每個連接線程數 vs 每個請求線程數
1. 簡介
在本教程中,我們將比較兩種常用的伺服器執行緒模型:每個連接一個執行緒和每個請求一個執行緒。
首先,我們將準確地定義「連線」和「請求」的含義。然後我們將按照不同的範例實作兩個基於套接字的 Java Web 伺服器。最後,我們來看看一些關鍵要點。
2. 連線與請求執行緒模型
讓我們從一些簡潔的定義開始。
執行緒模型是程式如何以及何時創建和同步執行緒以實現並發和多任務的方法。為了說明,我們參考客戶端和伺服器之間的 HTTP 連線。我們將請求視為客戶端在建立連線期間向伺服器發出的一次單次執行。
當客戶端需要與伺服器通訊時,它會實例化一個新的 HTTP-over-TCP 連線並啟動一個新的 HTTP-over-TCP 請求。為了避免開銷,如果連線已經存在,客戶端可以重複使用相同的連線來傳送另一個請求。這種機制被稱為 Keep-Alive,它從 HTTP 1.0 開始就已存在,並在 HTTP 1.1 中成為預設行為。
了解這個概念,我們現在可以介紹本文所比較的兩種執行緒模型。
在下圖中,我們可以看到,如果我們使用「每個連接一個線程」範例,Web 伺服器將如何為每個連接使用一個線程;而當採用「每個請求一個線程」模型時,Web 伺服器將為每個請求使用一個線程,無論該請求是否屬於現有連接:
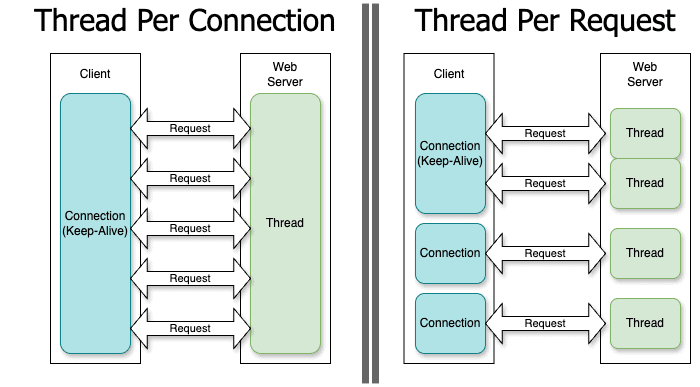
在下面的部分中,我們將確定這兩種方法的優缺點,並查看一些使用套接字的程式碼範例。這些範例將是真實案例場景的簡化版本。為了使程式碼盡可能簡單,我們將避免引入在實際伺服器架構中廣泛使用的最佳化(例如執行緒池) 。
3. 理解每個連接的線程數
採用每個連接一個執行緒的方法,每個客戶端連線都會獲得其專用執行緒。同一個執行緒處理來自該連線的所有請求。
讓我們透過建立一個簡單的基於 Java 套接字的伺服器來說明每個連接線程模型的工作原理:
public class ThreadPerConnectionServer {
private static final int PORT = 8080;
public static void main(String[] args) {
try (ServerSocket serverSocket = new ServerSocket(PORT)) {
logger.info("Server started on port {}", PORT);
while (!serverSocket.isClosed()) {
try {
Socket newClient = serverSocket.accept();
logger.info("New client connected: {}", newClient.getInetAddress());
ClientConnection clientConnection = new ClientConnection(newClient);
new ThreadPerConnection(clientConnection).start();
} catch (IOException e) {
logger.error("Error accepting connection", e);
}
}
} catch (IOException e) {
logger.error("Error starting server", e);
}
}
}
}
ClientConnection是一個簡單的包裝器,它實作了Closeable接口,並且包括我們將用來讀取請求和寫迴響應的BufferedReader和PrintWriter :
public class ClientConnection implements Closeable {
// ...
public ClientConnection(Socket socket) throws IOException {
this.socket = socket;
this.reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
this.writer = new PrintWriter(socket.getOutputStream(), true);
}
@Override
public void close() throws IOException {
try (Writer writer = this.writer; Reader reader = this.reader; Socket socket = this.socket) {
// resources all closed when this block exits
}
}
}ThreadPerConnectionServer在連接埠8080上建立一個ServerSocket ,並重複呼叫accept()方法,該方法會阻止執行,直到接收到新的連線為止。
當客戶端連線時,伺服器立即啟動一個新的ThreadPerConnection執行緒:
public class ThreadPerConnection extends Thread {
// ...
@Override
public void run() {
try (ClientConnection client = this.clientConnection) {
String request;
while ((request = client.getReader().readLine()) != null) {
Thread.sleep(1000); // simulate server doing work
logger.info("Processing request: {}", request);
clientConnection.getWriter()
.println("HTTP/1.1 200 OK - Processed request: " + request);
logger.info("Processed request: {}", request);
}
} catch (Exception e) {
logger.error("Error processing request", e);
}
}
}這個簡單的實作從客戶端讀取輸入並使用回應前綴將其回顯。當沒有更多請求從該單一連線傳入時,套接字將利用try-with-resource語法自動關閉。每個連接都有其專用線程,而while循環中的主線程仍然可以自由接受新連接。
每個連接一個執行緒模型最顯著的優點是其極為簡潔且易於實現。如果有 10 個用戶端建立 10 個並發連接,則 Web 伺服器需要 10 個執行緒來同時為所有用戶端提供服務。如果同一個執行緒服務同一個用戶,應用程式可以避免執行緒上下文切換。
4. 理解每個請求的執行緒數
使用每個請求一個執行緒的模型,即使使用的連線是持久的,也會使用不同的執行緒來處理每個請求。
與前一種情況一樣,讓我們來看看一個採用每個請求一個執行緒的執行緒模型的基於 Java 套接字的伺服器的簡化範例:
public class ThreadPerRequestServer {
// ...
public static void main(String[] args) {
List<ClientSocket> clientSockets = new ArrayList<ClientSocket>();
try (ServerSocket serverSocket = new ServerSocket(PORT)) {
logger.info("Server started on port {}", PORT);
while (!serverSocket.isClosed()) {
acceptNewConnections(serverSocket, clientSockets);
handleRequests(clientSockets);
}
} catch (IOException e) {
logger.error("Server error: {}", e.getMessage());
} finally {
closeClientSockets(clientSockets);
}
}
}
在這裡,我們維護一個clientSockets,而不是像以前那樣只維護一個。伺服器接受新的連接,直到伺服器套接字關閉,並處理來自它們的所有傳入請求。當伺服器套接字關閉時,我們還需要關閉每個仍處於活動狀態的客戶端套接字連線(如果有)。
首先,讓我們定義接受新連線的方法:
private static void acceptNewConnections(ServerSocket serverSocket, List<Socket> clientSockets)
throws SocketException {
serverSocket.setSoTimeout(100);
try {
Socket newClient = serverSocket.accept();
ClientConnection clientConnection = new ClientConnection(newClient);
clientConnections.add(clientConnection);
logger.info("New client connected: {}", newClient.getInetAddress());
} catch (IOException ignored) {
// ignored
}
}理論上,接受新連線的方法和處理請求的方法應該在兩個不同的主執行緒中執行。在這個簡單的例子中,為了不阻塞唯一的主執行緒和執行流程,我們需要在伺服器上設定一個短的套接字逾時。如果100ms內沒有收到連接,我們就認為沒有可用的連接,並繼續使用下一個方法來處理請求:
private static void handleRequests(List<Socket> clientSockets) throws IOException {
Iterator<ClientConnection> iterator = clientSockets.iterator();
while (iterator.hasNext()) {
Socket clientSocket = iterator.next();
if (clientSocket.getSocket().isClosed()) {
logger.info("Client disconnected: {}", clientSocket.getInetAddress());
iterator.remove();
continue;
}
try {
BufferedReader reader = client.getReader();
if (reader.ready()) {
String request = reader.readLine();
if (request != null) {
new ThreadPerRequest(client.getWriter(), request).start();
}
}
} catch (IOException e) {
logger.error("Error reading from client {}", client.getSocket()
.getInetAddress(), e);
}
}
}在此方法中,對於每個包含要處理的新有效請求的連接,我們啟動一個僅處理該單一請求的新執行緒:
public class ThreadPerRequest extends Thread {
// ...
@Override
public void run() {
try {
Thread.sleep(1000); // simulate server doing work
logger.info("Processing request: {}", request);
writer.println("HTTP/1.1 200 OK - Processed request: " + request);
logger.info("Processed request: {}", request);
} catch (Exception e) {
logger.error("Error processing request: {}", e.getMessage());
}
}
}在ThreadPerRequest,我們不會關閉客戶端連接,並且我們只處理一個請求。一旦請求被處理,短暫的線程就會被關閉。請注意,在實際的應用程式伺服器中,使用執行緒池時,請求結束時執行緒不會停止,但會重新用於另一個請求。
使用這種線程模型,伺服器可能會創建大量線程,並在它們之間進行高上下文切換,但通常會更好地擴展:我們對並發連接沒有上限。
5 .比較表
下表比較了這兩種方法,並考慮了伺服器架構的一些決定性方面:
| 特徵 | 每個連接線程數 | 每個請求的線程數 |
|---|---|---|
| 執行緒執行生命週期 | 長期存在,僅在連線關閉時暫停 | 短暫的,請求處理後立即暫停 |
| **上下文切換 | ||
| 載入** | 低,受並發連線數限制 | 針對每個請求進行高速上下文切換 |
| 可擴展性 | 限制伺服器可以建立的連線數 | 高效,可能具有很好的擴展性。 |
| 適應性 | 已知連接數 | 不同的請求量 |
如果 JVM 提供的最大線程數為 N,且我們採用每個連接一個線程,則最多會有 N 個並發客戶端。另一個客戶端需要等到一個客戶端斷開連接,這可能需要很長時間。如果我們採用每個請求一個線程,那麼我們最多可以同時處理 N 個請求。附加請求將保持排隊狀態,直到請求完成為止,這通常需要很短的時間。
最後,如果已知連接數,則每個連接線程模型會運行良好:實現的簡單性和低上下文切換會產生良好的影響。當處理不可預測的突發大量請求時,應該選擇每個請求一個執行緒的模型。
6 .結論
在本文中,我們比較了兩種常用的伺服器線程模型。每個連接線程和每個請求線程模型之間的選擇取決於應用程式的特定要求和預期的流量模式。一般來說,每個連接線程為已知數量的客戶端提供了簡單性和可預測性,而每個請求線程在可變或高負載條件下提供了更大的可擴展性和靈活性。
上述範例的程式碼可在 GitHub 上找到。