深度 Java 庫指南
1. 概述
在本教程中,我們將學習由 AWS 開發的與引擎無關的機器學習框架Deep Java Library (DJL) 。
諸如 PyTorch、TensorFlow、MXNet 和 ONNX 等 Python 程式庫在開發和執行深度學習神經網路方面處於領先地位。因此,Java 開發人員在處理使用人工智慧的應用程式時會遇到困難。
DJL 透過提供一個統一的互動接口,對各種機器學習引擎進行抽象化。在本文中,我們將使用 DJL 建立一個簡單的程序,用於識別影像中的手寫數字。雖然 DJL 同時支援模型訓練和推理,但我們將專注於推理,並從 DJL 的公共模型庫 Model Zoo 中載入一個預先訓練的圖像分類模型。
2. 關鍵概念
DJL API 為使用機器學習引擎提供了一個標準架構:
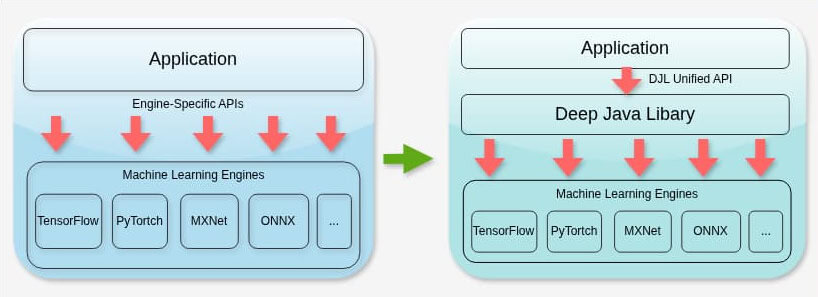
使用 Python 機器學習函式庫的應用程式必須依賴特定引擎的 API。這會導致緊密耦合,增加複雜性和維護開銷。相較之下, DJL 是一個輕量級庫,依賴項極少,使應用程式能夠透明地與底層機器學習引擎互動。本質上,DJL 並非取代機器學習引擎,而是提供了一個統一的 Java API,在運行時將執行委託給選定的引擎。因此,在不同函式庫之間切換非常便捷,只需要極少的工作量。
此外,DJL 還可以存取一個名為「模型庫」(Model Zoo)的集中式預訓練模型庫。這些模型適用於影像辨識、自然語言處理和詞向量轉換等常見用例。
該庫可以載入這些模型,然後使用資料集呼叫它們以產生所需的輸出:
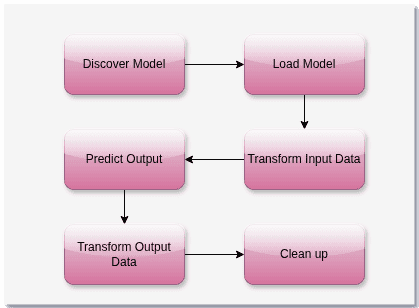
該庫從模型庫中發現一個適合特定機器學習引擎和用途的模型。然後,它將資料集預處理成底層引擎可以理解的格式。接著,該庫使用轉換後的資料集呼叫底層機器學習引擎並獲取輸出。之後,它再次將輸出轉換為 Java 程式可以理解的格式。最後,所有資源都被釋放並清理乾淨。
在接下來的章節中,我們將學習先決條件依賴項、重要的庫元件以及我們將要實現的用例。
3. 關鍵 Java 元件
讓我們來探討 DJL 的關鍵 Java 元件:
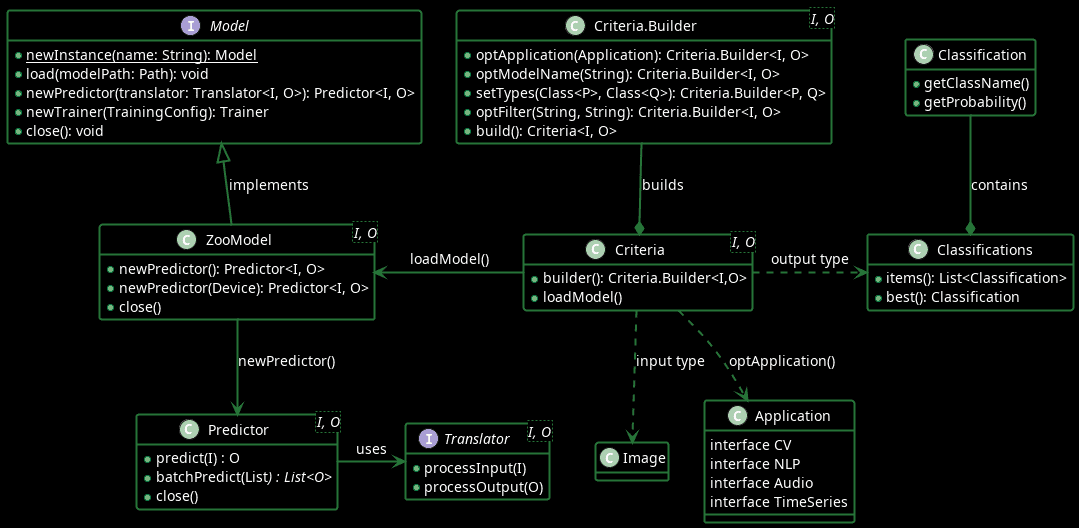
Criteria.Builder類別用於定義機器學習模型搜尋條件,例如模型名稱、模型輸入輸出參數和模型應用場景,然後建立一個Criteria物件。 Criteria Criteria#loadModel()方法則直接從模型庫載入機器學習模型。
Model#load()介面方法允許應用程式從本機快取載入機器學習模型。**根據不同的使用場景(例如訓練模型或使用模型進行預測),應用程式可以使用newTrainer()或newPredictor()方法建立Trainer或Predictor物件。 `Predictor** Predictor#predict()方法根據給定的輸入(例如圖像、音訊轉錄或文字)預測輸出。此外, Predictor#batchPredict()方法還提供了處理多個輸入並產生對應輸出清單的靈活性。
Predictor依賴Translator將輸入物件轉換為底層機器學習引擎能夠理解的格式。此外, Translator還將機器學習引擎的輸出轉換為應用程式能夠理解的格式。例如,它將圖像或音訊檔案物件轉換為機器學習引擎可以處理的 n 維表示。 DJL 庫提供了Translator介面的多個內建實現,例如ImageClassificationTranslator 、 SpeechRecognitionTranslator和ObjectDetectionTranslator 。在更專業的場景中,開發人員還可以實作Translator介面來處理自訂的預處理和後處理邏輯。
在接下來的章節中,這些概念會更加清晰,我們將實作一個影像辨識用例,以識別影像中的單一手寫數字。
4. 先決條件
首先,我們從 Maven 匯入DJL 物料清單 (BOM) ,以確保所有 DJL 依賴項的版本一致:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>ai.djl</groupId>
<artifactId>bom</artifactId>
<version>0.36.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>接下來,我們新增DJL 模型庫模組,該模組提供對託管在公共儲存庫中的預訓練模型的存取:
<dependency>
<groupId>ai.djl</groupId>
<artifactId>model-zoo</artifactId>
<version>0.36.0</version>
</dependency>最後,DJL 需要一個運行時引擎特定的依賴項才能執行模型:
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-engine</artifactId>
</dependency>我們引入了pytorch-engine函式庫,以便使用 PyTorch 作為底層機器學習引擎。
最後,對於影像辨識用例,我們將使用預先訓練的 PyTorch 模型,在經典的MNIST 資料集上進行訓練,該資料集包含 28×28 個手寫數字(0-9)。
5. 影像辨識用例實現
現在,我們可以實現圖像識別用例,以識別圖像中的單個手寫數字。
首先,我們定義一個DigitIdentifier類別:
public class DigitIdentifier {
public String identifyDigit(String imagePath)
throws ModelNotFoundException, MalformedModelException, IOException, TranslateException {
Criteria<Image, Classifications> criteria = Criteria.builder()
.optApplication(Application.CV.IMAGE_CLASSIFICATION)
.setTypes(Image.class, Classifications.class)
.optFilter("dataset", "mnist")
.build();
ZooModel<Image, Classifications> model = criteria.loadModel();
Classifications classifications = null;
try (Predictor<Image, Classifications> predictor = model.newPredictor()) {
classifications = predictor.predict(this.loadImage(imagePath));
}
return classifications.best().getClassName();
}
}在該類別中, identifyDigit()方法首先使用Criteria物件載入在 MNIST 資料集上訓練的電腦視覺模型。然後,我們呼叫model#newPredictor() ` 取得Predictor物件。接下來,我們將數位影像的路徑傳遞給Predictor#predict()方法以取得Classifications物件。 `Classifications` Classifications由多個Classification物件組成,這些物件基本上表示預測結果及其準確率。此外,我們無需遍歷所有Classification對象,而是透過呼叫Classifications#best()方法來選擇最佳結果。
現在,讓我們來看看一組從 MNIST 測試資料集中提取的數字 3 的手寫影像:
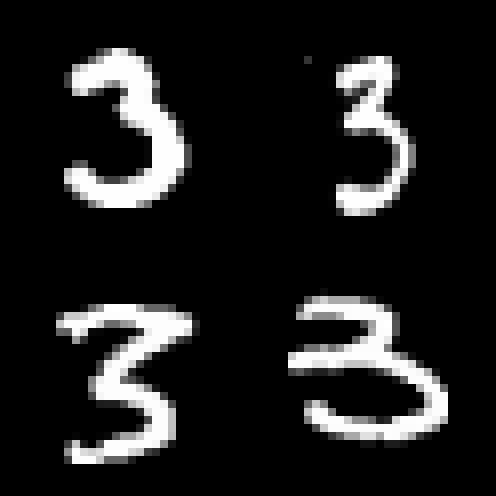
我們將運行identifyDigit()方法,看看它能否預測測試影像資料集中的數字3 :
@ParameterizedTest
@ValueSource(strings = {
"data/3_991.png", "data/3_1028.png",
"data/3_9882.png", "data/3_9996.png"
})
void whenRunModel_thenIdentifyDigitCorrectly(String imagePath) throws Exception {
DigitIdentifier digitIdentifier = new DigitIdentifier();
String identifiedDigit = digitIdentifier.identifyDigit(imagePath);
assertEquals("3", identifiedDigit);
}參數化的 JUnit 測試方法呼叫DigitIdentifier#identifyDigit()方法,並傳入測試映像的路徑。我們發現機器學習模型能夠正確預測影像檔案中的數字。
機器學習模型進行的是機率預測,因此即使對於相似的圖像,也並非總是能得出正確結果。訓練資料集的品質和代表性在很大程度上決定了預測的準確性。
6. 結論
本文介紹了 DJL API 的關鍵組成部分,並實作了一個影像辨識用例。這可以作為我們自行探索更多功能和用例的墊腳石。
DJL 對底層機器學習引擎的抽象能力確實能夠幫助 Java 開發人員為需要機器學習的應用程式做出貢獻。然而,作為前提條件,理解機器學習概念同樣重要,這有助於正確應用這些概念。
與往常一樣,本文中使用的源代碼可在 GitHub 上找到。