Hibernate 和 Spring Data JPA 中的 N+1 問題
1. 概述
Spring JPA 和 Hibernate 為無縫資料庫通訊提供了強大的工具。但是,由於客戶端將更多控制權委託給框架,因此產生的查詢結果可能遠非最佳。
在本教程中,我們將回顧使用 Spring JPA 和 Hibernate 時常見的N +1 問題。我們將檢查可能導致問題的不同情況。
2.社群媒體平台
為了更好地形象化問題,我們需要概述實體之間的關係。我們以一個簡單的社群網路平台為例。只有Users和Posts :
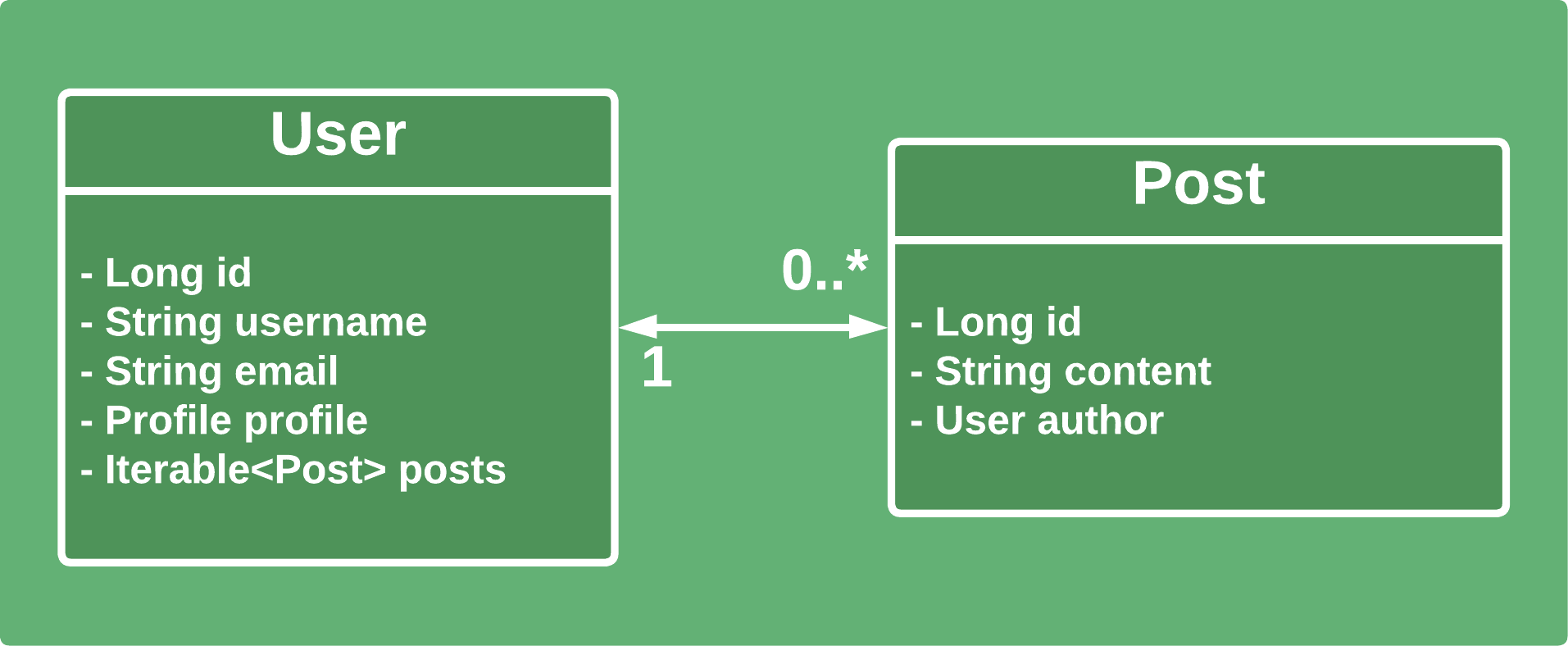
我們在圖中使用Iterable ,並且我們將為每個範例提供具體的實作: List或Set 。
為了測試請求數量,我們將使用專用庫而不是檢查日誌。但是,我們將參考日誌來更好地理解請求的結構。
如果每個範例中未明確提及,則假定關係的取得類型為預設值。所有to-one關係都有急切的獲取,而to-many則有惰性。此外,程式碼範例使用 Lombok 來減少程式碼中的雜訊。
N +1問題
N +1 問題是指對於單一請求(例如取得Users ,我們向每個User發出額外請求以取得其資訊的情況。儘管此問題通常與延遲載入有關,但情況並非總是如此。
我們可以在任何類型的關係中遇到這個問題。然而,它通常產生於many-to-many或one-to-many關係。
3.1.延遲獲取
首先我們來看看延遲載入是如何導致N +1問題的。我們將考慮以下範例:
@Entity
public class User {
@Id
private Long id;
private String username;
private String email;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "author")
protected List<Post> posts;
// constructors, getters, setters, etc.
}Users與Posts具有one-to-many關係。這意味著每個User有多個Posts 。我們沒有明確確定字段的獲取策略。該策略是從註釋中推斷出來的。如前面所提到的,在@OneToMany預設情況下具有延遲取得:
@Target({METHOD, FIELD})
@Retention(RUNTIME)
public @interface OneToMany {
Class targetEntity() default void.class;
CascadeType[] cascade() default {};
FetchType fetch() default FetchType.LAZY;
String mappedBy() default "";
boolean orphanRemoval() default false;
}如果我們嘗試獲取所有Users ,則延遲獲取不會獲取比我們訪問的更多的資訊:
@Test
void givenLazyListBasedUser_WhenFetchingAllUsers_ThenIssueOneRequests() {
getUserService().findAll();
assertSelectCount(1);
}因此,為了獲取所有Users ,我們將發出一個請求。讓我們嘗試訪問Posts. Hibernate 將發出額外的請求,因為未事先取得資訊。對於單一User ,這意味著總共有兩個請求:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenLazyListBasedUser_WhenFetchingOneUser_ThenIssueTwoRequest(Long id) {
getUserService().getUserByIdWithPredicate(id, user -> !user.getPosts().isEmpty());
assertSelectCount(2);
}getUserByIdWithPredicate(Long, Predicate)方法過濾用戶,但其測試的主要目標是觸發載入。我們將有 1+1 請求,但如果我們擴展它,我們將遇到N +1 問題:
@Test
void givenLazyListBasedUser_WhenFetchingAllUsersCheckingPosts_ThenIssueNPlusOneRequests() {
int numberOfRequests = getUserService().countNumberOfRequestsWithFunction(users -> {
List<List<Post>> usersWithPosts = users.stream()
.map(User::getPosts)
.filter(List::isEmpty)
.toList();
return users.size();
});
assertSelectCount(numberOfRequests + 1);
}我們應該小心延遲獲取。在某些情況下,延遲載入對於減少從資料庫取得的資料是有意義的。但是,如果我們在大多數情況下訪問延遲獲取的信息,我們可能會增加請求量。為了做出最佳判斷,我們必須調查訪問模式。
3.2.急切獲取
大多數情況下,急切載重可以幫助我們解決N +1問題。然而,結果取決於我們實體之間的關係。讓我們考慮一個類似的User類,但具有明確設定的急切獲取:
@Entity
public class User {
@Id
private Long id;
private String username;
private String email;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "author", fetch = FetchType.EAGER)
private List<Post> posts;
// constructors, getters, setters, etc.
}如果我們取得單一用戶,取得類型將強制 Hibernate 在單一請求中載入所有資料:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerListBasedUser_WhenFetchingOneUser_ThenIssueOneRequest(Long id) {
getUserService().getUserById(id);
assertSelectCount(1);
}同時,獲取所有用戶的情況也發生了變化。無論我們是否要使用Posts ,我們都會立即得到N +1:
@Test
void givenEagerListBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequests() {
List<User> users = getUserService().findAll();
assertSelectCount(users.size() + 1);
}雖然 eager fetch 改變了 Hibernate 拉取資料的方式,但很難稱之為成功的最佳化。
4. 多重收藏
讓我們在我們的初始域中引入Groups :
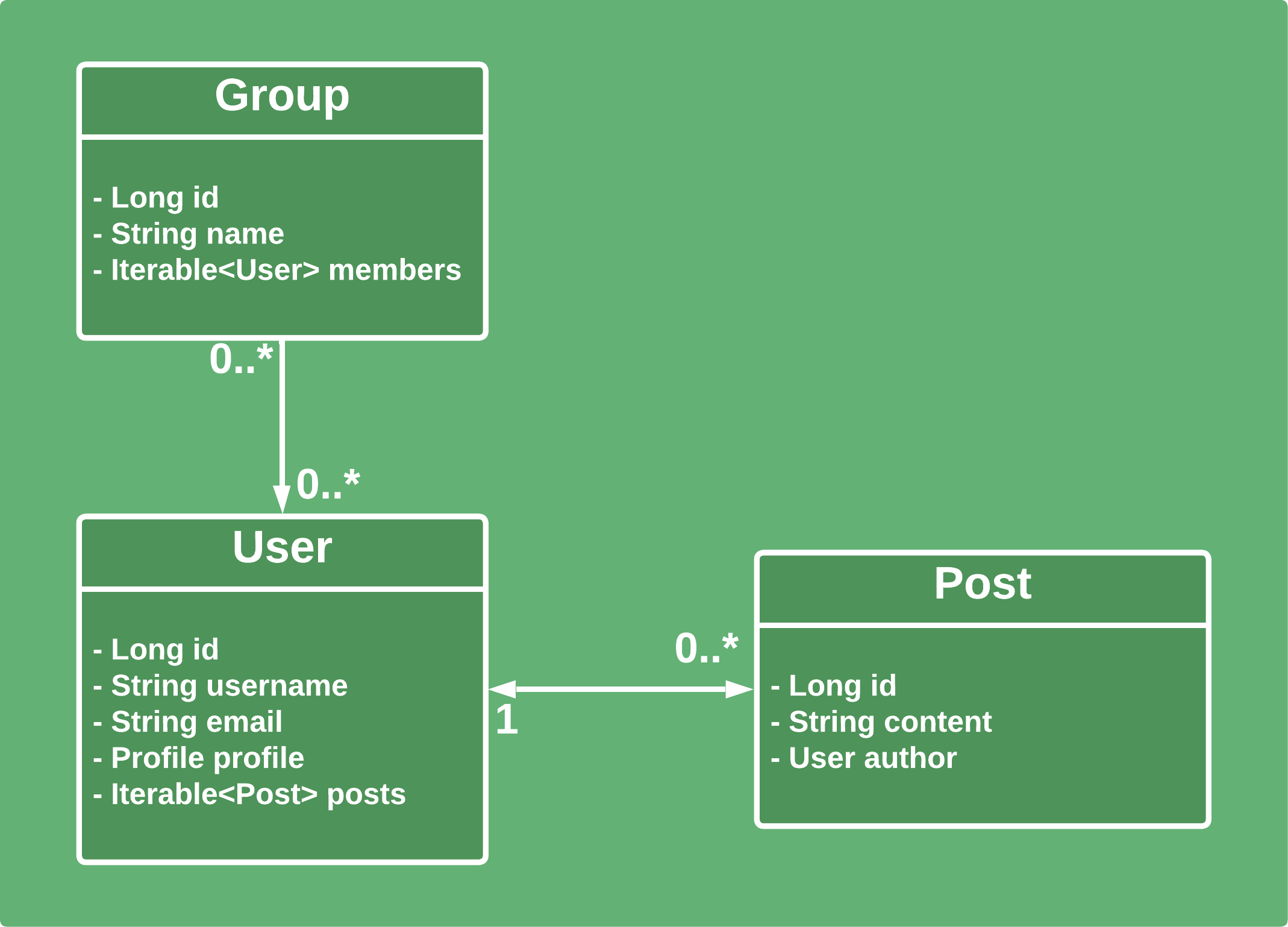
此Group包含Users List :
@Entity
public class Group {
@Id
private Long id;
private String name;
@ManyToMany
private List<User> members;
// constructors, getters, setters, etc.
}4.1.延遲獲取
這種關係的行為通常與前面的延遲獲取範例類似。每次訪問延遲提取的資訊時,我們都會收到一個新請求。
因此,除非我們直接訪問用戶,否則我們將只有一個請求:
@Test
void givenLazyListBasedGroup_whenFetchingAllGroups_thenIssueOneRequest() {
groupService.findAll();
assertSelectCount( 1);
}
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenLazyListBasedGroup_whenFetchingAllGroups_thenIssueOneRequest(Long groupId) {
Optional<Group> group = groupService.findById(groupId);
assertThat(group).isPresent();
assertSelectCount(1);
}但是,如果我們嘗試存取群組中的每個User ,就會產生N +1 問題:
@Test
void givenLazyListBasedGroup_whenFilteringGroups_thenIssueNPlusOneRequests() {
int numberOfRequests = groupService.countNumberOfRequestsWithFunction(groups -> {
groups.stream()
.map(Group::getMembers)
.flatMap(Collection::stream)
.collect(Collectors.toSet());
return groups.size();
});
assertSelectCount(numberOfRequests + 1);
}countNumberOfRequestsWithFunction(ToIntFunction)方法對請求進行計數並觸發延遲載入。
4.2.急切獲取
讓我們檢查一下急切獲取的行為。當請求單一群組時,我們將得到以下結果:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerListBasedGroup_whenFetchingAllGroups_thenIssueNPlusOneRequests(Long groupId) {
Optional<Group> group = groupService.findById(groupId);
assertThat(group).isPresent();
assertSelectCount(1 + group.get().getMembers().size());
}這是合理的,因為我們需要迫切地獲取每個User的資訊。同時,當我們獲取所有組別時,請求數量顯著跳躍:
@Test
void givenEagerListBasedGroup_whenFetchingAllGroups_thenIssueNPlusMPlusOneRequests() {
List<Group> groups = groupService.findAll();
Set<User> users = groups.stream().map(Group::getMembers).flatMap(List::stream).collect(Collectors.toSet());
assertSelectCount(groups.size() + users.size() + 1);
}我們需要取得有關Users的信息,然後,對於每個User,我們取得他們的Posts 。從技術上講,我們有N+M +1 的情況。因此,惰性獲取和急切獲取都不能完全解決問題。
4.3.使用集
讓我們以不同的方式處理這種情況。讓我們用Sets替換Lists 。我們將使用急切獲取,因為惰性Sets和List行為類似:
@Entity
public class Group {
@Id
private Long id;
private String name;
@ManyToMany(fetch = FetchType.EAGER)
private Set<User> members;
// constructors, getters, setters, etc.
}
@Entity
public class User {
@Id
private Long id;
private String username;
private String email;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "author", fetch = FetchType.EAGER)
protected Set<Post> posts;
// constructors, getters, setters, etc.
}
@Entity
public class Post {
@Id
private Long id;
@Lob
private String content;
@ManyToOne
private User author;
// constructors, getters, setters, etc.
}讓我們執行類似的測試來看看這是否有什麼不同:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerSetBasedGroup_whenFetchingAllGroups_thenCreateCartesianProductInOneQuery(Long groupId) {
groupService.findById(groupId);
assertSelectCount(1);
}我們在獲得單一Group同時解決了N +1 問題。 Hibernate 在一個請求中獲取了Users及其Posts 。另外,取得所有Groups減少了請求數量,但仍是N +1:
@Test
void givenEagerSetBasedGroup_whenFetchingAllGroups_thenIssueNPlusOneRequests() {
List<Group> groups = groupService.findAll();
assertSelectCount(groups.size() + 1);
}雖然我們部分解決了這個問題,但我們又製造了另一個問題。 Hibernates 使用多個 JOIN,創建笛卡爾積:
SELECT g.id, g.name, gm.interest_group_id,
u.id, u.username, u.email,
p.id, p.author_id, p.content
FROM group g
LEFT JOIN (group_members gm JOIN user u ON u.id = gm.members_id)
ON g.id = gm.interest_group_id
LEFT JOIN post p ON u.id = p.author_id
WHERE g.id = ?查詢可能會變得過於複雜,並且由於物件之間有許多依賴關係,因此會提取大量資料庫。
由於集合的性質,Hibernate 可以確保結果集中的所有重複項都來自笛卡爾積。這對於列表來說是不可能的,因此應在單獨的請求中獲取數據,以在使用列表時保持其完整性。
大多數關係都符合集合不變量。允許Users擁有多個相同的Posts是沒有意義的。同時,我們可以明確地提供獲取模式,而不是依賴預設行為。
5. 權衡
選擇提取類型可能有助於減少簡單情況下的請求數量。然而,使用簡單的註釋,我們對查詢產生的控制有限。此外,它是透明完成的,領域模型中的微小變化可能會產生巨大的影響。
解決該問題的最佳方法是觀察系統的行為並識別存取模式。建立單獨的方法、SQL 和 JPQL 查詢有助於針對每種情況進行客製化。另外,我們可以使用 fetch 模式來提示 Hibernate 如何載入相關實體。
新增簡單的測試可以幫助解決模型中的意外變更。這樣,我們可以確保新關係不會產生笛卡爾積或N +1 問題。
六,結論
雖然急切地獲取類型可以緩解其他查詢的一些簡單問題,但它可能會導致其他問題。有必要測試應用程式以確保其效能。
獲取類型和關係的不同組合通常會產生意想不到的結果。這就是為什麼最好透過測試來覆蓋關鍵部分。
與往常一樣,本教程中的所有程式碼都可以在 GitHub 上取得。