Apache Cassandra 中的存儲引擎指南
一、概述
現代數據庫系統通過利用複雜的存儲引擎來寫入和讀取數據,旨在保證一組功能,例如可靠性、一致性、高吞吐量等。
在本教程中,我們將深入研究 Apache Cassandra 使用的存儲引擎的內部結構,該引擎專為寫入繁重的工作負載而設計,同時還保持良好的讀取性能。
2. 對數結構的合併樹(LSMT)
Apache Cassandra 利用基於日誌結構合併樹的兩級數據結構進行存儲。在高層次上,這樣的 LSM 樹中有兩個樹狀組件,一個內存緩存組件 (C 0 ) 和一個磁盤組件 (C 1 ):
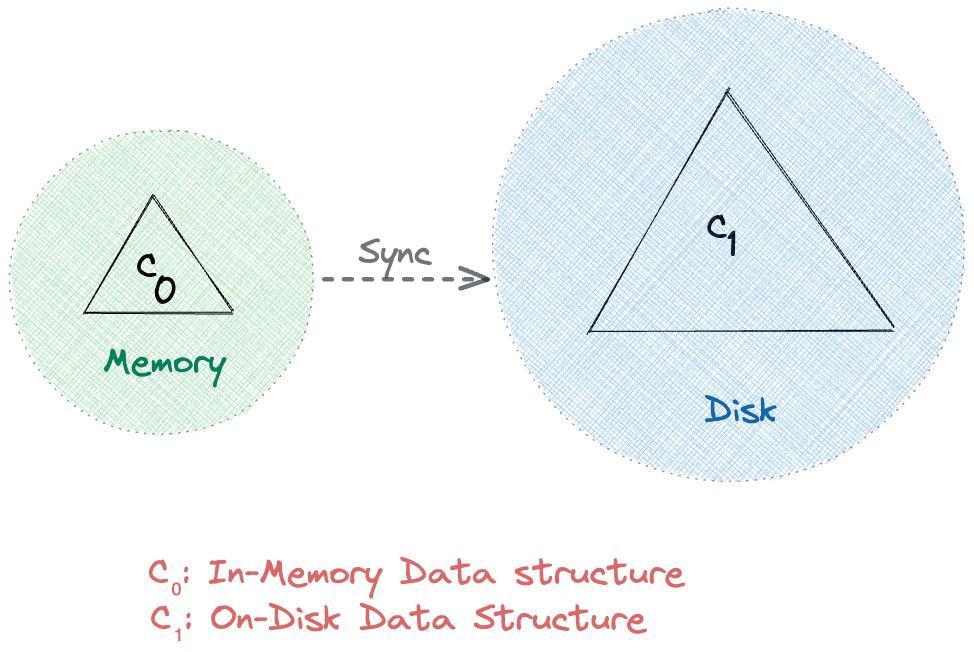
直接從內存讀取和寫入通常比磁盤快。因此,按照設計,所有請求在到達 C 1之前都會先到達 C 0 。此外,同步操作會定期將數據從 C0 持久化到 C1 。因此,它通過減少 I/O 操作來有效地使用網絡帶寬。
在接下來的部分中,我們將詳細了解 Apache Cassandra 中兩級 LSM 樹的 C 0和 C 1數據結構,通常分別稱為 MemTable 和 SSTable。
3. 內存表
顧名思義, MemTable 是一種駐留內存的數據結構,例如具有自平衡二叉搜索樹屬性的紅黑樹。因此,所有的讀寫操作,即搜索、插入、更新和刪除,都可以以 O(log n) 的時間複雜度實現。
作為內存中的可變數據結構,MemTable 使所有寫入順序並允許快速寫入操作。此外,由於物理內存的典型限制,例如容量有限和易失性,我們需要將數據從 MemTable 持久化到磁盤:
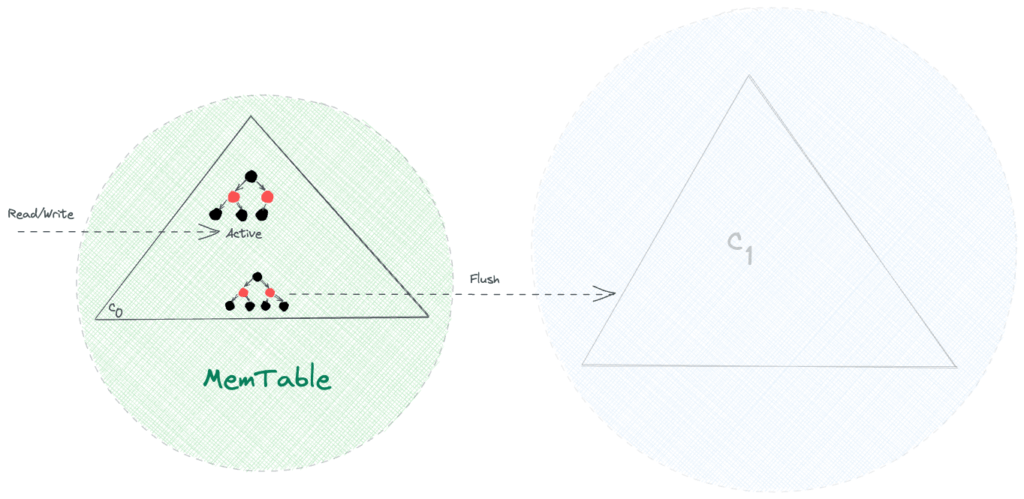
一旦 MemTable 的大小達到閾值,所有的 r/w 請求都會切換到新的 MemTable,而舊的 MemTable 在刷新到磁盤後被丟棄。
到目前為止,一切都很好!我們可以有效地處理大量寫入。但是,如果節點在刷新操作之前崩潰,會發生什麼?好吧,這很簡單——我們會丟失尚未刷新到磁盤的數據。
在下一節中,我們將看到 Apache Cassandra 如何通過使用預寫日誌 (WAL) 的概念來解決這個問題。
4. 提交日誌
Apache Cassandra 推遲了將數據從內存持久保存到磁盤的刷新操作。因此,意外的節點或進程崩潰可能導致數據丟失。
持久性是任何現代數據庫系統的必備能力,Apache Cassandra 也不例外。它通過確保所有寫入在名為 Commit Log 的僅附加文件中持久保存到磁盤上來保證持久性。此後,它使用 MemTable 作為寫路徑中的回寫緩存:
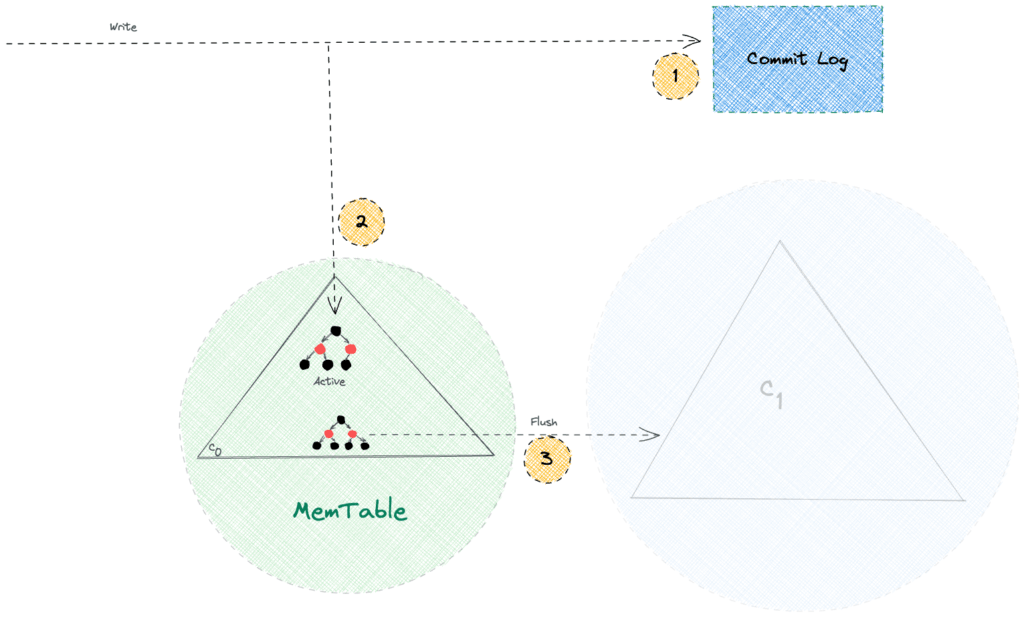
我們必須注意,僅附加操作速度很快,因為它們避免了磁盤上的隨機尋道。因此,Commit Log 在不影響寫入性能的情況下帶來了持久性能力。此外, Apache Cassandra 僅在崩潰恢復場景中引用 Commit Log ,而常規讀取請求不會進入 Commit Log。
5. SSTable
排序字符串表 (SSTable) 是 Apache Cassandra 存儲引擎使用的 LSM 樹的磁盤駐留組件。它的名稱來源於一個類似的數據結構,首先由 Google 的 BigTable 數據庫使用,並表明數據以排序格式提供。一般來說,來自 MemTable 的每個刷新操作都會在 SSTable 中生成一個新的不可變段。
讓我們嘗試可視化 SSTable 在包含有關動物園中飼養的各種動物數量的數據時的外觀:
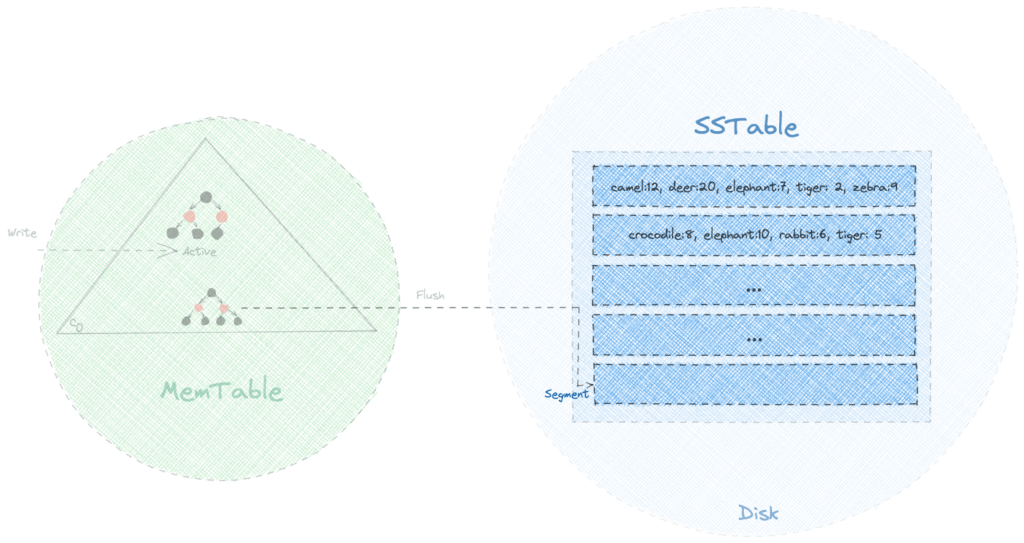
儘管這些段是按鍵排序的,但是,相同的鍵可能存在於多個段中。因此,如果我們要查找特定的鍵,我們需要從最新的段開始搜索,並在找到後立即返回結果。
使用這樣的策略,對最近寫入的鍵的讀取操作會很快。然而,在最壞的情況下,算法的執行時間複雜度為 O( N *log( K )),其中N是段的總數, K是段的大小。由於K是常數,我們可以說整體時間複雜度為 O( N ),效率不高。
在接下來的幾節中,我們將了解 Apache Cassandra 如何優化 SSTable 的讀取操作。
6.稀疏索引
Apache Cassandra 維護一個稀疏索引,以限制在查找鍵時需要掃描的段數。
稀疏索引中的每個條目都包含段的第一個成員,以及它在磁盤上的頁面偏移位置。此外,索引作為 B-Tree 數據結構保存在內存中,因此我們可以在 O(log( K )) 時間複雜度的索引中搜索偏移量。
假設我們要搜索關鍵字“beer”。我們將從搜索稀疏索引中出現在單詞“beer”之前的所有鍵開始。之後,使用偏移值,我們將只查看有限數量的段。在這種情況下,我們將查看第一個鍵是“鱷魚”的第四段:
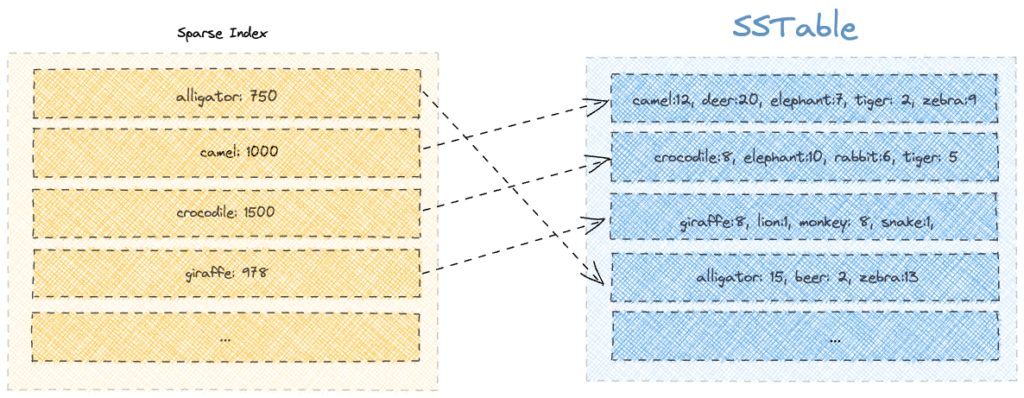
另一方面,如果我們必須搜索諸如“kangaroo”之類的缺失鍵,我們就必須徒勞地查看所有片段。因此,我們意識到使用稀疏索引在有限程度上優化了搜索。
此外,我們應該注意到 SSTable 允許相同的鍵出現在不同的段中。因此,隨著時間的推移,同一個鍵會發生越來越多的更新,從而在稀疏索引中也會產生重複的鍵。
在接下來的部分中,我們將了解 Apache Cassandra 如何在布隆過濾器和壓縮的幫助下解決這兩個問題。
7. 布隆過濾器
Apache Cassandra 使用稱為布隆過濾器的概率數據結構優化讀取查詢。簡而言之,它通過首先使用布隆過濾器對鍵執行成員資格檢查來優化搜索。
因此,通過將布隆過濾器附加到 SSTable 的每個段,我們將為我們的讀取查詢獲得顯著優化,特別是對於段中不存在的鍵:
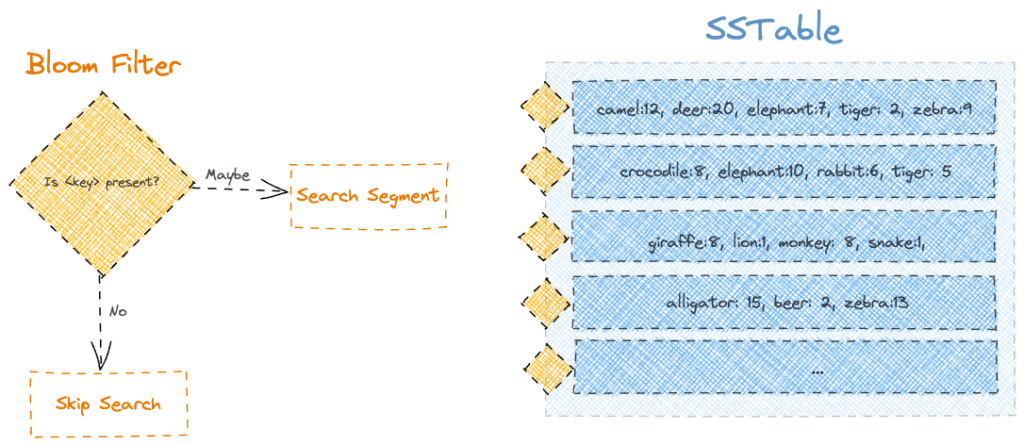
由於布隆過濾器是概率數據結構,我們可以得到“可能”作為響應,即使是缺少鍵也是如此。但是,如果我們得到“否”作為響應,我們可以確定密鑰肯定丟失了。
儘管有它們的局限性,我們可以計劃通過為它們分配更大的存儲空間來提高布隆過濾器的準確性。
8. 壓實
儘管使用了布隆過濾器和稀疏索引,但讀取查詢的性能會隨著時間的推移而下降。這是因為包含不同版本的鍵的段的數量可能會隨著每個 MemTable 刷新操作而增加。
為了解決這個問題,Apache Cassandra 運行了一個後台壓縮過程,將較小的排序段合併為較大的段,同時只保留每個鍵的最新值。因此,壓縮過程具有更快讀取和更少存儲的雙重好處。
讓我們看看在我們現有的 SSTable 上執行一次壓縮會是什麼樣子:
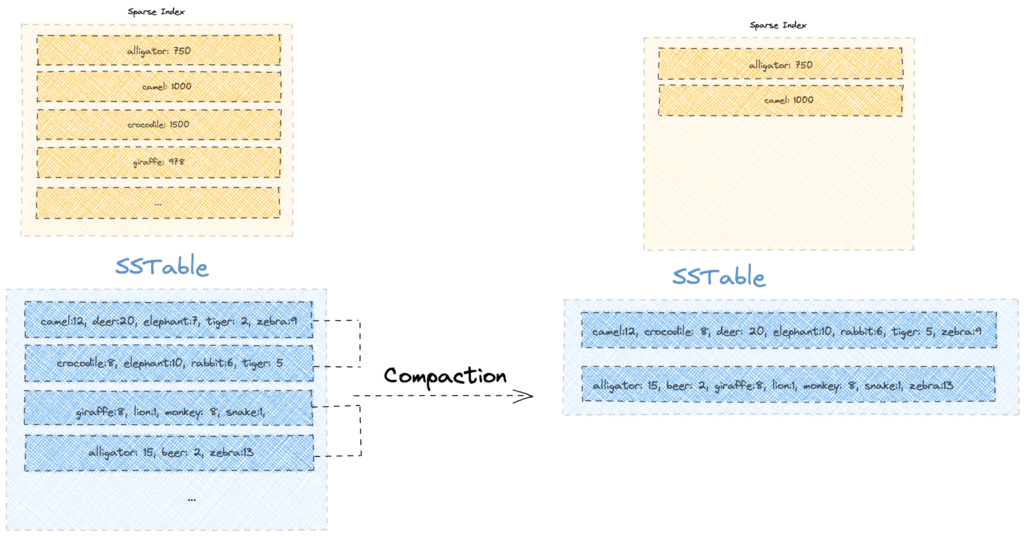
我們注意到壓縮操作通過只保留最新版本回收了一些空間。例如,“elephant”和“tiger”等舊版本的鍵不再存在,從而釋放了磁盤空間。
此外,壓縮過程可以硬刪除鍵。雖然刪除操作會用墓碑標記鍵,但實際刪除會延遲到壓縮。
9. 結論
在本文中,我們探索了 Apache Cassandra 存儲引擎的內部組件。在此過程中,我們了解了 LSM Tree、MemTable 和 SSTable 等高級數據結構概念。此外,我們還學習了一些使用預寫日誌、布隆過濾器、稀疏索引和壓縮的優化技術。