public class ChatConfig {
@Bean
public ChatMemoryRepository getChatMemoryRepository(JdbcTemplate jdbcTemplate) {
return JdbcChatMemoryRepository.builder()
.jdbcTemplate(jdbcTemplate)
.dialect(new HsqldbChatMemoryRepositoryDialect())
.build();
}
}
請注意,我們不需要明確定義ChatMemory的 bean 方法,因為它已經在ChatMemoryAutoConfiguration中定義。
讓我們在 Spring Boot 中建立一個ChatService :
@Component
@SessionScope
public class ChatService {
private final ChatClient chatClient;
private final String conversationId;
public ChatService(ChatModel chatModel, ChatMemory chatMemory) {
this.chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();
this.conversationId = UUID.randomUUID().toString();
}
public String chat(String prompt) {
return chatClient.prompt()
.user(userMessage -> userMessage.text(prompt))
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, conversationId))
.call()
.content();
}
}
在建構函式中,Spring Boot 會自動注入ChatMemory實作。因此,我們透過MemoryChatMemoryAdvisor使用它來初始化ChatClient 。
我們定義了chat方法來接受提示並將訊息傳送到聊天模型。此外,我們新增了一個對話 ID 作為聊天顧問參數,以便根據目前會話唯一地識別對話。
值得注意的是,我們必須用@SessionScope註解該服務,以便它的實例可以在多個請求中持久化。
5. 與 OpenAI 集成
在我們的演示中,我們將把聊天記憶體與 OpenAI 集成,並研究 Spring AI 如何呼叫 OpenAI API 並採用記憶體中的 HSQL DB 作為持久性儲存。
讓我們為application.yml新增屬性,以新增 OpenAI API 金鑰、設定資料庫連線以及在應用程式啟動期間初始化模式:
spring:
ai:
openai:
api-key: "<YOUR-API-KEY>"
datasource:
url: jdbc:hsqldb:mem:chatdb
driver-class-name: org.hsqldb.jdbc.JDBCDriver
username: sa
password:
sql:
init:
mode: always
schema-locations: classpath:org/springframework/ai/chat/memory/repository/jdbc/schema-hsqldb.sql
現在,配置已全部設定完畢。讓我們建立一個 REST 端點,以便呼叫先前定義的ChatService :
@RestController
public class ChatController {
private final ChatService chatService;
public ChatController(ChatService chatService) {
this.chatService = chatService;
}
@PostMapping("/chat")
public ResponseEntity<String> chat(@RequestBody @Valid ChatRequest request) {
String response = chatService.chat(request.getPrompt());
return ResponseEntity.ok(response);
}
}ChatRequest是一個簡單的 DTO,它包含字串形式的提示:
public class ChatRequest {
@NotNull
private String prompt;
// getter and setter
}6. 試運行
現在,我們可以將請求傳送到 REST 端點了。我們將使用 Postman 向 REST 端點發送請求,並使用 HTTP工具包攔截 Spring Boot 應用程式與 OpenAI 之間的 HTTP 請求,以了解它們如何協同工作。
6.1. 第一個請求
讓我們在 Postman 中撥打電話詢問笑話並檢查回應:
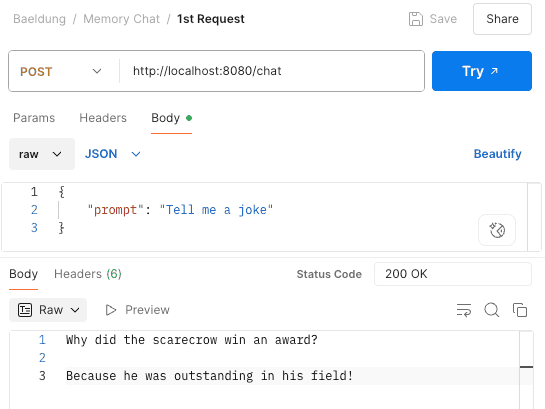
當我們在 HTTP 工具包中觀察攔截的請求時,我們會看到對 OpenAI 的 HTTP 請求:
{
"messages": [
{
"content": "Tell me a joke",
"role": "user"
}
],
"model": "gpt-4o-mini",
"stream": false,
"temperature": 0.7
}這是一個非常簡單的請求,它使用使用者角色發送我們的提示有效負載。
6.2. 第二次請求
現在,我們再發起一次請求來比較一下差異:
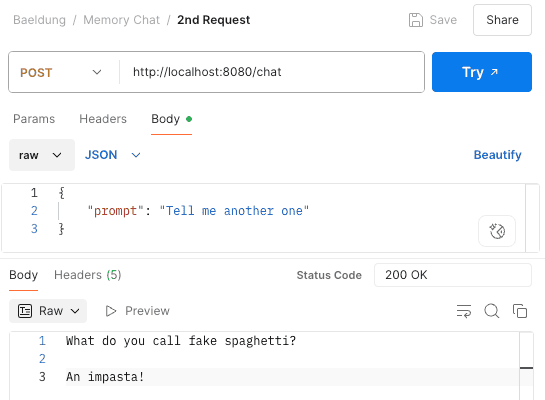
這次當我們讀取攔截到的對 OpenAI 的 HTTP 請求時,我們看到 Spring AI 不僅將我們的提示有效負載發送給 OpenAI,而且還發送了先前的提示和回應:
{
"messages": [
{
"content": "Tell me a joke",
"role": "user"
},
{
"content": "Why did the scarecrow win an award? \n\nBecause he was outstanding in his field!",
"role": "assistant"
},
{
"content": "Tell me another one",
"role": "user"
}
],
"model": "gpt-4o-mini",
"stream": false,
"temperature": 0.7
}在這個例子中,我們觀察到 Spring AI 將整個聊天記錄傳送給聊天模型。這種方法有助於聊天模型維護整個對話的上下文,並使互動感覺更自然。
7. 結論
在本文中,我們了解了 Spring AI 如何透過聊天記憶來維護跨多個聊天請求的聊天歷史記錄,從而增強對話體驗。
我們探索了不同的記憶庫,並示範如何將聊天記憶與 Spring AI 和 OpenAI 整合。我們也研究了 Spring AI 聊天記憶在後台如何與 OpenAI 協同工作。
與往常一樣,完整的原始程式碼可在 GitHub 上取得。