RDF 與 Apache Jena 簡介
1. 簡介
在本教程中,我們將研究資源描述框架 (RDF) 標準和Apache Jena如何在應用程式中使用 RDF。
2.什麼是RDF?
資源描述框架 (Resource Description Framework) 是 W3C 的建議,旨在儲存和交換圖表資料。這使得它在需要描述各種相互關聯的數據及其關係時特別有用。例如,我們可以將它用於部落格系統,描述貼文、評論、作者以及它們之間的關係。
RDF 規格本身定義瞭如何描述資料模型,以及如何將這些模型序列化以供實際使用。這是 W3C語意網路工作的基礎之一。
3.什麼是 Apache Jena?
Apache Jena是一個免費的開源 Java 框架,旨在建立語意網路和關聯資料應用程式。它提供了處理 RDF 模型的工具,既可以描述模型本身,也可以從各種格式進行序列化和反序列化。它還包含一些用於建立應用程式的其他工具,例如用於透過 HTTP 公開 RDF 模型的Fuseki 伺服器。
3.1. 依賴項
首先,我們需要在pom.xml檔中包含[apache-jena-libs](https://mvnrepository.com/artifact/org.apache.jena/apache-jena)依賴項:
<dependency>
<groupId>org.apache.jena</groupId>
<artifactId>apache-jena-libs</artifactId>
<type>pom</type>
<version>5.5.0</version>
</dependency>此時,我們已準備好開始在我們的應用程式中使用它。
4. RDF 模型
RDF 的核心在於我們用來表示資料的實際模型。這些模型由各種資源組成,每種資源都具有定義自身的屬性以及這些資源之間的關係。
例如,我們可能有一個部落格文章的模型,如下所示:
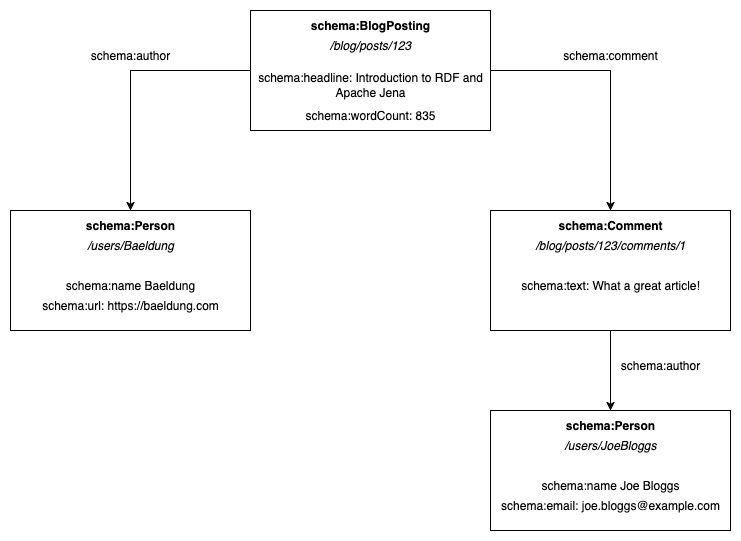
這裡,我們有四種不同的資源:一篇部落格文章、一則評論和兩個人。每種資源都有一些定義自身的屬性,並且它們之間有關係。
4.1. 身份
我們模型中的每個資源都必須具有一個唯一識別碼。在 RDF 中,這些標識符以 URI 的形式提供,例如/blog/posts/123或/users/JoeBloggs 。這些 URI 可能可以解析為資源本身,但並非必須如此。
使用 URI 不僅確保了我們的身分在全球範圍內的唯一性,還允許不同服務控制的資源相互引用。這是關聯資料在應用程式中運作的關鍵方面。
從我們的圖表中稍微不太明顯的是,我們的屬性和關係也具有由 URI 描述的不同標識。這些標識通常以類似於 XML 命名空間工作的簡寫形式書寫。例如,資源類型schema:Person其實是https://schema.org/Person ,而屬性schema:name其實是https://schema.org/name 。
雖然我們可以為資源、屬性和關係使用任何身份,但為此目的,存在標準詞彙表。例如, Schema.org或Friend Of A Friend (FOAF)是標準公共詞彙表。使用這些詞彙表,消費者可以透過其公共定義來理解我們的物件。
4.2. 語句
在 RDF 中,我們使用一系列 RDF 語句(也稱為 RDF 三元組)來描述資源。每個 RDF 語句由三個部分組成:
- 主題-聲明適用的資源的身份。
- 謂詞——我們所作陳述的身份。
- 物件-語句的原始值,或語句所引用的其他資源的標識。
例如,為我們的部落格文章提供標題的 RDF 語句將是:
- 主題 –
/blog/posts/123 - 謂詞 –
https://schema.org/headline - 物件——“RDF 和 Apache Jena 簡介”
我們可以根據需要添加任意數量的語句來描述我們的資源。所有資源中這些語句的完整集合定義了我們的模型。
5. 使用 Apache Jena 建構 RDF 模型
現在我們知道了什麼是 RDF 模型,我們需要能夠在我們的程式碼中建立它們。
我們可以使用ModelFactory建立一個空白的 RDF 模型:
Model model = ModelFactory.createDefaultModel();然後,我們使用createResource()將資源加入模型中:
Resource blogPost = model.createResource("/blog/posts/123");一旦我們有了資源,我們就使用addProperty()來新增屬性:
blogPost.addProperty(SchemaDO.headline, "Introduction to RDF and Apache Jena");
blogPost.addProperty(SchemaDO.wordCount, "835");
blogPost.addProperty(SchemaDO.author, model.createResource("/users/Baeldung"));
blogPost.addProperty(SchemaDO.comment, model.createResource("/blog/posts/123/comments/1"));
第一個參數是定義屬性的謂詞。 Jena 為許多標準本體提供了常數,或者我們可以根據需要編寫自己的本體。在本例中, SchemaDO代表 Schema.org 詞彙表。第二個參數是屬性的值-可以是文字值,也可以是另一個Resource實例。
5.1. 擷取模型值
我們也可以從模型中提取值。如果我們知道資源的標識,我們可以使用getResource()方法來檢索它:
Resource blogPost = model.getResource("/blog/posts/123");此外,我們可以使用getProperty()方法從資源中取得單一屬性:
Statement headline = blogPost.getProperty(SchemaDO.headline);這將傳回一個表示 RDF 語句的Statement實例。
最後,一旦我們得到了Statement實例,我們就可以查詢它的不同面向:
Resource subject = headline.getSubject()
Property predicate = headline.getPredicate();
RDFNode object = headline.getObject()getObject()傳回的RDFNode使我們能夠在 RDF 模型中更了解該節點。例如,我們可以檢查它是一個文字值還是其他資源:
assertTrue(headline.getObject().isLiteral());
assertFalse(headline.getObject().isResource());
我們可以使用getString()來取得文字值,或使用getResource()取得資源參考:
String headline = blogPost.getProperty(SchemaDO.headline).getString();
Resource author = blogPost.getProperty(SchemaDO.author).getResource();6. 序列化與反序列化 RDF
在程式碼中表示 RDF 模型很有用。但是,我們還需要能夠序列化和反序列化它們。這樣我們才能將它們持久化到磁碟上或在服務之間傳輸它們。
6.1. N-三元組
我們經常會看到以N-Triple 形式編寫的 RDF 模型。此標準在 RDF 測試案例規格中定義。它要求將每個語句寫在單獨的行上。這樣做時,我們將語句中的主詞、謂詞和受詞用空格分隔,然後以一個句點結束整個語句。在寫值時,URI 標識用 <> 括起來,文字值用 “” 括起來。
例如,我們的整個模型可以寫成:
</blog/posts/123> <https://schema.org/headline> "Introduction to RDF and Apache Jena" .
</blog/posts/123> <https://schema.org/wordCount> "835" .
</blog/posts/123> <https://schema.org/comment> </blog/posts/123/comments/1> .
</blog/posts/123> <https://schema.org/author> </users/Baeldung> .
</blog/posts/123/comments/1> <https://schema.org/text> "What a great article!" .
</blog/posts/123/comments/1> <https://schema.org/author> </users/JoeBloggs> .
</users/Baeldung> <https://schema.org/name> "Baeldung" .
</users/Baeldung> <https://schema.org/url> "https://baeldung.com" .
</users/JoeBloggs> <https://schema.org/name> "Joe Bloggs" .
</users/JoeBloggs> <https://schema.org/email> "[email protected]" .這組語句以簡潔的形式直接表示了我們的模型。
我們可以使用 Jena 透過RDFDataMgr.write()方法來編寫我們的模型:
RDFDataMgr.write(System.out, model, Lang.NTRIPLES);這將會取得要寫入的輸出流、要寫入的模型和格式,並輸出模型的全部內容。
6.2. RDF-XML
除了 N-Triple 格式外,我們還有RDF-XML 格式。這種格式的可讀性較差,但卻是機器使用的首選格式。 W3C 維護一個描述此格式工作原理的架構,方便我們在應用程式中輕鬆產生和使用它。
例如,我們在 RDF-XML 中的整個模型將是:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:schema="https://schema.org/">
<rdf:Description rdf:about="tag:baeldung:/blog/posts/123">
<schema:wordCount>835</schema:wordCount>
<schema:headline>Introduction to RDF and Apache Jena</schema:headline>
<schema:author>
<rdf:Description rdf:about="tag:baeldung:/users/Baeldung">
<schema:url>https://baeldung.com</schema:url>
<schema:name>Baeldung</schema:name>
</rdf:Description>
</schema:author>
<schema:comment>
<rdf:Description rdf:about="tag:baeldung:/blog/posts/123/comments/1">
<schema:text>What a great article!</schema:text>
<schema:author>
<rdf:Description rdf:about="tag:baeldung:/users/JoeBloggs">
<schema:email>[email protected]</schema:email>
<schema:name>Joe Bloggs</schema:name>
</rdf:Description>
</schema:author>
</rdf:Description>
</schema:comment>
</rdf:Description>
</rdf:RDF>和之前一樣,我們可以使用RDFDataMgr.write()來編寫此程式碼,並傳入Lang.RDFXML作為格式:
RDFDataMgr.write(System.out, model, Lang.RDFXML);這會將整個模型寫入給定的輸出流,但這次採用的是 RDF-XML 格式。請注意,對於此格式的所有標識符,我們必須使用絕對 URI,但我們可以選擇任何 URI 方案。
最後,因為 XML 是標準交換格式,我們也可以只使用Model.write()來實現相同的結果:
model.write(System.out);6.3. 解析 RDF-XML
除了將我們的模型序列化為 RDF-XML 之外,我們還可以使用Model.read()方法將其解析回我們的Model物件:
Model model = ModelFactory.createDefaultModel();
model.read(new StringReader(rdfxml), null);
我們必須將 XML 以Reader或InputStream實例的形式提供。我們還需要提供一個基底 URI,用於轉換 XML 中可能存在的相對 URI。如果沒有基底 URI,則可以為null 。
這將使用來自該 RDF-XML 文件的資料填充我們的Model實例。
7.總結
在本文中,我們簡要介紹了 RDF 格式以及用於處理該格式的 Apache Jena 函式庫。使用它還可以實現更多功能,因此下次您需要處理關聯資料時,非常值得一看。
與往常一樣,本文中的所有範例都可以在 GitHub 上找到。