Apache Camel 的 KServe 元件:透過模型服務進行推理
1.概述
在當今快節奏的 AI 服務開發領域,市面上有大量預先訓練的 AI 模型,以及許多可用於託管這些模型的模型服務平台,例如 TensorFlow 和 NVIDIA Triton。在 Java 生態系統中,主要關注點在於將應用程式與模型服務伺服器集成,從而實現與 AI 模型的高效通訊。
Apache Camel 的 KServe 元件透過促進與相容 KServe 的模型伺服器的交互,為 AI 模型推理提供了簡化的解決方案。該元件簡化了 Java 應用程式與託管已訓練 AI 模型的模型伺服器之間的通訊。
在本教程中,我們將探索使 Java 應用程式能夠與 AI 模型互動所需的工具。此外,我們將介紹一個 Java 服務的實際範例,該服務使用 AI 分析使用者提供的句子,並判斷它們表達的是正面還是負面的情緒。
2. 工具概述
為了將我們的 Java 應用程式與 AI 模型集成,我們需要一個經過訓練的 AI 模型、一個為該模型提供服務的主機,以及一個具有便於與主機輕鬆集成的框架的 Java 應用程式。
模型可以是任何類型,例如 TensorFlow、PyTorch、ONNX、OpenVINO 等。主機應該是任何支援 KServe開放推理協定 (OIP) V2 的主機,例如最新版本的 NVIDIA Triton。
接下來,讓我們快速瀏覽一下我們將在應用程式中使用的確切工具、協定和框架:
- KServe (原名 KFServing)是一款基於 Kubernetes 的機器學習模型服務工具。它旨在簡化在 Kubernetes 上部署和管理機器學習模型的過程,並具備自動擴縮、滾動更新和模型版本控制等功能。 KServe 與 TensorFlow、PyTorch 和 scikit-learn 等工具完美集成,更輕鬆地實現這些模型的大規模部署。
- 開放推理協定 V2 是一個標準化的通訊協定。它最初是在 KServe 專案中引入和使用的。現在,該協議已得到多個後端的支持,而不僅僅是 KServe。
- Apache Camel 是一個開源整合框架,支援使用各種協定和技術整合不同的系統。 Camel 擁有豐富的組件,因此幾乎可以與任何我們引入的技術相容——HTTP、JMS、資料庫等等。更具體地說,Apache Camel 的 KServe 元件可以與支援 KServe 開放推理協定 (OIP) V2 的系統整合。
- NVIDIA Triton是一個專為高效能 AI 推理而設計的開源模型服務平台。它支援 TensorFlow、PyTorch 和 ONNX 等多種熱門框架,使組織能夠靈活地大規模部署模型。
- Hugging Face是自然語言處理 (NLP) 領域的領先平台。它為文本分類、翻譯和情緒分析等 NLP 任務提供了廣泛的預訓練模型和工具。我們也可以從這裡取得用於我們服務的訓練有素的 AI 模型。
3. 使用預先訓練的 AI 模型的情緒服務
為了演示,我們將創建一個實際的應用程序,它接受一個句子並預測該句子的情緒是好是壞。我們只需要一個預先訓練好的 AI 模型、一個模型宿主和一個能夠提供更友善使用者體驗的 Java 應用程式。
3.1. 建立預先訓練的情緒人工智慧模型
創建、訓練等 AI 模型不屬於本文的討論範圍。我們將使用 Hugging Face 現有的模型,更具體地說,我們將下載預先訓練好的模型pjxcharya/onnx-sentiment- model 。該模型接收一個句子,並將其轉換為適當的 token,然後傳回兩個數字:一個負數和一個正數。若負數的絕對值較大,則情緒為bad ,否則為good 。
在繼續之前,我們唯一需要做的就是了解模型的輸入和輸出。稍後,當我們使用 Apache Camel 的 KServe 元件與伺服器互動時,我們會使用這些資訊。一個簡單的方法是使用線上工具netron.app ,它提供了模型圖和屬性:
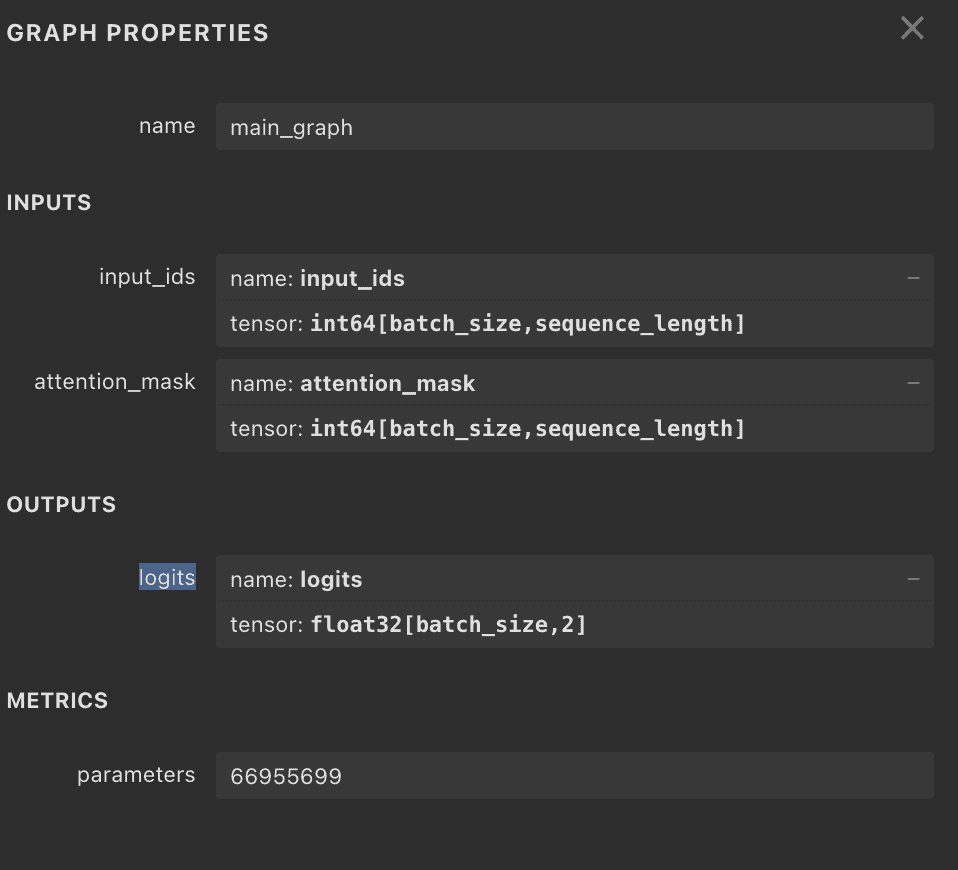
從圖中我們可以看到,我們的輸入是input_ids和attention_mask ,都是int64型別。輸出是float32類型的logits 。
3.2. 設定Triton模型服務伺服器
NVIDIA 的 Triton 模型伺服器可以託管我們 ONNX 類型的模型。首先,我們將 ONNX 模型檔案放在models/sentiment/1/model.onnx中,然後建立設定檔models/sentiment/config.pbtxt :
name: "sentiment"
platform: "onnxruntime_onnx"
max_batch_size: 8
input [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [ -1 ]
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
output [
{
name: "logits"
data_type: TYPE_FP32
dims: [ 2 ]
}
]這裡我們設定模型的名稱以及輸入和輸出的名稱和類型。
最後,我們建立一個Dockerfile以使其易於部署:
FROM nvcr.io/nvidia/tritonserver:25.02-py3
# Copy the model repository into the container
COPY models/ /models/
# Expose default Triton ports
EXPOSE 8000 8001 8002
# Set entrypoint to run Triton with your model repo
CMD ["tritonserver", "--model-repository=/models"]我們需要做的就是將模型資料夾複製到容器中並將其設定為model-repository 。
3.3. 使用 Apache Camel 的 KServe 元件的 Web 服務
Apache Camel 可以直接透過 HTTP 或 gRPC 與模型伺服器通訊。但是,使用 Apache Camel 的 KServe 元件,互動會更加直接,並且更適合任何支援 KServe V2 協定的模型伺服器。
首先設定使用 KServe 元件的依賴項。請注意,該元件從 4.10.0 及更高版本開始可用:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-main</artifactId>
<version>4.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-kserve</artifactId>
<version>4.13.0</version>
</dependency>接下來,我們繼續建立 Apache Camel Kserve 路由,該路由接受請求(在我們的範例中是 HTTP 請求)並將其路由到對 Triton 伺服器的呼叫:
public class SentimentsRoute extends RouteBuilder {
@Override
public void configure() {
// (code that configures the REST incoming call)
// Main route
from("direct:classify")
.routeId("sentiment-inference")
.setBody(this::createRequest)
.setHeader("Content-Type", constant("application/json"))
.to("kserve:infer?modelName=sentiment&target=localhost:8001")
.process(this::postProcess);
}
// ...
}假設我們已將配置設定為接受傳入的 REST 呼叫並將其路由至“direct:classify” ,我們將路由設定為與 Triton 伺服器整合。 createRequest createRequest()方法建立請求主體, postProcess()處理回應,正如我們將在本教程後面看到的。 KServer 協定的端點以“kserve:…”開頭,然後是方法,對於 Triton 來說,該modelName通常是infer和target屬性設定為指向正確的 URL 和模型(請注意,對於我們使用 Docker Compose 的情況,我們需要將主機設定為host.docker.internal )。
3.4. 處理 Apache Camel 的 KServe 元件輸入
Apache Camel 提供了一個豐富的函式庫,用於為我們的路由建立請求。 KServe元件新增了InferTensorContents類別來為請求建立物件。它允許我們設定模型屬性的資料類型、名稱、形狀、內容等:
private ModelInferRequest createRequest(Exchange exchange) {
String sentence = exchange.getIn().getHeader("sentence", String.class);
Encoding encoding = tokenizer.encode(sentence);
List<Long> inputIds = Arrays.stream(encoding.getIds()).boxed().collect(Collectors.toList());
List<Long> attentionMask = Arrays.stream(encoding.getAttentionMask()).boxed().collect(Collectors.toList());
var content0 = InferTensorContents.newBuilder().addAllInt64Contents(inputIds);
var input0 = ModelInferRequest.InferInputTensor.newBuilder()
.setName("input_ids").setDatatype("INT64").addShape(1).addShape(inputIds.size())
.setContents(content0);
var content1 = InferTensorContents.newBuilder().addAllInt64Contents(attentionMask);
var input1 = ModelInferRequest.InferInputTensor.newBuilder()
.setName("attention_mask").setDatatype("INT64").addShape(1).addShape(attentionMask.size())
.setContents(content1);
ModelInferRequest requestBody = ModelInferRequest.newBuilder()
.addInputs(0, input0).addInputs(1, input1)
.build();
return requestBody;
}如前所述,我們需要建立一個包含兩個輸入的請求。 tokenizer tokenizer來自ai.djl.huggingface:tokenizers依賴項,它幫助我們將人類可讀的字串編碼為模型接受的encoding.ids 。這就是我們向 Triton 伺服器發送請求所需的全部內容。
3.5. 處理 Apache Camel 的 KServe 元件輸出
類似地,我們可以使用ModelInferResponse類別來接收來自模型服務伺服器的回應:
private void postProcess(Exchange exchange) {
ModelInferResponse response = exchange.getMessage().getBody(ModelInferResponse.class);
List<List<Float>> logits = response.getRawOutputContentsList().stream()
.map(ByteString::asReadOnlyByteBuffer)
.map(buf -> buf.order(ByteOrder.LITTLE_ENDIAN).asFloatBuffer())
.map(buf -> {
List<Float> longs = new ArrayList<>(buf.remaining());
while (buf.hasRemaining()) {
longs.add(buf.get());
}
return longs;
})
.toList();
String result = Math.abs(logits.getFirst().getFirst()) < logits.getFirst().getLast() ? "good" : "bad";
exchange.getMessage().setBody(result);
}在這裡,我們使用getRawOutputContentsList()方法將位元組轉換為浮點數,並將負數與正數進行比較,以了解預測是好情緒還是壞情緒。
3.6. 使用 Docker Compose 演示
讓我們建立一個docker-compose.yml檔案來輕鬆啟動 Triton 伺服器和我們的 Java 應用程式:
services:
triton-server:
build: ./triton-server
environment:
- NVIDIA_VISIBLE_DEVICES=all
ports:
- "8000:8000" # HTTP
- "8001:8001" # gRPC
- "8002:8002" # Metrics
sentiment-service:
build: ./sentiment-service
ports:
- "8080:8080"啟動服務後,我們可以請求 Java 服務來測試不良情緒:
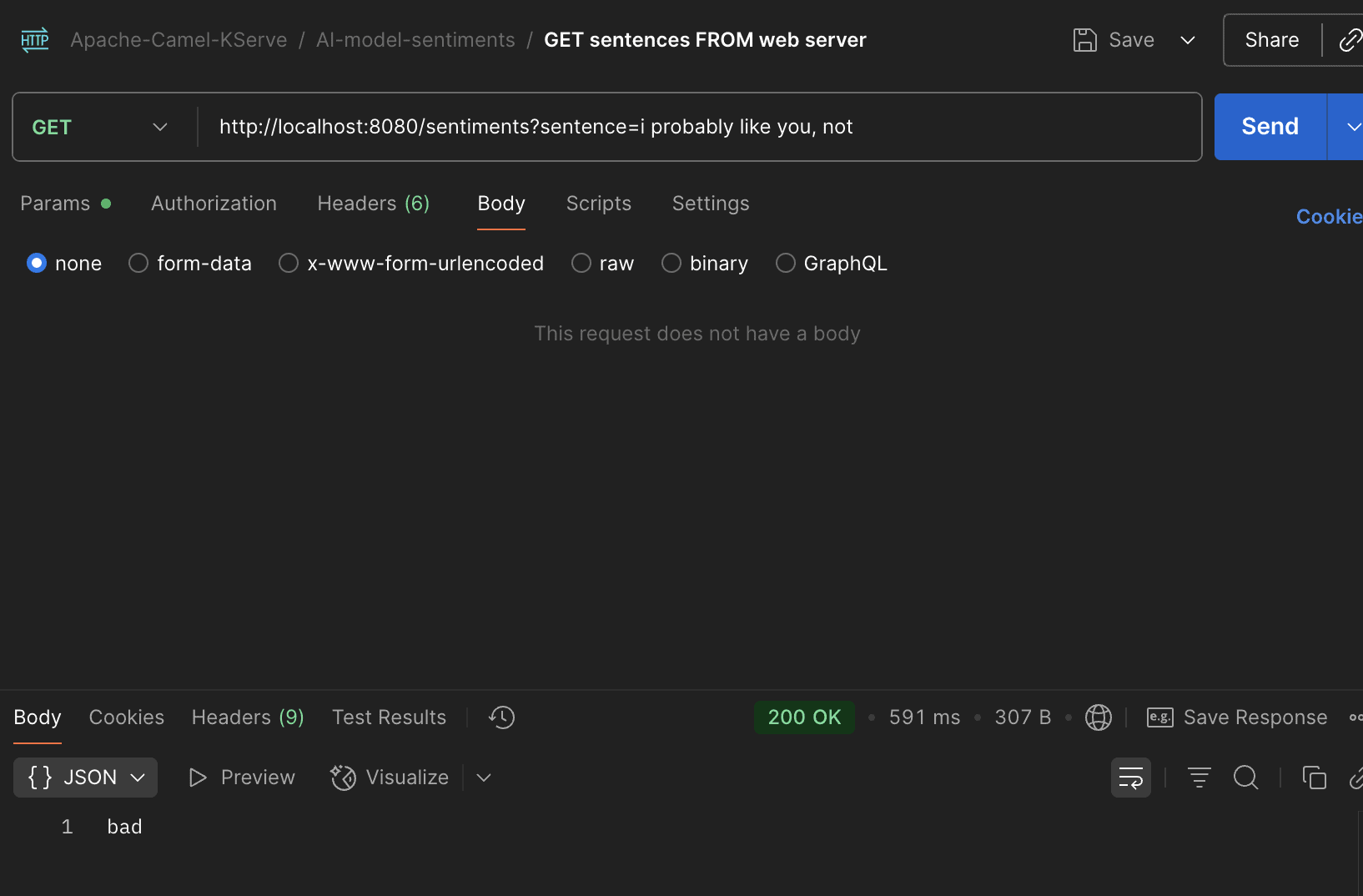
還有美好的情感:
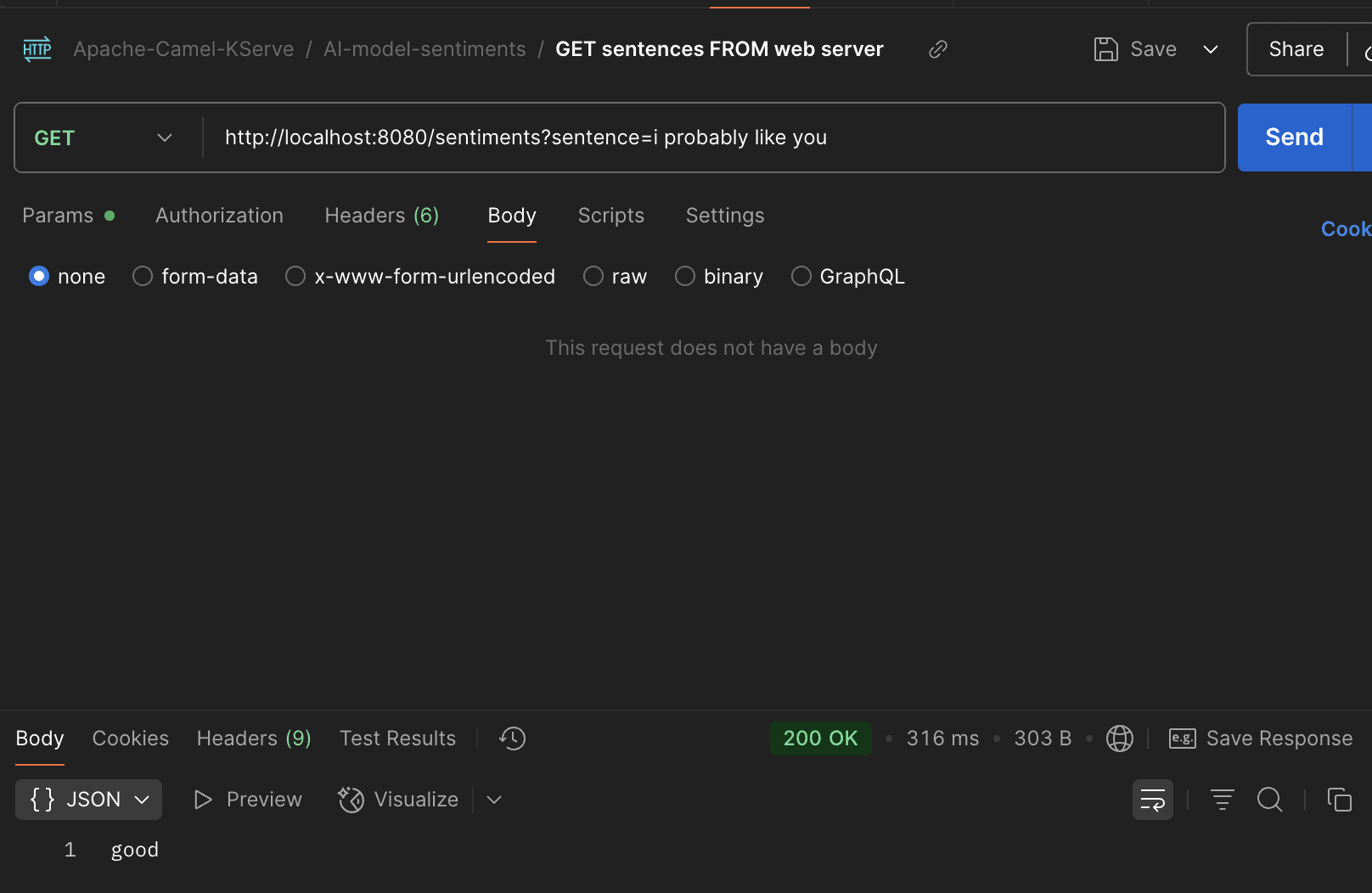
我們在圖片中看到該模型透過我們的網路服務如預期運作。
4. 結論
在本文中,我們示範如何使用 Apache Camel 的 KServe 元件建立具有 AI 模型推理功能的 Java 應用程式。我們使用 Apaceh Camel 輕鬆與模型服務主機 Triton 整合。我們在 Triton 中預先載入了一個 AI 模型,該模型可以對所提供句子的情緒(好或壞)進行預測。
與往常一樣,範例中使用的所有原始程式碼都可以在 GitHub 上找到。