Java HashMap負載因子
1.概述
在本文中,我們將看到Java HashMap負載因子的重要性以及它如何影響HashMap的性能。
2.什麼是HashMap ?
HashMap類屬於Java Collection框架,並提供Map接口的基本實現。當我們要根據鍵值對存儲數據時,可以使用它。這些鍵值對稱為映射條目,由Map.Entry類表示。
3. HashMap內部
在討論負載係數之前,讓我們回顧一下以下術語:
- 雜湊
- 容量
- 臨界點
- 重新哈希
- 碰撞
- 雜湊
HashMap遵循哈希原理-一種將對像數據映射到某個代表性整數值的算法。哈希函數應用於鍵對像以計算存儲桶的索引,以便存儲和檢索任何鍵值對。
HashMap的存儲桶數。初始容量是創建M ap時的容量。 HashMap的默認初始容量為16。
HashMap中元素數量的增加,容量也會增加。負載因子是決定何時增加Map容量的度量。默認的負載係數是容量的75%。
HashMap的閾值大約是當前容量和負載因子的乘積。重新哈希是重新計算已存儲條目的哈希碼的過程。簡而言之,當哈希表中的條目數超過閾值時,將Map該Map,使其具有的存儲桶數大約是以前的兩倍。
當哈希函數為兩個不同的鍵返回相同的存儲桶位置時,會發生衝突。
讓我們創建我們的HashMap :
Map<String, String> mapWithDefaultParams = new HashMap<>();
mapWithDefaultParams.put("1", "one");
mapWithDefaultParams.put("2", "two");
mapWithDefaultParams.put("3", "three");
mapWithDefaultParams.put("4", "four");
這是我們Map的結構:
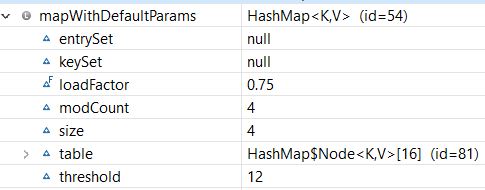
如我們所見,我們的HashMap是使用默認的初始容量(16)和默認的負載係數(0.75)創建的。此外,閾值為16 * 0.75 = 12,這意味著添加第12個條目(鍵值對)後,容量將從16增加到32。
4.自定義初始容量和負載係數
在上一節中,我們使用默認構造函數HashMap在以下各節中,我們將看到如何創建將初始容量和負載因子傳遞給構造函數HashMap
4.1。具有初始容量
首先,讓我們創建一個具有初始容量Map
Map<String, String> mapWithInitialCapacity = new HashMap<>(5);
它將創建一個具有初始容量(5)和默認負載因子(0.75) Map
4.2。具有初始容量和負載係數
同樣,我們可以同時使用初始容量和負載因子Map
Map<String, String> mapWithInitialCapacityAndLF = new HashMap<>(5, 0.5f);
在這裡,它將創建一個空的Map ,其初始容量為5,負載係數為0.5。
5.表現
儘管我們可以靈活選擇初始容量和負載因數,但我們需要明智地選擇它們。它們都影響Map的性能。讓我們深入研究這些參數與性能之間的關係。
5.1。複雜
眾所周知, HashMap內部使用哈希碼作為存儲鍵值對的基礎。如果hashCode()方法編寫得當,則HashMap將在所有存儲桶中分配項目。因此, HashMap O(1)存儲和檢索條目。
但是,當物品數量增加並且鏟斗尺寸固定時,就會出現問題。每個存儲桶中將有更多物品,並且會打擾時間複雜性。
解決方案是,當增加項目數量時,我們可以增加存儲桶的數量。然後,我們可以在所有存儲桶中重新分配項目。這樣,我們將能夠在每個存儲桶中保持恆定數量的項目,並保持O(1)的時間複雜度。
在這裡,負載係數可幫助我們確定何時增加鏟斗數量。在較低的負載係數下,將有更多的自由鏟斗,因此發生碰撞的機會更少。這將有助於我們提高Map性能。因此,我們需要保持較低的負載係數,以實現較低的時間複雜度。
HashMap O(n)的空間複雜度,其中n是條目數。較高的負載因子值會減少空間開銷,但會增加查找成本。
5.2。重新整理
當在項目的數量Map越過閾值限制,則容量Map加倍。如前所述,當容量增加時,我們需要在所有存儲桶中平均分配所有條目(包括現有條目和新條目)。在這裡,我們需要重新哈希。也就是說,對於每個現有的鍵值對,以容量增加為參數再次計算哈希碼。
基本上,當負載係數增加時,複雜度也會增加。進行重新哈希處理以保持所有操作的低負載因數和低複雜度。
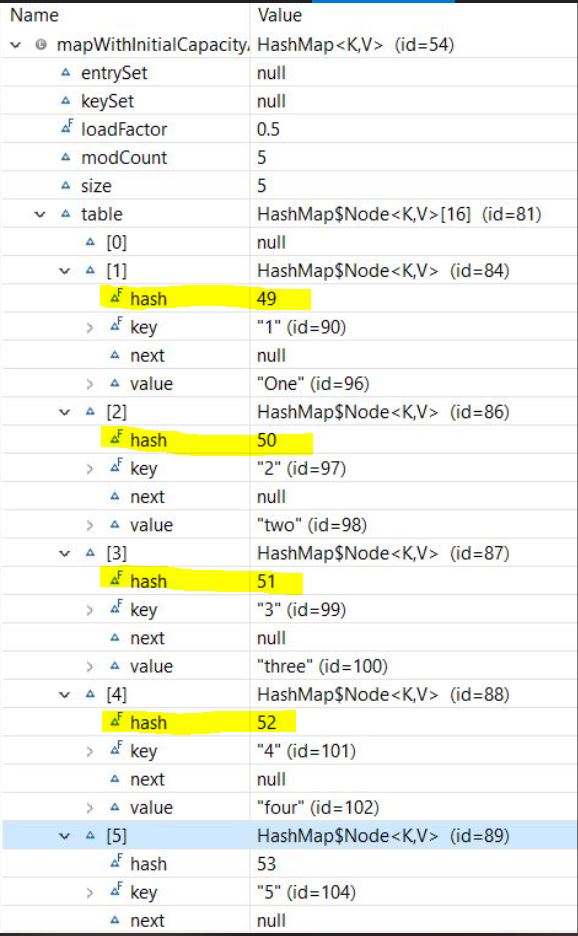
讓我們初始化Map :
Map<String, String> mapWithInitialCapacityAndLF = new HashMap<>(5,0.75f);
mapWithInitialCapacityAndLF.put("1", "one");
mapWithInitialCapacityAndLF.put("2", "two");
mapWithInitialCapacityAndLF.put("3", "three");
mapWithInitialCapacityAndLF.put("4", "four");
mapWithInitialCapacityAndLF.put("5", "five");讓我們看一下Map的結構:
現在,讓我們向Map添加更多條目:
mapWithInitialCapacityAndLF.put("6", "Six");
mapWithInitialCapacityAndLF.put("7", "Seven");
//.. more entries
mapWithInitialCapacityAndLF.put("15", "fifteen");讓我們再次觀察我們的Map結構:
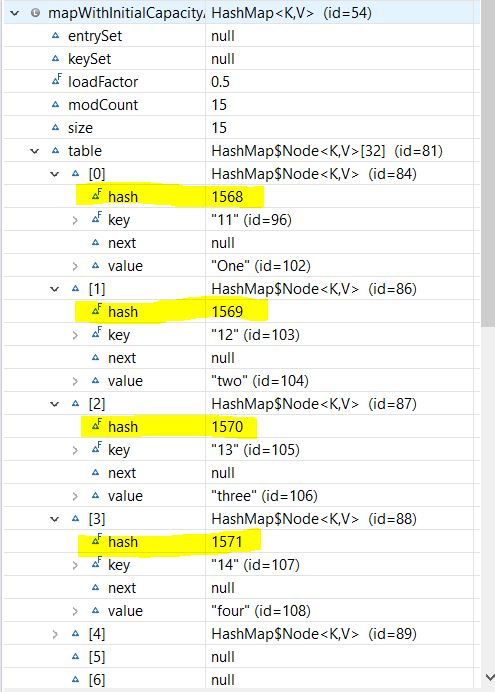
儘管重新哈希處理有助於保持較低的複雜度,但這是一個昂貴的過程。如果我們需要存儲大量數據,則應創建具有足夠容量HashMap這比自動重新哈希處理更有效。
5.3。碰撞
由於哈希碼算法不正確,可能會發生衝突,並且通常會降低Map的性能。
在Java 8之前,Java中的HashMap通過使用LinkedList存儲地圖條目來處理衝突。如果某個鍵最終位於已經存在另一個條目的同一個存儲桶中,則會將其添加到LinkedList的開頭。在最壞的情況下,這將增加O(n)複雜度。
為避免此問題,Java 8和更高版本使用平衡樹(也稱為紅黑樹)而不是LinkedList來存儲衝突條目。 HashMap的最壞情況性能從O(n)提升為O(log n) 。
HashMap最初使用LinkedList.然後,當條目數超過某個閾值時,它將用平衡的二叉樹LinkedList TREEIFY_THRESHOLD常數決定該閾值。當前,該值為8,這意味著如果同一存儲桶中有8個以上的元素,則Map將使用樹來保存它們。
六,結論
在本文中,我們討論了一種最受歡迎的數據結構: HashMap 。我們還看到了負載係數和容量如何影響其性能。