使用 Apache Fury 實現極快的序列化
1. 概述
在本文中,我們將了解Apache Fury ,這是 Apache 軟體基金會下的孵化專案。該庫承諾提供超快的效能、強大的功能和多語言支援。
我們將檢查該專案的一些基本功能,並將其效能與其他框架進行比較。
2. 使用 Apache Fury 進行序列化
序列化是軟體開發中的關鍵過程,它可以實現系統之間的高效資料交換。它允許應用程式共享狀態並透過它進行通訊。
Apache Fury 是一個序列化函式庫,旨在解決現有函式庫和框架的限制。它提供了一個高效能、易於使用的函式庫,用於跨各種程式語言序列化和反序列化資料。旨在高效處理複雜的資料結構和大數據量。 Apache Fury 提供的主要功能包括:
- 高效能:Apache Fury 針對速度進行了最佳化,確保序列化和反序列化過程中的開銷最小。
- 跨語言支援:支援多種程式語言,適用於不同的開發環境(Java/Python/C++/Golang/JavaScript/Rust/Scala/TypeScript)。
- 複雜資料結構:能夠輕鬆處理複雜的資料模型。
- 緊湊序列化:產生緊湊的序列化數據,降低儲存和傳輸成本。
- GraalVM 本機映像支援:GraalVM 本機映像需要 AOT 編譯序列化,且不需要反射/序列化 JSON 設定。
3. 程式碼範例
首先,我們需要將所需的依賴項新增到我們的專案中,以便我們可以開始與 Fury 庫 API 互動:
<dependency>
<groupId>org.apache.fury</groupId>
<artifactId>fury-core</artifactId>
<version>0.5.0</version>
</dependency>第一次嘗試 Fury,讓我們使用不同的資料類型和至少一個嵌套物件來建立一個簡單的結構,以便我們可以模擬實際應用程式中的日常用例。為此,我們需要建立一個UserEvent類別來表示使用者事件的狀態,稍後將對其進行序列化:
public class UserEvent implements Serializable {
private final String userId;
private final String eventType;
private final long timestamp;
private final Address address;
// Constructor and getters
}為了給我們的事件物件引入更多的複雜性,讓我們使用名為Address:
public class Address implements Serializable {
private final String street;
private final String city;
private final String zipCode;
// Constructor and getters
}一個重要的面向是 Fury 不要求類別實作Serializable介面。然而,稍後我們將使用 Java 本機序列化器,它確實需要它。接下來,我們應該啟動 Fury 上下文。
3.1.狂怒設定
現在,我們將了解如何設定 Fury,以便我們可以開始使用它:
class FurySerializationUnitTest {
@Test
void whenUsingFurySerialization_thenGenerateByteOutput() {
Fury fury = Fury.builder()
.withLanguage(Language.JAVA)
.withAsyncCompilation(true)
.build();
fury.register(UserEvent.class);
fury.register(Address.class);
// ...
}在此程式碼片段中,我們建立 Fury 物件並將 Java 定義為要使用的協議,因為它最適合這種情況。不過,如前所述,Fury 支援跨語言序列化(例如使用Language.XLANG ) 。此外,我們將withAsyncCompilation選項設為true ,這允許使用 JIT(Just In Time)在背景編譯序列化器,並且我們的應用程式可以繼續處理其他任務,而無需等待編譯完成。它使用非阻塞編譯來實現這種最佳化。
設定完Fury後,我們需要註冊可能被序列化的類別。這很重要,因為 Fury 可以使用預先產生的模式或元資料來簡化序列化和反序列化過程。這消除了運行時反射的需要,運行時反射可能很慢並且佔用資源。
此外,註冊類別有助於減少與在序列化和反序列化期間動態確定類別結構相關的開銷。這可以縮短處理時間。最後,從安全角度來看,這是相關的,因為我們創建了允許序列化和反序列化的類別的安全列表。
Fury 的註冊表可防止意外類別的無意或惡意序列化,這可能導致反序列化攻擊等安全漏洞。它還降低了利用序列化機製或類別本身中的漏洞的風險。任意或意外的類別的反序列化可能會導致程式碼執行漏洞。
3.2.使用狂怒
現在Fury已經配置完畢,我們可以使用這個物件來執行多個序列化和反序列化操作。它提供了許多 API,可以對序列化過程的細微差別進行低階和高級訪問,但在我們的例子中,我們可以呼叫以下方法:
@Test
void whenUsingFurySerialization_thenGenerateByteOutput() {
//... setup
byte[] serializedData = fury.serialize(event);
UserEvent temp = (UserEvent) fury.deserialize(serializedData);
//...
}我們需要它來使用該程式庫執行這兩個基本操作並利用其巨大潛力。儘管如此,我們如何將它與 Java 中使用的其他著名序列化框架進行比較?接下來,我們將進行一些實驗來進行這樣的比較。
4. 比較 Apache Fury
首先,本教學課程並不打算在 Apache Fury 和其他框架之間執行廣泛的基準測試。話雖如此,為了了解該專案旨在實現的效能類型,讓我們看看不同的程式庫和框架如何針對我們的範例用例執行。為了進行比較,我們使用了 Java Native Serialization、Avro Serialization 和 Protocol Buffers。
為了比較每個框架,我們的測試測量了每個框架序列化和反序列化 100K 事件所需的時間:
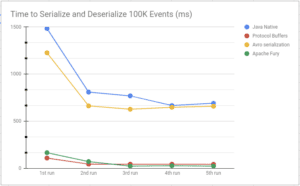
據觀察,Fury 和 Protobuf 在我們的實驗中表現出色。一開始,Protobuf 的表現優於 Fury,但後來,Fury 的表現似乎更好,這很可能是由於 JIT 編譯器的性質所致。然而,正如我們所觀察到的,兩者都表現出色。最後,讓我們來看看此類框架產生的輸出的大小:
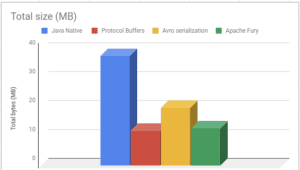
當談到序列化過程的輸出時,Protobuf 似乎具有稍微更好的性能,產生更小的輸出。不過,Fury 和 it 的差距看起來很小,所以我們可以說他們的表現也是不相上下的。
再說一次,這可能並不適用於所有情況。這不是一個廣泛的基準測試,而是基於我們的用例的比較。儘管如此,Apache Fury 提供了出色的性能和簡單易用的功能,這正是該專案的目標。
5. 結論
在本教程中,我們研究了 Fury,這是一個序列化庫,它提供極快的跨語言能力,由 JIT(即時編譯)和零拷貝序列化和反序列化功能提供支援。此外,我們還了解了它與 Java 生態系統中使用的其他知名序列化框架相比的效能。
無論哪個函式庫或框架更快/更有效率,Fury 處理複雜資料結構和提供跨語言支援的能力使其成為需要高速資料處理的現代應用程式的絕佳選擇。透過整合 Apache Fury,開發人員可以確保他們的應用程式以最小的開銷執行序列化和反序列化任務,從而提高整體效率和效能。
與往常一樣,本文中使用的所有程式碼範例都可以在 GitHub 上找到。