什麼是彈性搜索?
一、概述
在本教程中,我們將開始探索 Elasticsearch 及其附帶的工具。
它是一種可以無縫處理大量數據、自動擴展並持續吸收新數據的工具。
2. 定義
想像一下,我們有一大堆文檔,數以千計,我們想要快速高效地查找特定信息。這就是 Elasticsearch 發揮作用的地方。
想像一個超級聰明的圖書管理員,他巧妙地組織了大量的文件,從而促進了一個簡單的搜索過程。這類似於 Elasticsearch——一種開源搜索和分析引擎,精通管理海量數據,提供我們尋求的精確信息。
Elasticsearch 本質上是分佈式的,並結合了 NoSQL,它使用 JSON 文檔來表示數據,可以很容易地與各種編程語言和系統集成。
Elasticsearch 以其數據處理能力脫穎而出,例如即時存儲、搜索和檢查數據。使用強大的搜索系統,Elasticsearch 將我們文檔中的所有單詞和短語分類到一個易於搜索的列表中。這意味著我們可以對大量數據執行閃電般快速的搜索。
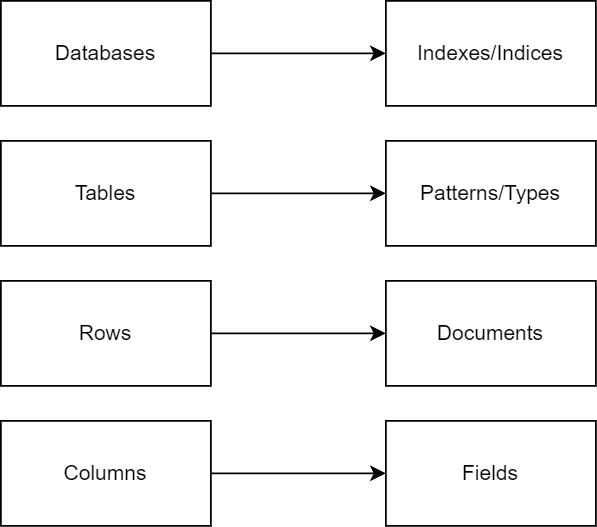
2.1.索引呢?
與關係數據庫管理系統 (RDBMS) 相比,Elasticsearch 具有獨特的數據組織方式。在 RDBMS 中,我們通常使用術語“數據庫”。然而,在 Elasticsearch 中,使用了術語“索引”,它更類似於傳統數據庫中的表。這只是同一概念的不同術語。
此外,在關係數據庫中,我們使用表來組織數據。在 Elasticsearch 中,我們有類似的東西,我們可以將其視為索引模式。在舊版本中,它們曾經被稱為類型。
在這些數據庫或索引中,關係數據庫具有由行和列組成的表。在 Elasticsearch 中,我們可以將行視為文檔,將單個列稱為字段,反映了許多 NoSQL 數據源的結構。
對於那些習慣於使用 MySQL 或 Postgres 等關係數據庫的人來說,了解這個新的面向文檔的搜索引擎類似於擴展我們現有的知識。它幫助我們了解事物如何組合在一起並規劃我們的數據結構。這就像將我們當前的理解轉化為具有自身考慮的新系統。
這是一個有用的比較表:
3. 與 Elasticsearch 交互
與它交互時,值得注意的是這是通過 RESTful API 實現的。這意味著我們所有的操作都是通過可編程訪問的 URL 進行的,無論我們是管理索引還是處理不同類型的數據。
這些查詢通常使用 Elasticsearch 的查詢 DSL 進行,這是一個靈活而強大的系統,它利用 JSON 來定義查詢。重要的是,Elasticsearch 的查詢 DSL 允許進行簡單匹配之外的複雜查詢,包括布爾邏輯、通配符、範圍查詢等。
它非常適合各種用例。我們可以從不同來源收集數據,例如日誌、來自不同系統的指標,甚至是應用程序跟踪數據。借助 Elasticsearch,我們可以將所有這些數據組合成 JSON 文檔,然後輕鬆地實時搜索和檢索信息。
4. 解決現實世界的挑戰
下面是一些示例,說明我們如何與 Elasticsearch 交互。
**4.1.**電子商務搜索
現在,假設我們有一堆與產品客戶評論相關的文檔。借助 Elasticsearch,我們可以快速搜索這些評論中的特定關鍵字或短語,並立即為我們提供相關結果。除了找到完全匹配之外,它還會根據結果的相關性對結果進行排名,確保我們首先收到最重要的信息。
假設我們正在索引大量產品目錄。我們用於查找所有“紅襯衫”的 Elasticsearch 查詢可能如下所示:
curl -X GET "localhost:9200/products/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{ "match": { "color": "red" }},
{ "match": { "product_type": "shirt" }}
]
}
}
}'4.2.地理空間搜索
假設我們正在開發基於位置的應用程序或地圖服務。我們需要搜索地點、計算距離或查找附近的位置。 Elasticsearch 內置了對地理空間數據的支持,讓我們可以毫不費力地存儲和查詢位置信息。無論是尋找最近的咖啡店還是分析地理數據,其地理空間功能都可以更輕鬆地處理基於位置的數據。
不過,這不僅僅是關於搜索。它還提供了一些高級功能。例如,它可以對我們的數據進行複雜的查詢、過濾和聚合。我們甚至可以使用它來可視化和分析我們的數據,幫助我們獲得洞察力並做出明智的決策。
例如,對於基於位置的搜索,要查找特定位置 1 公里半徑範圍內的所有咖啡店,我們的查詢可能如下所示:
curl -X GET "localhost:9200/places/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": {
"match": {
"place_type": "coffee_shop"
}
},
"filter": {
"geo_distance": {
"distance": "1km",
"pin.location": {
"lat": 40.73,
"lon": -74.1
}
}
}
}
}
}'4.3.欺詐識別
信用卡欺詐或在線詐騙等欺詐活動可能是主要的業務問題。
Elasticsearch 可以通過分析大量交易數據來協助欺詐檢測。它可以使用高級分析和機器學習算法識別模式、異常或可疑行為。
除了搜索功能外,它還具有高度可擴展性和容錯性。它可以將我們的數據分佈在多台服務器上,確保即使一台服務器出現故障,我們的數據仍然可以訪問。這使它成為處理具有高數據量的大型應用程序或系統的可靠工具。
4. 生態系統
讓我們繼續討論整個生態系統。如果我們一直在研究 Elasticsearch,我們很可能會偶然發現術語“Elastic Stack”,以前稱為“ELK Stack”。
這個廣泛使用的短語彙集了三種強大的開源工具:Elasticsearch、Logstash 和 Kibana。該術語還包括 Beats,一組輕量級數據托運人。這些組件共同提供了一個全面的搜索、日誌分析和數據可視化解決方案:
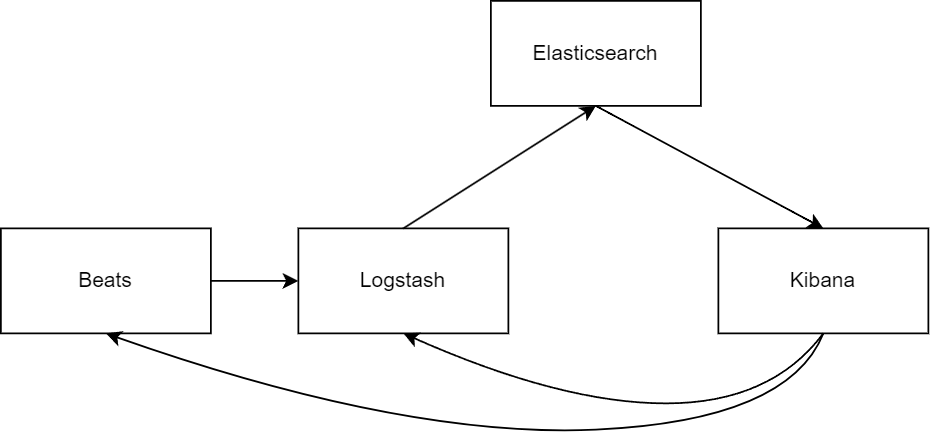
4.1.基巴納
我們可以將其視為一個方便的、網絡友好的界面,讓我們可以與 Elasticsearch 中的數據進行交互。它有點像我們的個人指揮中心,我們可以在這裡深入研究和分析它為我們編制索引的所有重要信息。
借助 Kibana,我們可以創建動態儀表板、圖表、圖形和可視化,它們會在新數據到達時實時更新。它作為我們監控和探索數據流入的主要界面,幫助我們保持最新狀態並毫不費力地獲得洞察力。
現在,讓我們討論如何將數據提取到 Elasticsearch 中。有兩個關鍵組件需要考慮:Logstash 和 Beats。
4.2.日誌存儲
Logstash 是一個開源的服務器端處理管道。它的主要作用是處理三項任務:它接收數據,對其進行一些改造,然後將其存儲在安全的地方。我們可以配置 Logstash 來接收來自各種來源的數據。比如,我們可以格式化數據並使用 SDK 將其直接發送到 Logstash,或者將其與不同的系統集成。
此外,雖然 Logstash 支持 JSON 和 CSV 等各種數據格式,但必須強調的是,它可以使用其廣泛的插件生態系統處理自定義格式。
接收到數據後,Logstash 能夠在數據進入管道之前進行一系列轉換,例如格式化或結構化。完成這些任務後,它將精煉後的數據轉發到最終目的地。出於我們的目的,這些主要目標之一是 Elasticsearch。
4.3.節拍
Beats 是輕量級數據傳送器。它可以被認為是安裝在不同服務器上以收集特定類型數據的代理。無論我們使用的是無服務器架構、文件還是 Windows 服務器,Beats 都是 Logstash 的補充組件。他們有允許與各種服務和系統集成的插件。
Beats 有一個很酷的地方——它有能力將數據直接發送到 Logstash 以進行一些額外的處理和存儲。因此,Beats 充當高效的數據收集器,與 Logstash 攜手合作,確保無縫數據流並集成到我們的 Elasticsearch 環境中。
5.結論
在本文中,我們探索了 Elasticsearch 作為一個強大的搜索和分析引擎,它可以徹底改變我們處理和理解數據的方式。
我們可以在 GitHub 上找到在該項目上實現的一些用例。