認知複雜性及其對代碼的影響
一、概述
在本教程中,我們將了解什麼是認知複雜性以及如何計算該指標。我們將逐步了解增加功能認知複雜性的不同模式和結構。我們將深入研究這些元素,包括循環、條件語句、跳轉到標籤、遞歸、嵌套等等。
之後,我們將討論認知複雜性對代碼可維護性的不利影響。最後,我們將探討一些可以幫助我們減輕這些負面影響的重構技術。
2. 圈複雜度與認知複雜度
有一段時間, cyclomatic complexity是衡量代碼複雜度的唯一方法。結果,出現了一種新的度量標準,使我們能夠更準確地衡量一段代碼的複雜性。雖然它提供了不錯的總體評估,但它確實忽略了一些使代碼更難理解的重要方面。
2.1.圈複雜度
Cyclomatic complexity是最早可以衡量代碼複雜度的指標之一。 Thomas J. McCabe 於 1976 年將其概念化,將函數的圈複雜度定義為相應代碼段內所有自治路徑的數量。
例如,創建五個不同分支的switch語句將導致圈複雜度為 5:
public String tennisScore(int pointsWon) {
switch (pointsWon) {
case 0: return "Love"; // +1
case 1: return "Fifteen"; // +1
case 2: return "Thirty"; // +1
case 3: return "Forty"; // +1
default: throw new IllegalArgumentException(); // +1
}
} // cyclomatic complexity = 5雖然我們可以使用這個指標來量化代碼中不同路徑的數量,但我們無法精確比較不同函數的複雜性。它忽略了關鍵方面,例如多個嵌套級別、跳轉到標籤(如break或continue 、遞歸、複雜的布爾運算以及其他未能適當懲罰的因素。
因此,我們最終會得到客觀上更難理解和維護的函數,但它們的圈複雜度不一定更大。例如, countVowels的圈複雜度也有五個:
public int countVowels(String word) {
int count = 0;
for (String c : word.split("")) { // +1
for(String v: vowels) { // +1
if(c.equalsIgnoreCase(v)) { // +1
count++;
}
}
}
if(count == 0) { // +1
return "does not contain vowels";
}
return "contains %s vowels".formatted(count); // +1
} // cyclomatic complexity = 52.2.認知複雜性
因此,認知複雜度指標由Sonar開發,其主要目標是提供可靠的代碼可理解性度量。其潛在動機是促進重構實踐以實現良好的代碼質量和可讀性。
儘管我們可以配置 SonarQube 等靜態代碼分析器來自動計算代碼的認知複雜度,但讓我們了解一下認知複雜度分數是如何計算的以及考慮了哪些主要原則。
首先,對簡化代碼的結構沒有任何懲罰,使其更具可讀性。例如,我們可以想像提取一個函數或引入一個提前返回來減少代碼的嵌套層次。
其次,線性流程中的每個中斷都會增加認知複雜性。循環、條件語句、try-catch 塊和其他類似的結構正在打破這種線性流,因此,它們會將復雜度提高一級。目標是以線性流程閱讀所有代碼,從上到下,從左到右。
最後,嵌套會導致額外的複雜性損失。因此,如果我們回顧之前的代碼示例,使用 switch 語句的tennisScore函數的認知複雜度將為 1。另一方面, countVowels函數將因嵌套循環而受到嚴重懲罰,導致複雜度級別為 7:
public String countVowels(String word) {
int count = 0;
for (String c : word.split("")) { // +1
for(String v: vowels) { // +2 (nesting level = 1)
if(c.equalsIgnoreCase(v)) { // +3 (nesting level = 2)
count++;
}
}
}
if(count == 0) { // +1
return "does not contain vowels";
}
return "contains %s vowels".formatted(count);
} // cognitive complexity = 73.打破線性流程
正如上一節所述,我們應該能夠以最小的認知複雜度從頭到尾流暢、不間斷地閱讀代碼。然而,一些擾亂代碼自然流程的元素將因此受到懲罰,從而增加複雜性級別。以下結構就是這種情況:
- 語句:
if, ternary operators, switch - 循環:
for, while, do while -
try-catch塊 - 遞歸
- 跳轉到標籤:
continue, break - 邏輯運算符序列
現在,讓我們看一個簡單的方法示例,並嘗試找到使代碼可讀性降低的這些結構:
public String readFile(String path) {
// +1 for the if; +2 for the logical operator sequences ("or" and "not")
String text = null;
if(path == null || path.trim().isEmpty() || !path.endsWith(".txt")) {
return DEFAULT_TEXT;
}
// +1 for the try-catch block
try {
text = "";
// +1 for the loop
for (String line: Files.readAllLines(Path.of(path))) {
// +1 for the if statement
if(line.trim().isEmpty()) {
// +1 for the jump-to label
continue;
}
text+= line;
}
} catch (IOException e) {
// +1 for if statement
if(e instanceof FileNotFoundException) {
log.error("could not read the file, returning the default content..", e);
} else {
throw new RuntimeException(e);
}
}
// +1 for the ternary operator
return text == null ? DEFAULT_TEXT : text;
}就目前而言,該方法的當前結構不允許無縫的線性流程。我們討論的中斷流結構將使認知複雜度增加九級。
4.嵌套斷流結構
每增加一層嵌套範圍,代碼的可讀性就會降低。因此,每個後續的if 、 else 、 catch 、 switch 、 loops 和 lambda 表達式的嵌套級別將有助於認知複雜性的額外 +1 增量。如果我們重新審視前面的例子,我們會發現深度嵌套可能導致複雜性得分額外懲罰的兩個地方:
public String readFile(String path) {
String text = null;
if(path == null || path.trim().isEmpty() || !path.endsWith(".txt")) {
return DEFAULT_TEXT;
}
try {
text = "";
// nesting level is 1
for (String line: Files.readAllLines(Path.of(path))) {
// nesting level is 2 => complexity +1
if(line.trim().isEmpty()) {
continue;
}
text+= line;
}
// nesting level is 1
} catch (IOException e) {
// nesting level is 2 => complexity +1
if(e instanceof FileNotFoundException) {
log.error("could not read the file, returning the default content..", e);
} else {
throw new RuntimeException(e);
}
}
return text == null ? DEFAULT_TEXT : text;
}因此,該方法的認知複雜度為 12,準確地表示了其在可讀性和理解性方面的難度。但是,通過重構,我們可以顯著降低它的認知複雜度,增強它的整體可讀性。我們將在下一節中深入探討此重構過程的細節。
5.重構
我們可以使用一系列重構技術來降低代碼的認知複雜性。讓我們探索每一個,同時強調我們的 IDE 如何促進它們的安全和高效執行。
5.1.提取碼
一種有效的方法涉及提取方法或類,因為它允許我們壓縮代碼而不會招致懲罰。在這種情況下,我們可以利用方法提取來驗證filePath參數,從而提高整體清晰度。
大多數 IDE 將允許您使用簡單的快捷方式或refactoring菜單自動執行此操作。例如,在 IntelliJ 中,我們可以通過突出顯示相應的行並使用Ctrl+Alt+M (或Ctrl+Enter )快捷鍵來提取hasInvalidPath方法:
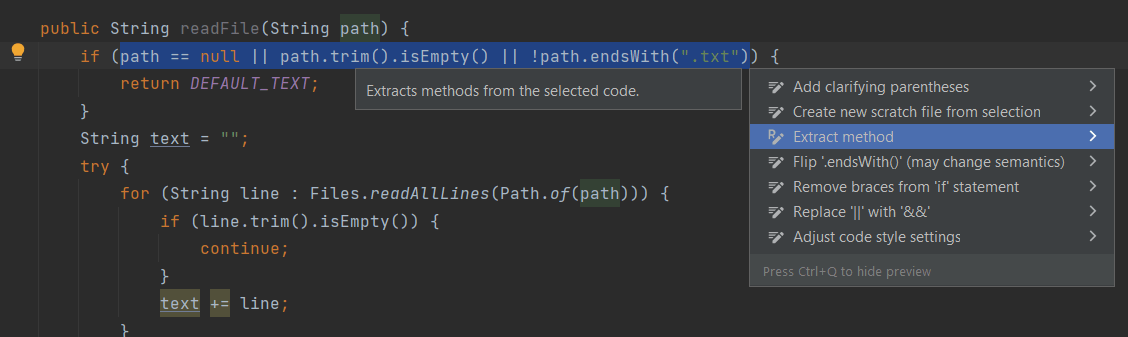
private boolean hasInvalidPath(String path) {
return path == null || path.trim().isEmpty() || !path.endsWith(".txt");
}5.2.反轉條件
根據上下文,有時,反轉簡單的if語句可能是減少代碼嵌套級別的便捷方法。在我們的示例中,我們可以反轉if語句,檢查該行是否為空並避免使用continue關鍵字。再一次,IDE 可以為這個簡單的重構派上用場:在 Intellij 中,我們需要突出顯示 if 並按下Alt+Enter :

5.3.語言特點
我們還應該盡可能利用語言特性來避免中斷流的結構。例如,我們可以使用多個catch塊來不同地處理異常。這將幫助我們防止增加嵌套級別的額外if語句。
5.4.提早歸還
提前返回還可以使方法更短且更易於理解。在這種情況下,提前返回可以幫助我們處理函數末尾的三元運算符。
正如我們所注意到的,我們有機會引入text變量的早期返回,並通過返回DEFAULT_TEXT來處理FileNotFoundException的出現。因此,我們可以通過縮小text變量的範圍來改進代碼,這可以通過將其聲明移至更接近其用法(IntelliJ 中的Alt+M )來實現。
此調整增強了代碼的組織並避免使用null :
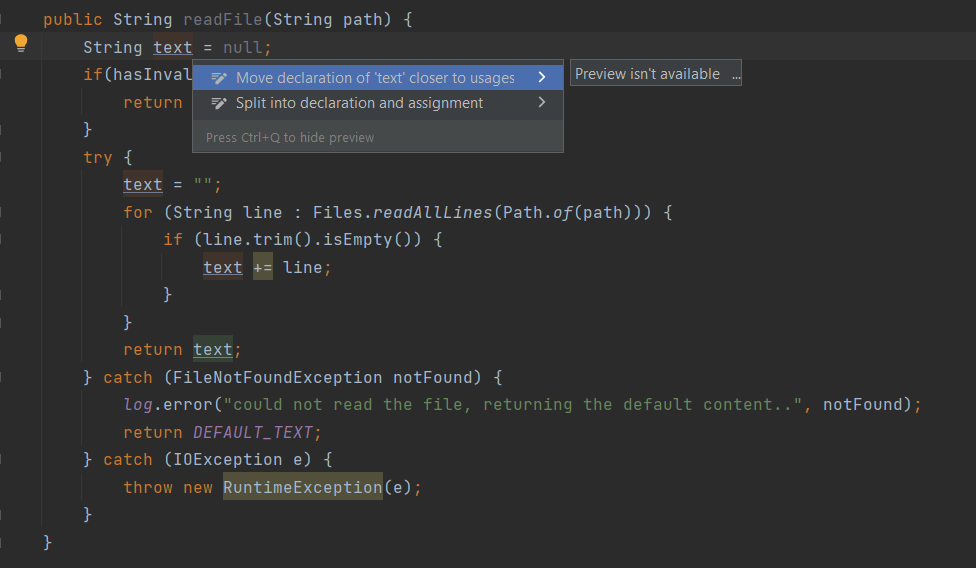
5.5.聲明代碼
最後,聲明式模式通常會降低代碼的嵌套級別和復雜性。例如,Java Streams 可以幫助我們使代碼更加緊湊和全面。讓我們使用Files.lines() —它返回一個Stream<String> —而不是File.readAllLines().此外,我們可以在初始path驗證後立即檢查文件是否存在,因為它們使用相同的返回值。
生成的代碼只會對if語句和執行初始參數驗證的邏輯操作有兩個懲罰:
public String readFile(String path) {
// +1 for the if statement; +1 for the logical operation
if(hasInvalidPath(path) || fileDoesNotExist(path)) {
return DEFAULT_TEXT;
}
try {
return Files.lines(Path.of(path))
.filter(not(line -> line.trim().isEmpty()))
.collect(Collectors.joining(""));
} catch (IOException e) {
throw new RuntimeException(e);
}
}六,結論
Sonar 開發認知複雜性指標是因為需要一種精確的方法來評估代碼的可讀性和可維護性。在本文中,我們介紹了計算函數認知複雜度的過程。
之後,我們檢查了破壞代碼線性流的結構。最後,我們討論了各種重構代碼的技術,這些技術使我們能夠降低函數的認知複雜性。我們使用 IDE 功能重構了一個函數,並將其複雜度分數從eleven降低到two 。