Java的字符串常量池位於哪裡,堆或堆棧在哪裡?
1.簡介
每當我們聲明一個變量或創建一個對象時,它就會存儲在內存中。在較高的級別上,Java將內存分為兩個塊:堆棧和堆。兩種存儲器均存儲特定類型的數據,並且具有不同的存儲和訪問模式。
在本教程中,我們將研究不同的參數,並了解哪個是最適合存儲String常量池的區域。
2.字符串常量池
String常量池是一個特殊的存儲區。當我們聲明String文字時,JVM在池中創建對象並將其引用存儲在堆棧中。在內存中創建每個String對象之前,JVM執行一些步驟來減少內存開銷。
字符串常量池在其實現中Hashmap Hashmap每個存儲桶均包含具有相同哈希碼String在Java的早期版本中,池的存儲區域是固定大小的,並且通常會導致“Could not reserve enough space for object heap”錯誤。
當系統加載類時, String文字都將進入應用程序級池。這是因為String文字必須是相同的Object 。在這些情況下,池中的數據應可用於每個類而沒有任何依賴關係。
通常,棧stack存儲短期的數據。它包括局部基本變量,堆對象的引用以及執行中的方法。堆允許動態分配內存,在運行時存儲Java對象和JRE類。
堆heap允許全局訪問,並且在應用程序的生存期內,堆中的數據存儲可用於所有線程,而堆棧上的數據存儲具有私有作用域,只有所有者線程可以訪問它們。
棧stack將數據存儲在連續的存儲塊中,並允許隨機訪問。如果類需要String ,則由於堆棧的LIFO(後進先出)規則,該類可能不可用。相反,堆heap會動態分配內存,並允許我們以任何方式訪問數據。
假設我們有一個由不同類型的變量組成的代碼段。堆棧將存儲int文字String和Demo對象的.任何對象的值都將存儲在堆中,所有String文字都放入堆中的池中:
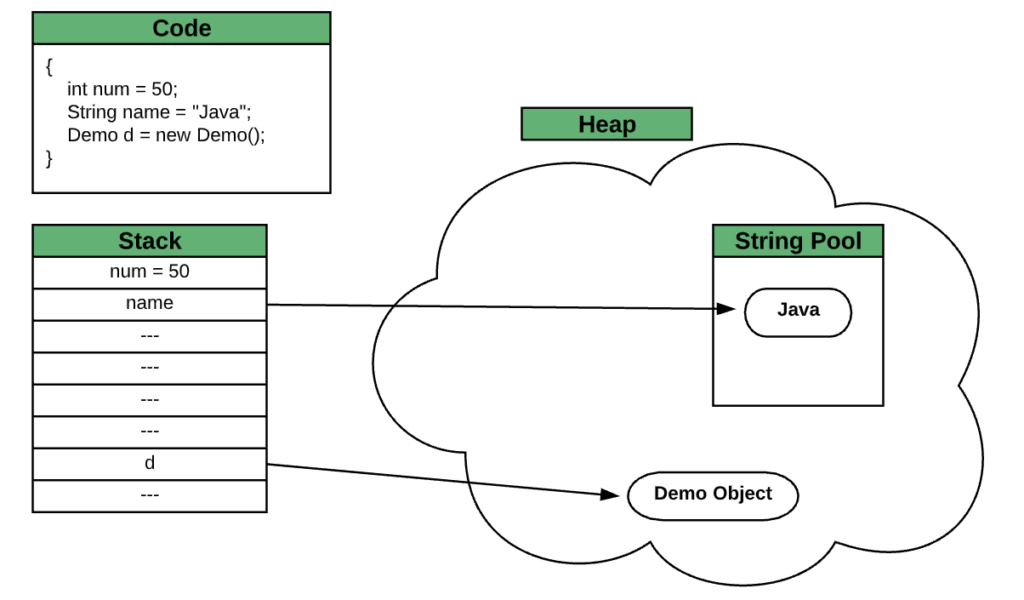
線程完成執行後,將立即釋放在堆棧上創建的變量。相反,垃圾收集器回收堆中的資源。同樣,垃圾收集器從池中收集未引用的項目。
池的默認大小在不同平台上可能會有所不同。無論如何,它仍然比可用堆棧大小大得多。在JDK 7之前,該池是permgen空間的一部分,從JDK 7到現在,它是主堆內存的一部分。
3.結論
在這篇簡短的文章中,我們了解了String常量池的存儲區域。棧和堆具有不同的特性來存儲和訪問數據。從內存分配到其訪問和可用性,堆是最適合存儲String常量池的區域。
實際上,常量從未成為棧stack內存的一部分。