使用 Java 列出存儲桶中的所有 AWS S3 對象
一、概述
在本文中,我們將重點介紹如何使用 Java 列出 S3 存儲桶中的所有對象。我們將討論如何使用適用於 Java 的 AWS 開發工具包與 S3 交互,並查看不同用例的示例。
重點將放在使用適用於 Java V2 的 AWS 開發工具包上,該軟件開發工具包以其相對於先前版本的多項改進而著稱,例如增強的性能、非阻塞 I/O 和用戶友好的 API 設計。
2.先決條件
要列出 S3 存儲桶中的所有對象,我們可以使用 AWS SDK for Java 提供的S3Client類。
首先,讓我們創建一個新的 Java 項目並將以下 Maven 依賴項添加到我們的pom.xml文件中:
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
<version>2.20.52</version>
</dependency>對於本文中的示例,我們將使用版本2.20.52 。要查看最新版本,我們可以查看Maven Repository 。
我們還需要設置一個 AWS 帳戶,安裝 AWS CLI ,使用我們的 AWS 憑證( AWS_ACCESS_KEY_ID和AWS_SECERET_ACCESS_KEY )對其進行配置,以便能夠以編程方式訪問 AWS 資源。我們可以在AWS 文檔中找到完成此操作的所有步驟。
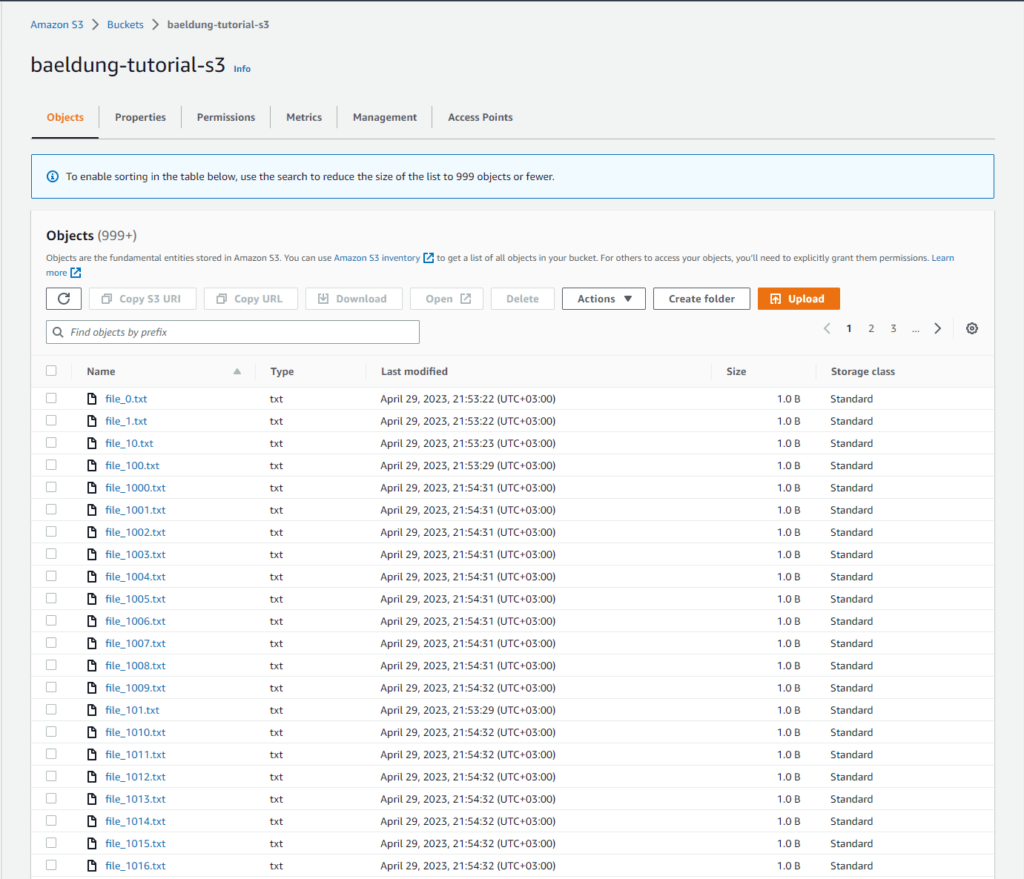
最後,我們需要創建一個 AWS S3 存儲桶並上傳一些文件。正如我們在下圖中看到的,對於我們的示例,我們創建了一個名為baeldung-tutorials-s3的存儲桶並向其上傳了 1060 個文件:
3. 列出 S3 存儲桶中的對象
讓我們使用適用於 Java V2 的 AWS 開發工具包並創建一個從存儲桶中讀取對象的方法:
String AWS_BUCKET = "baeldung-tutorial-s3";
Region AWS_REGION = Region.EU_CENTRAL_1;void listObjectsInBucket() {
S3Client s3Client = S3Client.builder()
.region(AWS_REGION)
.build();
ListObjectsV2Request listObjectsV2Request = ListObjectsV2Request.builder()
.bucket(AWS_BUCKET)
.build();
ListObjectsV2Response listObjectsV2Response = s3Client.listObjectsV2(listObjectsV2Request);
List<S3Object> contents = listObjectsV2Response.contents();
System.out.println("Number of objects in the bucket: " + contents.stream().count());
contents.stream().forEach(System.out::println);
s3Client.close();
}要列出 AWS S3 存儲桶中的對象,我們首先需要創建一個ListObjectsV2Request實例,並指定存儲桶名稱。然後,我們在s3Client對像上調用listObjectsV2方法,將請求作為參數傳遞。此方法返回一個ListObjectsV2Response,其中包含有關存儲桶中對象的信息。
最後,我們使用contents()方法訪問 S3 對象列表並將檢索到的對像數寫入輸出。我們還為存儲桶名稱和相應的 AWS 區域定義了兩個靜態屬性。
執行該方法後,我們得到以下結果:
Number of objects in the bucket: 1000
S3Object(Key=file_0.txt, LastModified=2023-06-06T11:35:06Z, ETag="b9ece18c950afbfa6b0fdbfa4ff731d3", Size=1, StorageClass=STANDARD)
S3Object(Key=file_1.txt, LastModified=2023-06-06T11:35:07Z, ETag="97a6dd4c45b23db9c5d603ce161b8cab", Size=1, StorageClass=STANDARD)
S3Object(Key=file_10.txt, LastModified=2023-06-06T11:35:07Z, ETag="3406877694691ddd1dfb0aca54681407", Size=1, StorageClass=STANDARD)
S3Object(Key=file_100.txt, LastModified=2023-06-06T11:35:15Z, ETag="b99834bc19bbad24580b3adfa04fb947", Size=1, StorageClass=STANDARD)
S3Object(Key=file_1000.txt, LastModified=2023-04-29T18:54:31Z, ETag="47ed733b8d10be225eceba344d533586", Size=1, StorageClass=STANDARD)
[...]正如我們所見,結果我們並沒有取回所有上傳的對象。
請務必注意,此解決方案旨在僅返回最多 1000 個對象。如果桶中包含超過 1000 個對象,我們必須使用ListObjectsV2Response對像中的nextContinuationToken()方法實現分頁。
4. 使用 Continuation Token 分頁
如果我們的 AWS S3 存儲桶包含超過 1000 個對象,我們需要使用nextContinuationToken()方法實現分頁。
讓我們看一個演示如何處理這種情況的示例:
void listAllObjectsInBucket() {
S3Client s3Client = S3Client.builder()
.region(AWS_REGION)
.build();
String nextContinuationToken = null;
long totalObjects = 0;
do {
ListObjectsV2Request.Builder requestBuilder = ListObjectsV2Request.builder()
.bucket(AWS_BUCKET)
.continuationToken(nextContinuationToken);
ListObjectsV2Response response = s3Client.listObjectsV2(requestBuilder.build());
nextContinuationToken = response.nextContinuationToken();
totalObjects += response.contents().stream()
.peek(System.out::println)
.reduce(0, (subtotal, element) -> subtotal + 1, Integer::sum);
} while (nextContinuationToken != null);
System.out.println("Number of objects in the bucket: " + totalObjects);
s3Client.close();
}在這裡,我們使用do-while循環對存儲桶中的所有對象進行分頁。循環繼續,直到沒有更多的繼續標記,表明我們檢索了所有對象。
因此,我們得到以下輸出:
Number of objects in the bucket: 1060使用這種方法,我們明確地管理分頁。我們檢查是否存在延續令牌並在以下請求中使用它。這使我們能夠完全控制何時以及如何請求下一頁。它允許在處理分頁過程中有更大的靈活性。
默認情況下,響應中返回的最大對像數為 1000。它可能包含較少的鍵,但絕不會包含更多。我們可以通過ListObjectsV2Reqeust的maxKeys()方法更改它。
5. 使用ListObjectsV2Iterable進行分頁
我們可以使用 AWS SDK 通過使用ListObjectsV2Iterable類和listObjectsV2Paginator()方法為我們處理分頁。這簡化了代碼,因為我們不需要手動管理分頁過程。這導致更簡潔和可讀的代碼,使其更易於維護。
讓我們看看如何將其付諸實踐:
void listAllObjectsInBucketPaginated(int pageSize) {
S3Client s3Client = S3Client.builder()
.region(AWS_REGION)
.build();
ListObjectsV2Request listObjectsV2Request = ListObjectsV2Request.builder()
.bucket(AWS_BUCKET )
.maxKeys(pageSize) // Set the maxKeys parameter to control the page size
.build();
ListObjectsV2Iterable listObjectsV2Iterable = s3Client.listObjectsV2Paginator(listObjectsV2Request);
long totalObjects = 0;
for (ListObjectsV2Response page : listObjectsV2Iterable) {
long retrievedPageSize = page.contents().stream()
.peek(System.out::println)
.reduce(0, (subtotal, element) -> subtotal + 1, Integer::sum);
totalObjects += retrievedPageSize;
System.out.println("Page size: " + retrievedPageSize);
}
System.out.println("Total objects in the bucket: " + totalObjects);
s3Client.close()
}這是我們調用pageSize為500的方法時得到的輸出:
S3Object(Key=file_0.txt, LastModified=2023-06-06T11:35:06Z, ETag="b9ece18c950afbfa6b0fdbfa4ff731d3", Size=1, StorageClass=STANDARD)
S3Object(Key=file_1.txt, LastModified=2023-06-06T11:35:07Z, ETag="97a6dd4c45b23db9c5d603ce161b8cab", Size=1, StorageClass=STANDARD)
S3Object(Key=file_10.txt, LastModified=2023-06-06T11:35:07Z, ETag="3406877694691ddd1dfb0aca54681407", Size=1, StorageClass=STANDARD)
[..]
S3Object(Key=file_494.txt, LastModified=2023-04-29T18:53:56Z, ETag="69b7a7308ee1b065aa308e63c44ae0f3", Size=1, StorageClass=STANDARD)
Page size: 500
S3Object(Key=file_495.txt, LastModified=2023-04-29T18:53:57Z, ETag="83acb6e67e50e31db6ed341dd2de1595", Size=1, StorageClass=STANDARD)
S3Object(Key=file_496.txt, LastModified=2023-04-29T18:53:57Z, ETag="3beb9cf0eab8cbf2215990b4a6bdc271", Size=1, StorageClass=STANDARD)
S3Object(Key=file_497.txt, LastModified=2023-04-29T18:53:57Z, ETag="69691c7bdcc3ce6d5d8a1361f22d04ac", Size=1, StorageClass=STANDARD)
[..]
S3Object(Key=file_944.txt, LastModified=2023-04-29T18:54:27Z, ETag="f623e75af30e62bbd73d6df5b50bb7b5", Size=1, StorageClass=STANDARD)
Page size: 500
S3Object(Key=file_945.txt, LastModified=2023-04-29T18:54:27Z, ETag="55a54008ad1ba589aa210d2629c1df41", Size=1, StorageClass=STANDARD)
S3Object(Key=file_946.txt, LastModified=2023-04-29T18:54:27Z, ETag="ade7a0dcf4ddc0673ed48b70a4a340d6", Size=1, StorageClass=STANDARD)
S3Object(Key=file_947.txt, LastModified=2023-04-29T18:54:27Z, ETag="0a476d83ef9cef4bce7f9025522be3b5", Size=1, StorageClass=STANDARD)
[..]
S3Object(Key=file_999.txt, LastModified=2023-04-29T18:54:31Z, ETag="5e732a1878be2342dbfeff5fe3ca5aa3", Size=1, StorageClass=STANDARD)
Page size: 60
Total objects in the bucket: 1060當我們在for循環中遍歷頁面時,AWS 開發工具包通過檢索下一頁來延遲處理分頁。它僅在我們到達當前頁面末尾時才獲取下一頁,這意味著頁面是按需加載的,而不是一次全部加載。
6.使用前綴列出對象
在某些情況下,我們只想列出具有共同前綴的對象,例如,所有以“backup”開頭的對象。
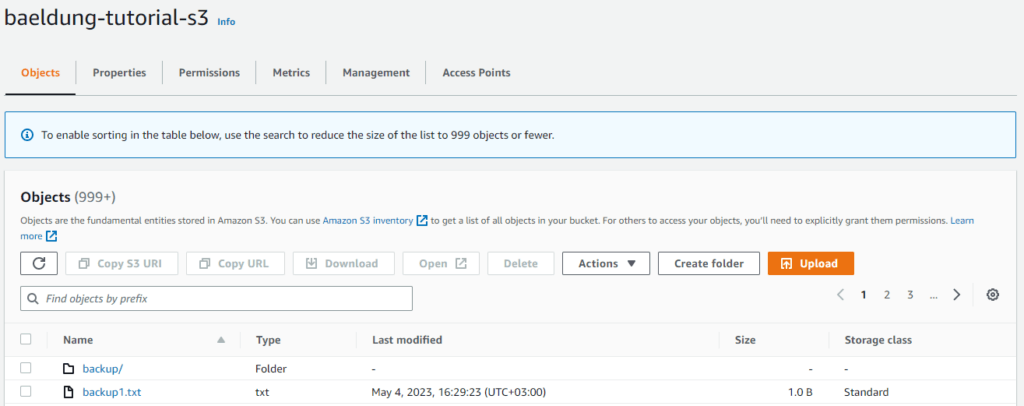
為了展示這個用例,讓我們將名為backup1.txt的文件上傳到存儲桶,創建一個名為backup的文件夾並將六個文件移入其中。桶現在總共包含七個對象。
這就是我們的桶的樣子:
讓我們更改我們的函數以僅返回具有公共前綴的對象:
void listAllObjectsInBucketPaginatedWithPrefix(int pageSize, String prefix) {
S3Client s3Client = S3Client.builder()
.region(AWS_REGION)
.build();
ListObjectsV2Request listObjectsV2Request = ListObjectsV2Request.builder()
.bucket(AWS_BUCKET)
.maxKeys(pageSize) // Set the maxKeys parameter to control the page size
.prefix(prefix) // Set the prefix
.build();
ListObjectsV2Iterable listObjectsV2Iterable = s3Client.listObjectsV2Paginator(listObjectsV2Request);
long totalObjects = 0;
for (ListObjectsV2Response page : listObjectsV2Iterable) {
long retrievedPageSize = page.contents().stream().count();
totalObjects += retrievedPageSize;
System.out.println("Page size: " + retrievedPageSize);
}
System.out.println("Total objects in the bucket: " + totalObjects);
s3Client.close();
}我們只需要在ListObjectsV2Request上調用prefix方法。如果我們調用prefix參數設置為“ backup ”的函數,它會計算存儲桶中以“backup”開頭的所有對象。 “backup1.txt”和“backup/file1.txt”這兩個鍵都匹配:
listAllObjectsInBucketPaginatedWithPrefix(10, "backup");這是我們返回的結果:
S3Object(Key=backup/, LastModified=2023-04-30T17:47:33Z, ETag="d41d8cd98f00b204e9800998ecf8427e", Size=0, StorageClass=STANDARD)
S3Object(Key=backup/file_0.txt, LastModified=2023-04-30T17:48:13Z, ETag="a87ff679a2f3e71d9181a67b7542122c", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_1.txt, LastModified=2023-04-30T17:48:13Z, ETag="9eecb7db59d16c80417c72d1e1f4fbf1", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_2.txt, LastModified=2023-04-30T17:48:13Z, ETag="800618943025315f869e4e1f09471012", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_3.txt, LastModified=2023-04-30T17:48:13Z, ETag="8666683506aacd900bbd5a74ac4edf68", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_4.txt, LastModified=2023-04-30T17:49:05Z, ETag="f95b70fdc3088560732a5ac135644506", Size=1, StorageClass=STANDARD)
S3Object(Key=backup1.txt, LastModified=2023-05-04T13:29:23Z, ETag="ec631d7335abecd318f09f56515ed63c", Size=1, StorageClass=STANDARD)
Page size: 7
Total objects in the bucket: 7如果我們不想直接統計桶下的對象,我們需要在前綴中添加一個尾部斜杠:
listAllObjectsInBucketPaginatedWithPrefix(10, "backup/");現在我們只得到“bucket/”文件夾中的對象:
S3Object(Key=backup/, LastModified=2023-04-30T17:47:33Z, ETag="d41d8cd98f00b204e9800998ecf8427e", Size=0, StorageClass=STANDARD)
S3Object(Key=backup/file_0.txt, LastModified=2023-04-30T17:48:13Z, ETag="a87ff679a2f3e71d9181a67b7542122c", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_1.txt, LastModified=2023-04-30T17:48:13Z, ETag="9eecb7db59d16c80417c72d1e1f4fbf1", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_2.txt, LastModified=2023-04-30T17:48:13Z, ETag="800618943025315f869e4e1f09471012", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_3.txt, LastModified=2023-04-30T17:48:13Z, ETag="8666683506aacd900bbd5a74ac4edf68", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_4.txt, LastModified=2023-04-30T17:49:05Z, ETag="f95b70fdc3088560732a5ac135644506", Size=1, StorageClass=STANDARD)
Page size: 6
Total objects in the bucket: 6七、結論
在本文中,我們研究了使用適用於 Java V2 的 AWS 開發工具包有效列出 AWS S3 存儲桶中對象的不同用例。
我們學習了管理對象列表的不同方法,例如對少於 1000 個對象使用ListObjectsV2Reqest ,使用連續令牌實現分頁,利用ListObjectsV2Iterable的便利性進行自動分頁,以及使用通用前綴來過濾和組織對象列表。
與往常一樣,這些示例的代碼在 GitHub 上可用。