Java Parquet(以前稱為 Parquet MR)簡介
1.概述
Apache Parquet是一種針對分析最佳化的列式儲存格式。它可以與普通 Java 和 Maven 一起使用,無需分散式框架。同時,它仍然與 Spark 或 Hive 等引擎完全相容。
在本教程中,我們將建立一個小型 Maven 項目,新增必要的依賴項,並使用 JUnit 5 測試 Parquet Java 。
首先,我們將使用低階Example API 寫入和讀取檔案。然後,我們將切換到 Avro 支援的模型。最後,我們將示範列投影和謂詞下推。有關 API 的詳細信息,請參閱官方 Javadocs。
所有情況下的目標都是 Java 17 LTS。
2. 關鍵概念:列式儲存與行式存儲
在開始編碼之前,讓我們先澄清一個或許是最重要的概念:列式檔案按列儲存值,而行式檔案將一行的所有欄位組合在一起。 Parquet是列式的,而 CSV 和 JSON 等格式是行式的:
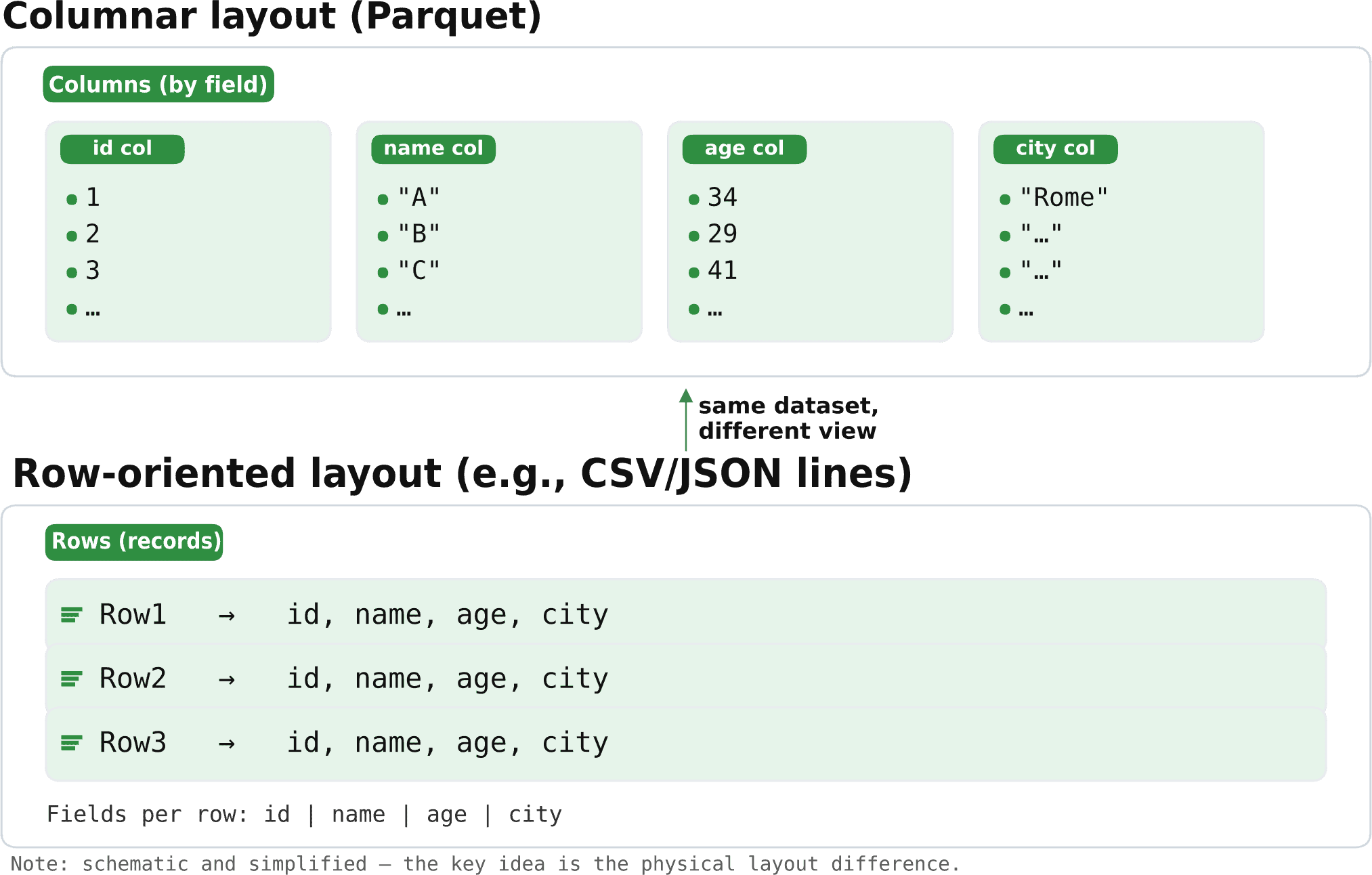
這種組織方式使 Parquet 能夠僅讀取所請求的列並應用跳過文件大部分內容的過濾器,從而無需對每一行進行解碼。
3. Maven 設定
假設 JUnit 5 和 Maven Surefire 插件已經配置完成,我們來聲明parquet-avro和parquet-hadoop 。 parquet-avro會傳遞 Parquet 的核心模組,但我們也會使用 Hadoop 支援的 I/O 和Example API(例如HadoopInputFile 、 HadoopOutputFile 、 ParquetFileReader 、 ExampleParquetWriter ),它們都存在於parquet-hadoop :
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.16.0</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>1.16.0</version>
</dependency>在複製程式碼片段之前,我們應該檢查 Maven Central 以取得最新版本。
4. 帶有Example API 的基本 Parquet 文件
Parquet Java 提供了一個小型、低階資料模型,用於演示和測試目的,透過org.apache.parquet.hadoop.example套件公開。
4.1. 核心類
在本例中,我們使用了幾個核心類別:
-
MessageType/MessageTypeParser:表示和解析以 Parquet 文字模式符號編寫的 Parquet 模式 -
Group和SimpleGroupFactory:通用的、非類型化的行容器和工廠,用於建立符合MessageType行 -
ExampleParquetWriter和ParquetReader<Group>:用於寫入和讀取Group實例的便捷類 -
HadoopOutputFile/Path/Configuration:Parquet Hadoop 模組所使用的檔案系統抽象
現在,讓我們考慮一下資料組織。
4.2. 架構
Parquet 採用型別、巢狀、列式的格式,包含原始型別(例如INT32和BYTE_ARRAY )和邏輯型別(例如BYTE_ARRAY ,以UTF-8字串形式讀取)。 BYTE_ARRAY和BINARY是等效的,大小寫無關緊要。
讓我們測試一個由三個欄位組成的非常簡單的person模式:
-
name -
age -
city
定義相當簡單:
message person {
required binary name (UTF8);
required int32 age;
optional binary city (UTF8);
}
當然,解釋也很直覺:
-
message person是根記錄類型 -
required與optional控制項的重複 -
binary (UTF8)是 Parquet 物理類型binary帶有指示 UTF-8 字串的邏輯註釋 -
int32是 32 位元整數
在 Parquet 中,每個欄位都有重複:
-
required:恰好一個值 -
optional:零個或一個 -
repeated:零次或多次,用於列表/地圖
除了文字模式表示法之外,我們可以使用 Java API 來建立等效的模式。實際上,我們稍後會討論這些選項。
4.3. 編寫與讀取模式
讓我們使用Example API 寫入兩行,然後讀回它們以斷言一個簡單的往返:
@Test
void givenSchema_whenWritingAndReadingWithExampleApi_thenRoundtripWorks(@TempDir java.nio.file.Path tmp) throws Exception {
String schemaString = """
message person {
required binary name (UTF8);
required int32 age;
optional binary city (UTF8);
}
""";
MessageType schema = MessageTypeParser.parseMessageType(schemaString);
SimpleGroupFactory factory = new SimpleGroupFactory(schema);
Configuration conf = new Configuration();
Path hPath = new Path(tmp.resolve("people-example.parquet").toUri());
try (ParquetWriter<Group> writer = ExampleParquetWriter.builder(HadoopOutputFile.fromPath(hPath, conf))
.withConf(conf)
.withType(schema)
.build()) {
writer.write(factory.newGroup()
.append("name", "Alice")
.append("age", 34)
.append("city", "Rome"));
writer.write(factory.newGroup()
.append("name", "Bob")
.append("age", 29));
}
List<String> names = new ArrayList<>();
try (ParquetReader<Group> reader = ParquetReader.builder(new GroupReadSupport(), hPath)
.withConf(conf)
.build()) {
Group g;
while ((g = reader.read()) != null) {
names.add(g.getBinary("name", 0).toStringUsingUTF8());
}
}
assertEquals(List.of("Alice", "Bob"), names);
}讓我們使用流程圖來了解程式碼的工作原理,同時對相關部分進行註解:

在本例中,我們使用了 Parquet 文字模式表示法。相較之下,在下一個範例中,我們僅使用 Java 來建立模式。
4.4. FilterPredicate跳過行組
謂詞下推使我們能夠跳過掃描不符合篩選條件的行組。支持嵌套謂詞及其組合( and 、 or 、 not )。下推適用於以下幾種類型的REQUIRED或OPTIONAL列:
-
int -
long -
float -
double -
boolean -
binary (UTF8)字串
Parquet 儲存每行組的統計數據,例如最小值和最大值,並且讀取器可以使用這些統計數據以及列索引來跳過檔案的大部分內容而無需解碼值。
例如,讓我們看一張圖表,其中顯示了一個分成多行組的 Parquet 檔案:
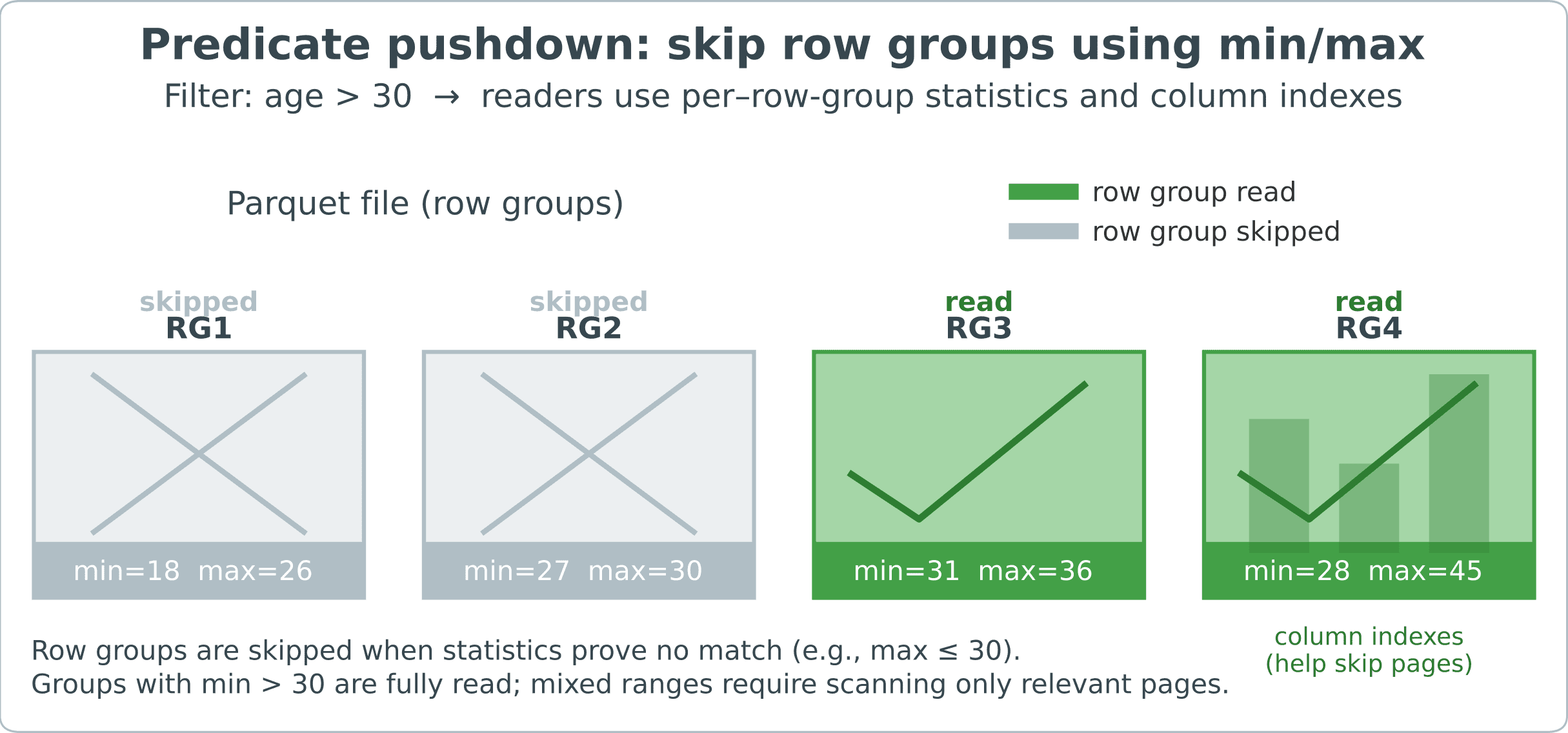
被證明不相關的組別將被完全跳過。在保留群組中,列索引可以跳過特定的列頁,這些列頁是組成列區塊的內部資料頁。
因此,讓我們使用 Java 建構器定義一個模式,寫入兩行數據,然後將age > 30過濾器附加到讀取器。此過濾器使用FilterApi表示,並在建構ParquetReader時透過FilterCompat傳遞。讀取後,我們只收集 age 滿足謂詞的行。對於典型的資料集,這種過濾方式可以顯著減少 I/O :
@Test
void givenAgeFilter_whenReading_thenOnlyMatchingRowsAppear(@TempDir java.nio.file.Path tmp) throws Exception {
Configuration conf = new Configuration();
MessageType schema = Types.buildMessage()
.addField(Types.required(PrimitiveTypeName.BINARY)
.as(LogicalTypeAnnotation.stringType())
.named("name"))
.addField(Types.required(PrimitiveTypeName.INT32)
.named("age"))
.named("Person");
GroupWriteSupport.setSchema(schema, conf);
Path hPath = new Path(tmp.resolve("people-example.parquet").toUri());
try (ParquetWriter<Group> writer = ExampleParquetWriter.builder(HadoopOutputFile.fromPath(hPath, conf))
.withConf(conf)
.build()) {
SimpleGroupFactory f = new SimpleGroupFactory(schema);
writer.write(f.newGroup()
.append("name", "Alice")
.append("age", 31));
writer.write(f.newGroup()
.append("name", "Bob")
.append("age", 25));
}
FilterPredicate pred = FilterApi.gt(FilterApi.intColumn("age"), 30);
List<String> selected = new ArrayList<>();
try (ParquetReader<Group> reader = ParquetReader.builder(new GroupReadSupport(), hPath)
.withConf(conf)
.withFilter(FilterCompat.get(pred))
.build()) {
Group g;
while ((g = reader.read()) != null) {
selected.add(g.getBinary("name", 0)
.toStringUsingUTF8());
}
}
assertEquals(List.of("Alice"), selected);
}即使謂詞不匹配,迭代器仍然會運作。但是,讀者應該快速短路,因為所有行組都可以跳過。
5. 使用 Avro 模型
使用 Avro,我們擁有一個模式優先的工作流程。為此,我們首先用 JSON 聲明一個模式,作為欄位名稱、類型和預設值的唯一真實來源。隨著數據的發展,我們會明確更新此模式,並保持向後和向前的兼容性。 Parquet 仍然是磁碟上的格式,而 Avro 則是基於它來定義我們讀寫的邏輯模型。
Avro 提供了穩定的記憶體記錄模型。我們無需操作 Parquet 基元,而是使用 Avro 記錄,這些記錄可以是模式產生的GenericRecord或SpecificRecord類型。這些記錄帶有類型值,Avro 在讀取資料時會套用預設值和模式解析。因此,即使檔案佈局或模式版本發生變化,程式碼也能保持穩定。
5.1. JSON Avro 模式
讓我們先定義一個小的 Avro 模式:
private static final String PERSON_AVRO = """
{
"type":"record",
"name":"Person",
"namespace":"com.baeldung.avro",
"fields":[
{"name":"name","type":"string"},
{"name":"age","type":"int"},
{"name":"city","type":["null","string"],"default":null}
]
}
""";city字段是一個聯合,這意味著它可能包含以下幾種類型之一:
{"name":"city","type":["null","string"],"default":null}我們最常使用聯合體來實現可空性。在本例中, city可以是null ,也可以是string 。順序很重要,因為預設值必須與第一個分支相符。這就是為什麼我們將null列在最前面,並將default設為null 。雖然聯合體可以有兩個以上的分支,但保持較小的分支可以簡化演進和互通性。
5.2. 使用AvroParquetWriter寫入GenericRecord
首先,我們使用現有的模式來建立一個AvroParquetWriter<GenericRecord> 。然後,我們寫入兩個GenericRecord實例,並使用AvroParquetReader讀取第一筆記錄。
這個設定將我們與低階 Parquet 類型隔離。我們與 Avro GenericRecord進行交互,然後由寫入器-讀取器對處理與 Parquet 列的映射:
@Test
void givenAvroSchema_whenWritingAndReadingWithAvroParquet_thenFirstRecordMatches(@TempDir java.nio.file.Path tmp) throws Exception {
Schema schema = new Schema.Parser().parse(PERSON_AVRO);
Configuration conf = new Configuration();
Path hPath = new Path(tmp.resolve("people-avro.parquet").toUri());
OutputFile out = HadoopOutputFile.fromPath(hPath, conf);
try (ParquetWriter<GenericRecord> writer = AvroParquetWriter.<GenericRecord> builder(out)
.withSchema(schema)
.withConf(conf)
.build()) {
GenericRecord r1 = new GenericData.Record(schema);
r1.put("name", "Carla");
r1.put("age", 41);
r1.put("city", "Milan");
GenericRecord r2 = new GenericData.Record(schema);
r2.put("name", "Diego");
r2.put("age", 23);
r2.put("city", null);
writer.write(r1);
writer.write(r2);
}
InputFile in = HadoopInputFile.fromPath(hPath, conf);
try (ParquetReader<GenericRecord> reader = AvroParquetReader.<GenericRecord> builder(in)
.withConf(conf)
.build()) {
GenericRecord first = reader.read();
assertEquals("Carla", first.get("name").toString());
assertEquals(41, first.get("age"));
}
}這樣,我們驗證了設置,因為people-avro.parquet嵌入了 Avro 模式,並且讀取器透明地解析它,所以我們可以專注於 Avro 記錄而不是 Parquet 原語。
5.3. 投影讀取更少的列
如果我們只需要部分列,可以傳遞一個投影模式。使用 Avro 支援的讀取器,投影只是另一個列出所需欄位的 JSON Avro 模式:
private static final String NAME_ONLY = """
{
"type":"record",
"name":"OnlyName",
"fields":[
{
"name":"name",
"type":"string"
}
]
}
""";在建立讀取器之前,我們必須使用AvroReadSupport.setRequestedProjection(conf, projection)註冊投影模式。
我們寫入{name, age, city} ,但只讀回name 。 age欄位存在於檔案中,但投影忽略了它,因此讀取結果為null :
@Test
void givenProjectionSchema_whenReading_thenNonProjectedFieldsAreNull(@TempDir java.nio.file.Path tmp) throws Exception {
Configuration conf = new Configuration();
Schema writeSchema = new Schema.Parser().parse(PERSON_AVRO);
Path hPath = new Path(tmp.resolve("people-avro.parquet").toUri());
try (ParquetWriter<GenericRecord> writer = AvroParquetWriter.<GenericRecord> builder(HadoopOutputFile.fromPath(hPath, conf))
.withSchema(writeSchema)
.withConf(conf)
.build()) {
GenericRecord r = new GenericData.Record(writeSchema);
r.put("name", "Alice");
r.put("age", 30);
r.put("city", null);
writer.write(r);
}
Schema projection = new Schema.Parser().parse(NAME_ONLY);
AvroReadSupport.setRequestedProjection(conf, projection);
InputFile in = HadoopInputFile.fromPath(hPath, conf);
try (ParquetReader<GenericRecord> reader = AvroParquetReader.<GenericRecord> builder(in)
.withConf(conf)
.build()) {
GenericRecord rec = reader.read();
assertNotNull(rec.get("name"));
assertNull(rec.get("age"));
}
}投影不會修改文件。相反,它指示讀取器跳過不需要的列並建立與投影模式相容的記錄。
6.壓縮、編碼和檔案大小
NVIDIA 已針對 Parquet 詳細研究了多種壓縮編解碼器。該公司製作了包含圖表的深入文檔,並推薦使用 ZSTD :
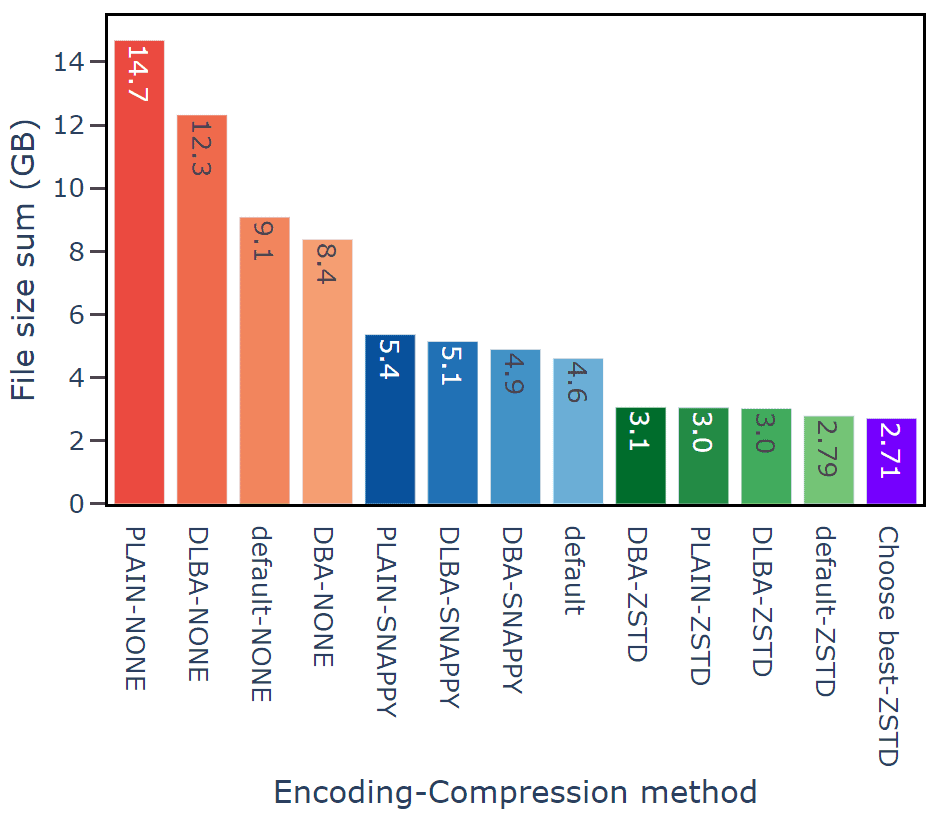
對於低基數列(即與行數相比,不同值較少的列),編寫器可以建構一個唯一值字典,並只儲存較小的整數 ID 。這通常可以顯著減少字串列的大小。
讓我們嘗試編寫兩個具有相同行的 Parquet 檔案:
- 基線檔案:未壓縮,字典關閉
- 優化檔案:ZSTD,字典開啟
然後,讓我們比較一下大小並記錄絕對值和百分比的節省:
@Test
void givenCompressionAndDictionary_whenComparingSizes_thenOptimizedIsSmaller(@TempDir java.nio.file.Path tmp) throws Exception {
MessageType schema = MessageTypeParser.parseMessageType("""
message m {
required binary name (UTF8);
required int32 age;
}
""");
Configuration conf = new Configuration();
SimpleGroupFactory factory = new SimpleGroupFactory(schema);
java.nio.file.Path baselineNio = tmp.resolve("people-baseline.parquet");
java.nio.file.Path optimizedNio = tmp.resolve("people-optimized.parquet");
Path baseline = new Path(baselineNio.toUri());
Path optimized = new Path(optimizedNio.toUri());
String[] names = { "alice", "bob", "carol", "dave", "erin" };
int[] ages = { 30, 31, 32, 33, 34 };
int rows = 5000;
try (ParquetWriter<Group> w = ExampleParquetWriter
.builder(HadoopOutputFile.fromPath(baseline, conf))
.withType(schema)
.withConf(conf)
.withCompressionCodec(CompressionCodecName.UNCOMPRESSED)
.withDictionaryEncoding(false)
.build()) {
for (int i = 0; i < rows; i++) {
w.write(factory.newGroup()
.append("name", names[i % names.length])
.append("age", ages[i % ages.length]));
}
}
try (ParquetWriter<Group> w = ExampleParquetWriter
.builder(HadoopOutputFile.fromPath(optimized, conf))
.withType(schema)
.withConf(conf)
.withCompressionCodec(CompressionCodecName.ZSTD)
.withDictionaryEncoding(true)
.build()) {
for (int i = 0; i < rows; i++) {
w.write(factory.newGroup()
.append("name", names[i % names.length])
.append("age", ages[i % ages.length]));
}
}
long baselineBytes = Files.size(baselineNio);
long optimizedBytes = Files.size(optimizedNio);
long saved = baselineBytes - optimizedBytes;
double pct = (baselineBytes == 0) ? 0.0 : (saved * 100.0) / baselineBytes;
Logger log = Logger.getLogger("parquet.tutorial");
log.info(String.format("Baseline: %,d bytes; Optimized: %,d bytes; Saved: %,d bytes (%.1f%%)",
baselineBytes, optimizedBytes, saved, pct));
assertTrue(optimizedBytes < baselineBytes, "Optimized file should be smaller than baseline");
}這次測試的結果令人印象深刻,節省了 98.8% 的空間。
7. 結論
在本文中,我們建立了一個 Java 17 Maven 項目,新增了parquet-avro和parquet-hadoop ,並使用 JUnit 驗證了往返寫入和讀取。我們首先使用低階Example API 定義了一個小型模式並練習了基本的 I/O,然後遷移到 Avro,以實現模式優先的模型,該模型能夠隨著資料的發展而保持穩定。
這樣,我們展示了列式儲存的核心優勢:
- 投影僅讀取請求的列
- 謂詞下推以跳過不相關的行組
- 透過字典編碼大幅減少 ZSTD 的大小
與往常一樣,完整程式碼可在 GitHub 上取得。程式碼庫還包含一個額外的進階測試,它會開啟 Parquet 頁腳,以驗證 ZSTD 是否為有效的編解碼器,以及name列是否使用了字典頁。當 Parquet 檔案的編碼有問題時,此功能非常有用。