RabbitMQ 中的通道和連接
一、簡介
在這個快速教程中,我們將展示如何使用與兩個核心概念相關的 RabbitMQ 的 API:連接和通道。
2. RabbitMQ 快速回顧
RabbitMQ 是 AMQP(高級消息隊列協議)的流行實現,被各種規模的公司廣泛用於處理他們的消息傳遞需求。
從應用程序的角度來看,我們通常關注 AMQP 的主要實體:虛擬主機、交換和隊列。正如我們在之前的文章中已經討論過這些概念一樣,在這裡,我們將重點關注兩個討論較少的概念的細節:連接和通道。
3. 連接
客戶端與 RabbitMQ 代理交互的第一步是建立連接。 AMPQ 是一種應用層協議,因此這種連接發生在傳輸層協議之上。這可以是常規 TCP 連接或使用 TLS 加密的連接。 Connection 的主要作用是提供一個安全的管道,客戶端可以通過它與代理進行交互。
這意味著在連接建立期間,客戶端必須向服務器提供有效的憑據。服務器可能支持不同的憑證類型,包括常規用戶名/密碼、SASL、X.509 密碼或任何支持的機制。
除了安全之外,連接建立階段還負責協商 AMPQ 協議的某些方面。此時,如果客戶端和/或服務器無法就協議版本或調整參數值達成一致,則不會建立連接,並且將關閉傳輸級連接。
3.1。在 Java 應用程序中創建連接
使用 Java 時,與 RabbitMQ 瀏覽器通信的標準方法是使用amqp-client Java 庫。我們可以使用添加相應的 Maven 依賴項將這個庫添加到我們的項目中:
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.16.0</version>
</dependency>該工件的最新版本可在Maven Central上獲得。
這個庫使用工廠模式來創建新的連接。首先,我們創建一個新的ConnectionFactory實例並設置創建連接所需的所有參數。至少,這需要通知 RabbitMQ 主機的地址:
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("amqp.example.com");一旦我們完成了這些參數的設置,我們使用newConnection()工廠方法來創建一個新的Connection實例:
Connection conn = factory.newConnection();4. 渠道
簡單地說,AMQP 通道是一種允許在單個連接之上多路復用多個邏輯流的機制。這允許在客戶端和服務器端更好地使用資源,因為建立連接是一項相對昂貴的操作。
客戶端創建一個或多個通道,以便它可以向代理髮送命令。這包括與發送和/或接收消息相關的命令。
通道還提供了一些關於協議邏輯的額外保證:
- 給定通道的命令總是按照它們發送的順序執行。
- 給定客戶端通過單個連接打開多個通道的場景,實現可以在它們之間分配可用帶寬
- 雙方都可以發出流控制命令,通知對等方應該停止發送消息。
通道的一個關鍵方面是它的生命週期綁定到用於創建它的連接。這意味著如果我們關閉一個連接,所有關聯的通道也將被關閉。
4.1。在 Java 應用程序中創建通道
使用amqp-client庫的 Java 應用程序使用前者的createChannel()方法從現有Connection創建新Channel :
channel = conn.createChannel();一旦我們有了Channel,我們就可以向服務器發送命令。例如,要創建隊列,我們使用queueDeclare()方法:
channel.queueDeclare("example.queue", true, false, true, null);這段代碼“聲明”了一個隊列,這是 AMQP 表示“如果不存在則創建”的方式。隊列名稱後面的附加參數定義了它的附加特徵:
-
durable性:此聲明是持久的,這意味著它將在服務器重新啟動後繼續存在 -
exclusive:此隊列僅限於與聲明它的通道關聯的連接 -
autodelete:一旦不再使用,服務器將刪除隊列 -
args:帶有用於調整隊列行為的參數的可選映射;例如,我們可以使用這些參數來定義消息和死信行為的 TTL
現在,要使用默認交換向此隊列發布消息,我們使用basicPublish()方法:
channel.basicPublish("", queue, null, payload);此代碼使用隊列名稱作為其路由鍵向默認交換器發送消息。
5. 渠道分配策略
讓我們考慮一個我們使用消息傳遞系統的場景:CQRS(命令查詢責任分離)應用程序。簡而言之,基於 CQRS 的應用程序有兩個獨立的路徑:命令和查詢。命令可以更改數據但從不返回值。另一方面,查詢返回值但從不修改它們。
由於命令路徑從不返回任何數據,因此服務可以異步執行它們。在一個典型的實現中,我們有一個 HTTP POST 端點,它在內部構建一條消息並將其發送到隊列以供以後處理。
現在,對於一個必須處理數十甚至數百個並發請求的服務來說,每次都打開連接和通道並不是一個現實的選擇。相反,更好的方法是使用通道池。
當然,這會導致下一個問題:我們應該創建單個連接並從中創建通道還是使用多個連接?
5.1。單連接/多通道
在此策略中,我們將使用單個連接並創建一個容量等於服務可以管理的最大並發連接數的通道池。對於傳統的每請求線程模型,這應該設置為與請求處理程序線程池相同的大小。
這種策略的缺點是,在較重的負載下,我們必須通過關聯的通道一次發送一個命令這一事實意味著我們必須使用同步機制。這反過來又在命令路徑中增加了額外的延遲,我們希望將其最小化。
5.2.每線程連接策略
另一種選擇是走向另一個極端並使用Connection池,因此永遠不會爭用通道。對於每個Connection ,我們將創建一個Channel ,處理程序線程將使用該 Channel 向服務器發出命令。
然而,我們從客戶端移除同步是有代價的。代理必須為每個連接分配額外的資源,例如套接字描述符和狀態信息。此外,服務器必須在客戶端之間分配可用吞吐量。
6. 基準策略
為了評估這些候選策略,讓我們為每個策略運行一個簡單的基準。基準測試包括並行運行多個工作程序,這些工作程序發送一千條每條 4 KB 的消息。在構建時,worker 會收到一個Connection ,它將創建一個Channel來發送命令。它還接收迭代次數、有效負載大小和用於通知測試運行器它已完成發送消息的CountDownLatch :
public class Worker implements Callable<Worker.WorkerResult> {
// ... field and constructor omitted
@Override
public WorkerResult call() throws Exception {
try {
long start = System.currentTimeMillis();
for (int i = 0; i < iterations; i++) {
channel.basicPublish("", queue, null, payload);
}
long elapsed = System.currentTimeMillis() - start;
channel.queueDelete(queue);
return new WorkerResult(elapsed);
} finally {
counter.countDown();
}
}
public static class WorkerResult {
public final long elapsed;
WorkerResult(long elapsed) {
this.elapsed = elapsed;
}
}
}除了通過減少鎖存器來表明它已經完成了它的工作外,worker 還返回一個WorkerResult實例,其中包含發送所有消息的經過時間。雖然這裡我們只有一個long值,但我們可以使用擴展它來返回更多細節。
控制器根據正在評估的策略創建連接工廠和工人。對於單個連接,它會創建Connection實例並將其傳遞給每個工作人員:
@Override
public Long call() {
try {
Connection connection = factory.newConnection();
CountDownLatch counter = new CountDownLatch(workerCount);
List<Worker> workers = new ArrayList<>();
for( int i = 0 ; i < workerCount ; i++ ) {
workers.add(new Worker("queue_" + i, connection, iterations, counter,payloadSize));
}
ExecutorService executor = new ThreadPoolExecutor(workerCount, workerCount, 0,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(workerCount, true));
long start = System.currentTimeMillis();
executor.invokeAll(workers);
if( counter.await(5, TimeUnit.MINUTES)) {
long elapsed = System.currentTimeMillis() - start;
return throughput(workerCount,iterations,elapsed);
}
else {
throw new RuntimeException("Timeout waiting workers to complete");
}
}
catch(Exception ex) {
throw new RuntimeException(ex);
}
}對於多連接策略,我們為每個工作人員創建一個新Connection :
for (int i = 0; i < workerCount; i++) {
Connection conn = factory.newConnection();
workers.add(new Worker("queue_" + i, conn, iterations, counter, payloadSize));
}throughput函數計算的基準度量將是完成所有工作人員所需的總時間除以工作人員數量:
private static long throughput(int workerCount, int iterations, long elapsed) {
return (iterations * workerCount * 1000) / elapsed;
}請注意,我們需要將分子乘以 1000,以便我們以秒為單位獲得消息吞吐量。
7. 運行基準
這些是我們對這兩種策略進行基準測試的結果。對於每個工人數量,我們已經運行了 10 次基準測試,並使用平均值作為 tar 特定工人/策略的吞吐量度量。按照今天的標準,環境本身是適度的:
- CPU:雙核 i7 戴爾筆記本 @ 3.0 GHz
- 總內存:16 GB
- RabbitMQ:在 Docker 上運行的 3.10.7(具有 4 GB RAM 的 docker-machine)
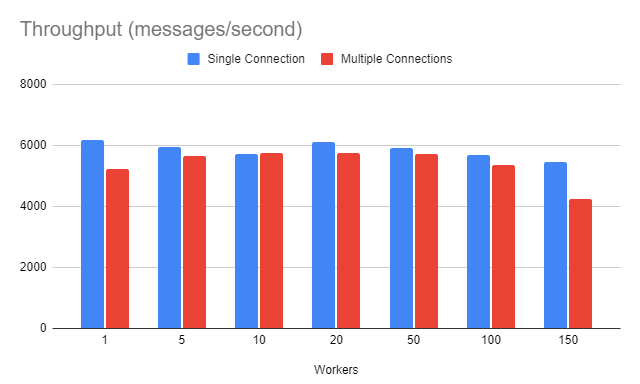
對於這個特定的環境,我們看到單連接策略有一點優勢。對於 150 名工人的情況,這種優勢似乎有所增加。
8. 選擇策略
鑑於基準測試結果,我們無法指出明確的贏家。對於 5 到 100 之間的工人數量,結果或多或少是相同的。在那之後,與多個連接相關的開銷似乎高於在單個連接上處理多個通道。
此外,我們必須考慮到測試工作者只做一件事:將固定消息發送到隊列。現實世界的應用程序,例如我們提到的 CQRS 應用程序,通常在發送消息之前和/或之後做一些額外的工作。因此,要選擇最佳策略,推薦的方法是使用盡可能接近生產環境的配置運行您自己的基準測試。
9. 結論
在本文中,我們探討了 RabbitMQ 中的通道和連接的概念,以及我們如何以不同的方式使用它們。像往常一樣,完整的代碼可以在 GitHub 上找到。